2017年 武汉大学第一届研究生心理健康节-1+1=π 大型学生脱单活动(附带程序)(原创)
这个是我翻看了python入门书籍的第一次软件编程,之前是做硬件的使用Verilog HDL写过430的程序
现在回过头来看这个代码有点不堪直视,其中的数据清洗可以使用更好的方式来进行防止if-else爆炸!!!
思路1:可以直接定义多个字典数据直接解决这个问题;
思路2:使用枚举类型,也可以解决;
思路3:直接先在excel文档中先进行find-exchange;
思路4:设计一个通用替换类,但是有针对不同数据的xml文件来进行处理(spring框架);——2019.06.25
链接:https://pan.baidu.com/s/1Pvf8cXLTmp0USpCXiyd0lQ 提取码:8s8l 
这个活动是由武汉大学 电子信息学院发起, 武汉大学经济与管理学院研究生会、武汉大学城市设计学院研究生会、武汉大学生命科学学院研究生会、武汉大学水利水电学院研究生会、武汉大学法学学院研究生会、武汉大学化学与分子学院研究生会、武汉大学资源与环境学院研究生会、武汉大学国家文化创新研究中心研究生会、武汉大学口腔医学院研究生会、武汉大学政治与公共管理学院研究生会、武汉大学艺术学院研究生会、武汉大学动力与机械学院研究生会合计13个兄弟院系一起举办的大型博硕脱单活动。
武汉大学第一届研究生心理健康节
系列活动之
研究生婚恋心理初探活动总结

指导单位: 武汉大学党委研究生工作部
共青团武汉大学委员会
武汉大学大学生心理健康教育中心
2017年12月

第一届研究生心理节
系列活动之
“研究生婚恋心理初探”
——问卷调查
活动总结
主办单位:武汉大学数学与统计学院研究生会
武汉大学经济与管理学院研究生会
武汉大学城市设计学院研究生会
武汉大学电子信息学院研究生会
武汉大学生命科学学院研究生会
二零一七年十一月
结合院系特色创新交友平台健康心理新模式
武汉大学第一届研究生心理健康节旨在创建和谐校园文化、营造健康心理环境,培育和引导广大研究生形成自尊自信、理性平和、积极向上的健康心态,促进研究生思想道德素质、科学文化素质和心理健康素质协调发展,争做“有理想、有本领、有担当”的新时代的弄潮儿!
本次活动的举办宗旨是“在娱乐中交流感情,在交流中感悟自我”,举办心理健康节的目的在于满足研究生群体的切实需求,所以各研究生会积极带动身边同学参与,切实提高研究生群体的心理健康水平,希望大家做“心里有阳光,脚下有力量”的有志青年!一方面我们要关注自己的心理健康,肯定自我,悦纳自我;另一方面要积极开展心理互助活动,与身边朋友多沟通多交流,在遇到心理问题时主动寻求心理帮助,在他人的帮助下健康成长。最主要目的还是通过联谊这个过程让大家排解心中苦闷、学习心理学知识、提供社会交际能力,更好的完成学校交给的心理知识教育的目的。
此次活动由武汉大学十四个院系的研究生会共同组织的,面向全校研究生,历时近半个月,具有较强的实践性、娱乐性和趣味性。本次活动的筹备工作历时一个月,先后经历了活动形式策划、前期宣传、现场节目排演、相关工作人员培训等环节,所有筹备工作环环相扣,有条不紊的依次展开。活动的“人员报名及合理匹配”板块由武汉大学数学与统计学院、经济与管理学院和城市设计学院负责,这个版块是活动的开始部分,所以对之后版块活动的举办效果有很大的影响,所以我们对该板块进行了详细的讨论分析,尽可能考虑到所有细节。同时结合我们三个院系不同的专业特点,以不同的角度来分析这个版块,以此达到针对全校研究生的活动预期效果。
下面我们将从问卷制作、问卷报名、人员匹配、结果发布和调查结果统计分析五个方面来总结汇报我们三个学院在承办武汉大学第一届研究生心理健康节系列活动中“人员报名及合理匹配”板块所进行的工作。
第一章 问卷制作
在经过第一次十四个院系讨论,确定我们三个院系负责人员报名及匹配这一板块之后,我们就开始了紧锣密鼓的筹划构思,因为我们的版块是这个活动的第一部分,所以我们要尽快做出报名问卷,同时考虑之后人员匹配的问题。
在正式制作问卷之前,我们先进行了前期调研及查询资料环节,寻找科学依据以及理论支撑,尽可能的让我们的问卷有科学的依据。在前期工作准备好之后,我们就开始了问卷的制作。在问卷设置中,我们的要求是尽可能的把参加人员的个人情况以及对未来伴侣的期望呈现出来,但同时也要注意对参加人员隐私的挖掘程度,因为涉及到过多的个人隐私,可能会让想报名参加的同学有所顾虑。
这次活动我们以网络报名为主,使用工具为“问卷星”。经过我们对问卷的反复的修改,权衡各方面的利弊,最终确定了一套问卷。这套问卷一共包含34个题目,分为个人基本资料、对未来伴侣的基本要求、反应个人三观等三个方面的问题。在个人基础资料方面有姓名、联系方式、院系专业以及身高体重等问题,同时为了增加报名的准确性以及提高参加者的重视度,我们要求参加者必须上传一张生活照作为参考。在对未来伴侣的基本要求方面,设置了年级、身高体重、星座、家乡等题目,作为之后人员匹配的重要依据。在反应个人三观的问题设置中,我们选取了一些生活中常见的问题,比如说对待异性闺蜜的问题,这些问题在一定程度上反应了参加者的人生观价值观,对之后的情侣生活会有很大的影响。在问卷制作人员中有男生也有女生,有文科类专业的学生,也有理工科专业的学生,也有不同年级的学生,综合了多个角度来对这次问卷进行设置。
在问卷的设置中,我们尽量考虑了所有的方面,但由于我们第一次举办这类活动,肯定会存在一些问题,也没办法把所有参加者的所有情况调查清楚,但总的来说,这次问卷的制作满足了之后活动的要求。



问卷中的部分问题
第二章 活动问卷报名
在问卷制作完成之后,我们工作人员对其进行的若干次的测试,在确保没问题了之后,我们就把问卷报名的二维码和网址发给了负责宣传的工作人员,以此开始了本次活动的正式报名。
报名从11月5号正式开始,在刚刚开始的短时间内就有几十人报名参加,这让我们感到很欣慰,我们的活动有了很好的开始。在之后的几天,报名人数继续增加,直到8号凌晨截止的时候,一共有六百名左右的同学报名,这远远超出我们的预期。在报名截止之后,应广大同学们的要求,由于部分同学错过了报名,我们决定在在8号中午问卷重新开启,最终的报名人数达到681人,这远远大于我们之前160人的预期,在感到高兴的同时也为之后的匹配工作感到担忧。在报名截止之后,依然有很多同学想要报名但错过了报名时间,我们考虑到之后人员匹配的时间紧张,所以就没有继续开通问卷,这一点我们感到很遗憾。


活动报名宣传及报名问卷二维码
第三章 人员匹配
在报名结束之后,我们就紧锣密鼓的开始了最重要的环节:人员匹配。这个环节要根据参加者提供的个人信息来进行一对一的配对,尽可能的将两个合适的人匹配到一起,所以说这一环节对之后的活动影响很大。
在此要感谢电子信息学院的周健康同学帮忙做的匹配程序,极大程度上减少了我们的工作量。在用程序匹配之前,我们先将一部分有特殊要求的参加者提取出来(由于要求较多,这部分人员无法用程序匹配),进行人工匹配。我们三个院系的工作人员开始了紧张细致的匹配工作,因为要考虑到所有参加者的所有要求,所以这一部分的工作量很大,工作人员很辛苦。
在人工匹配结束之后,就将剩下的进行程序匹配,到最后,所有的参加者匹配结束。但是由于报名人数女生比男生多,所以不可避免的有些女生没有匹配到对象。
第四章 结果发布
在匹配结果出来之后,我们就立马将结果进行公布,但考虑到参加者的隐私,我们决定对参加的所有人一个一个的单独通知,在这里要感谢电子信息学院和生命科学学院的帮忙,才能让结果短时间内通知到每个人。在对个人的通知中包括匹配对象的姓名联系方式,并没有把其他的个人情况通知给对方,这是对双方隐私的尊重。
然而在结果发布之后,出现了很多问题。有些同学不确定自己第一次有没有报名成功,所以报名了两次,但是在问卷星中无法对这种情况进行筛选,所以在匹配结果中有重复的现象;还有些同学在报名信息中将性别填错了,所以就出现了两个男生或者两个女生匹配到了一起。针对以上这些情况,我们打算将有问题的数据汇总,进行第二次的人工匹配。在第二次结果发布之后,又将有问题的进行了第三次人工匹配,在这次匹配中,我们将之前落选的数据也加入进去,同时陆续有若干男生想要报名,所以在最后的结果中,基本上每个人都有了匹配对象。在这次结果发布之后,基本上没有发生什么问题。
第五章 调查结果统计分析
由于我们设计的活动问卷主要分为“个人基本信息”、“对理想型的基本要求”以及“对一些常见情侣问题的看法”这三个部分,所以我们的结果统计也分为这三个部分展开。我们问卷一共有34道题,除去姓名、手机号、照片的等一些无需或无法统计的问题,我们将对其余22道题进行分析。
第一部分是调查个人基本信息,一共是10题(2、3、6、10、16、18、22、24、25、33题);第二部分是调查对理想型的基本要求,一共5题(第7、11、17、19、23题);第三部分是调查对一些常见情侣问题的看法,一共7题(26、27、28、29、30、31、32题)。对每个具体问题的描述,可详见统计结果或者本文档最后的附件。
下面开始对此次活动所有问卷结果的进行统计分析:
【第一部分:个人基本信息】
第2题 性别: [单选题]
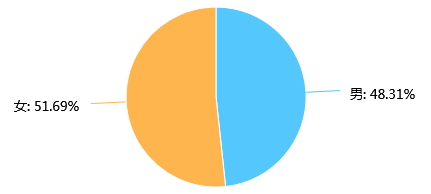
从这道题的性别的图表信息可以看出,本次参与活动的人员性别比例上是比较均衡的,男女几乎各自接近于50%。
第3题 家乡: [单选题]
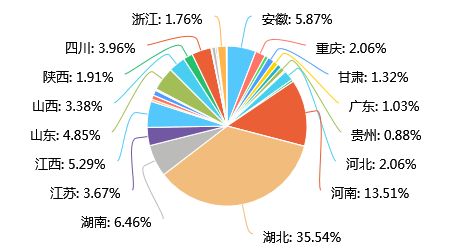
就该题的家乡信息而言,湖北省的研究生占了大多数,其次是河南、湖南、安徽等一些邻省,这显然这是由于武汉大学地处湖北省,本省和邻省生源相对多的原因导致的。
第6题 学部: [单选题]
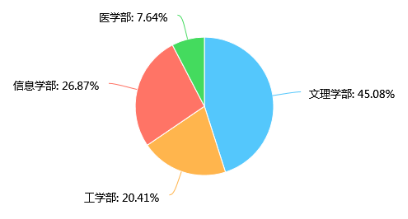
从本题的学部图表信息可以看出,文理学部的学生最多,医学部学生最少。这主要是由于主办和协办本次活动的院系集中于文理学部,所以该学部的学生对本次活动的参与积极性相对更高。而医学部由于距离的问题,活动参与者明显低于其他跟学部;
第10题 年级: [单选题]
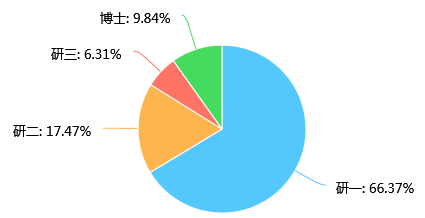
对参与人员的年级情况进行分析,我们会发现,研一学生超过了总人数的一半,这主要是因为新生更乐忠于也更愿意尝试一些活动,相对于高年级学生正面临着就业或者论文的巨大压力,他们更有精力去关心自己的情感生活;博士比例虽然低,但从问卷的填写完整程度上考察,我们会发现很多博士虽然学术繁忙,也愿意尝试这些活动认真填写问卷,帮助自己去需找另一半,可见此类型活动的意义。也希望此类型的活动可以更完善,更好的发挥它的作用。
第16题 身高: [单选题]

第18题 体重: [单选题]

综合对16和18题的身高、体重的图表进行分析,我们发现女生160-165身高段的人数是最多的,男生在170-175身高段最多,居多人的身材还是处于适中的范围。
第22题 自己的性格标签: [多选题]

第22题是是以九型人格为基础,让参与人员进行选择。我们会发现,更多的人认为自己属于成就型实干者、智慧型观察者这两种类型,武汉大学的学生居多是认可自己的才干和能力,或者说在自己的认知中,不否认自己不属于这两种类型。
第24题 恋爱次数 [单选题]

从第24题对恋爱次数的调查,我们会发现,谈过一次恋爱和没谈过恋爱的学生占据了大多数,这可能是由于活动性质导致的。这两方面的人相对于其他人可能还有更大的热情或者更迫切的期望去寻找自己的另一半。
第25题 最近一次恋爱持续时间: [单选题]
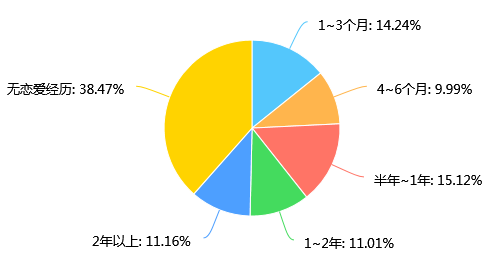
对第25题对最近一次恋爱持续时间分析,我们发现无恋爱经历占了大多数,这从上一题调查结果也可以相应得到;另一方面,我们发现大多数的学生恋爱持续时间是在1年之内的,这其中原因比较复杂,是需要继续调查统计才可以有结论的。
第33题 日常除了睡觉吃饭学术占用时间最多的活动 [单选题]
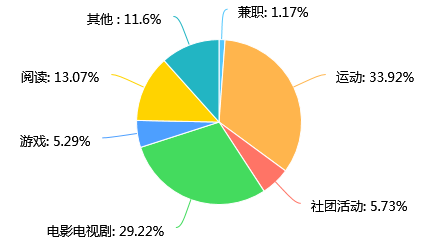
第33题是调查参与人员日常活动的情况,我们发现运动和电影电视剧这类文娱活动是硕士和博士研究生闲暇活动的主要选择;其次是阅读。而社团活动和游戏是最少,这可能与他们繁重的学业压力有关。
【第二部分 对理想型的基本要求】
第7题 理想型学部: [单选题]

第11题 理想型年级: [单选题]

综合第7题和第11题,我们会发现,大多数的参与人员并不受学部和年级的束缚,并不把这两个条件作为他们选择理想型的因素。并且在匹配过程中,我们会发现,更多的女生愿意找更高年级的男生,甚至出现研一的女生要求博士学历的男生;而对男生而言,男生居多希望理想型女生可以和自己是同年级或者低年级的。
第17题 理想型身高范围: [单选题]

从第17题的统计结果我们会发现,大家对理想型身高选择无所谓的人数比例明显低于其他因素,也就是说,身高这一因素在大家需找理想型的时候是比较看中的。而且男生更喜欢160-165阶段的女生,而女生更喜欢175-180阶段的男生。这种情况与第一部分对个人身高调查情况是矛盾的,因为身高位于170-175的男生人数是远远多于175-180身高段的男生!
第19题 理想型体重范围: [单选题]

第19题可以看出,选择无所谓的人并不是很大比例的,大多数人还是在意理想型的体型的,并且大多数人喜欢适中的,就是符合大众审美来选择自己的理想型。
第23题 理想型的性格标签: [多选题]
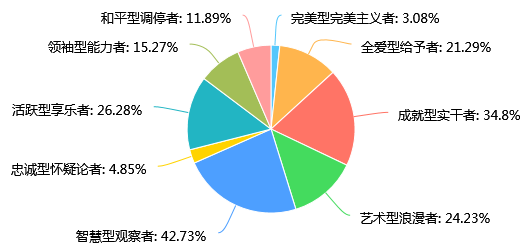
从23题的理想型性格标签调查可以看出,大多数人喜欢成就型实干者和智慧型观察者这两种类型的人,这也符合第一部分中个人性格的调查结果,即这两种类型的人是很受欢迎的。大多数人认为自己属于这两类型,也希望理想型可以是这两类型的。
【第三部分 常见情侣问题的看法调查】
第26题 你恋爱的最重要的主观原因: [多选题]
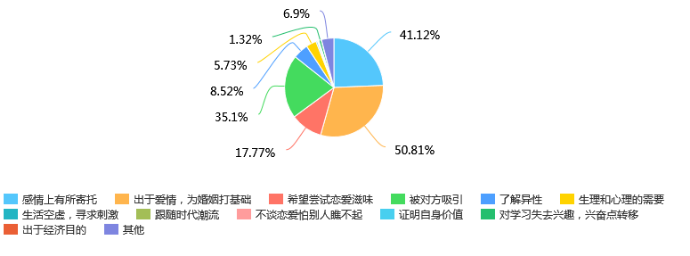
第26题考查的是大家选择恋爱的原因,我们会发现大多数的人选择的是“出于爱情、为婚姻打基础”、“感情上有所寄托”以及“被对方吸引”,这些理由都是积极向上的,但也有一定比例的人人选择了“希望尝试恋爱滋味”、“了解异性”“生理和心理的需要”这些原因。
第27题 你的择偶标准是: [多选题]
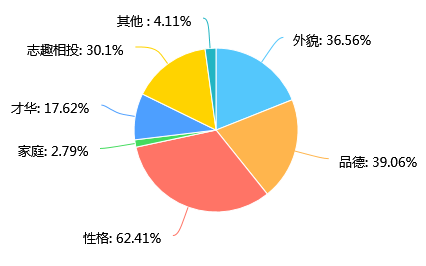
第27题考查的是大家的择偶标准,调查发现大家更看重的是性格这一项。除此之外,品德、外貌和志趣相投这三个也是很重要的择偶标准。
第28题 你对大学生婚前性行为的态度是: [单选题]
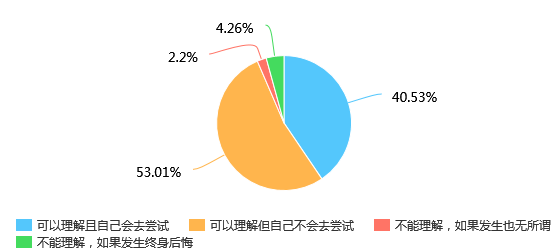
第28题是考察大家对婚前性行为的态度,我们会发现超过一半左右的人选择“可以理解但自己不会去尝试”,其次很多人选择的是“可以理解且自己会去尝试”。由此可见,在这个越来越开放的社会中大家对对方的婚前性行为是可以理解和接受的,但是受到我们传统观念的影响,更多的人是不会选择自己尝试的。
第29题 你所期待的理想爱情是什么样的: [单选题]
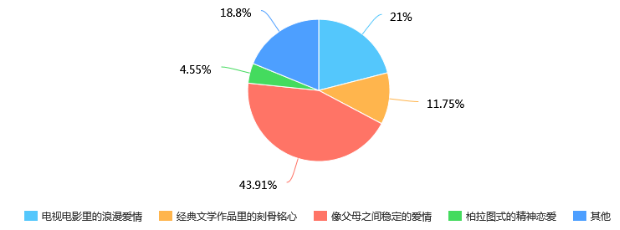
第29题考查的是大家理想的爱情,我们会发现大多数人期待的是像父母之间稳定的爱情,这很符合前面第26题的调查结果,居多人选择恋爱是出于“出于爱情、为婚姻打基础”。由此可见,居多数人对爱情抱着认真的态度,喜欢稳定的状态。
第30题 你认为你和你的“另一半”维持感情,重要的是 [单选题]
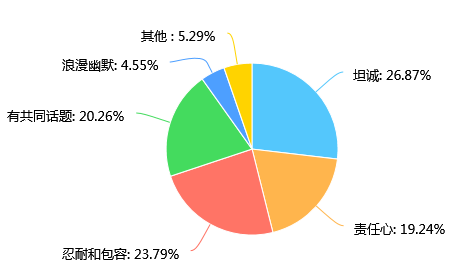
第30题考查的是大家认为维持感情最重要的因素是什么,可以发现“坦诚”、“忍耐和包容”、“有共同话题”和“责任心”是大多数人认为对感情维持很重要的因素。
第31题 你对异性朋友的看法是 [单选题]
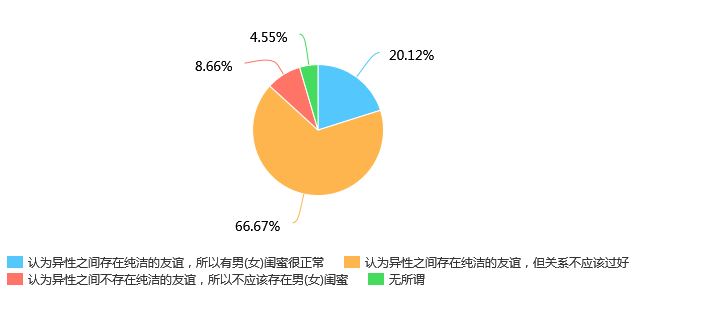
第31题考察的是大家异性闺蜜的看法,可以发现超过一半的人是认为“异性之间存在纯洁的友谊,但关系不应该过好”,可见在恋爱时与异性朋友保持合理的关系是大家在意的问题,也是居多数人认可的。
第32题 介不介意男(女)朋友在朋友圈晒自拍的行为 [单选题]

第32题考查的是大家对现如今恋人发朋友圈晒自拍的看法,我们会发现,介意的比例还是很小的,大家可以接受频率不高的晒照行为,不介意的比例也是很高的。可见这可能不会是造成情感危机的普遍因素。
活动总结
在这次活动中,我们十四个院系通力合作,虽然过程中不可避免的有些瑕疵,但是结果是美好的,我们的努力付出没有白费。在最后的闭幕晚会中看到已经有同学确定了情侣关系,我们感到很欣慰。
在“人员报名和人员匹配”这一板块中,我们三个院系都在很努力的想要把活动举办的很完美,这不仅是对参加者负责,也是对我们自己负责。在其中出现的一些问题,我们也及时地采取补救措施,确保活动的正常进行。同时我们也对这些问题进行了反思,希望对之后的活动有一些借鉴经验。
这次活动的成功举办,为之后的类似活动提供了模板案例,希望之后会有更多的这种活动,来促进不同院系不同年级的相互交流。
【附件 本次活动调查问卷】

第一届研究生心理节
系列活动之
“研究生婚恋心理初探”
——线下互动
活动总结
主办单位:武汉大学水利水电学院研究生会
武汉大学法学学院研究生会
武汉大学化学与分子学院研究生会
二零一七年十一月
活动背景
为增强研究生心理素质,武汉大学校团委主办第一届心理健康节知识普及活动,其中研究生感情问题为重点突破口,特此电子信息学院联合14院系承办了研究生婚恋心理初探系列活动。同时也增进广大研究生群体对自身心理的认知,拓宽心理健康知识面,能够做到在日后的学习工作生活中及时调整自身心态,遇到问题明白咨询途径,理性对待。
而水利水电学院研究生会作为本次活动线下活动支线的主办方,联合化学与分子科学学院、法学院研究生会,通过定向越野的形式促进配对情侣之间的感情,同时在紧张的学习生活中放松一下自我,真正体会身为研究生科研感情两不误的状态。
本次线下活动的举办宗旨是“在娱乐中交流感情,在交流中放松自我”,以此为契机,时刻关注广大学生在日常生活中对待感情的态度,工科生也要懂生活,聊文艺;文科生也要多理性,为自己将来走出象牙塔迈向社会生活奠下基石。
活动筹备
为使同学们在紧张的学习氛围下有一个健康的心理状态,也恰逢双十一来临之际,于是在线下活动水院分点活动选取了“仙人指路”这个游戏,不仅能加深合作二人的协调能力,而且能增进组队cp间的感情,话说感情是离不了交流的,这个游戏能大大缓解二人初识的紧张感,也会对这个活动的举办有着正面积极的意义。

预赛报名
此次活动采取线上预报名的形式,后台工作人员(数院、城设院)通过数据库将异性二人进行配对,之后在参加活动这天到摆点处两个人填写活动报名表即可开始紧张有趣的分点活动啦。
活动形式
水院点,仙人指路
游戏规则:情侣二人中一人被蒙住双眼,另一人负责在起点指引道路,选手蒙眼后,由工作人员将每组的两把椅子摆放到蒙眼选手前进的路上。只能通过语言沟通,不能搀扶。被蒙住双眼的必须按照比赛设定的路线,绕过路障(凳子)取到指定物品并原路返回。如在行进过程中碰到路障,每碰一次路障时间加五秒,在最后计算时间时计入总时间。比赛以用时最短为获胜,依次排名。过关后完成合影,即可获得通关证明与小礼品。
地点:水工结构楼旁世纪广场
物资:指定物品(苹果、橘子类),椅子(租用),小礼品(棒棒糖),海报一张、横幅一条,纸张若干
人数:计时X1,主持人X1,核对X1,维持秩序X1,视情况安排一组或几组,排队时间计入总时长
活动负责人:王健野
化学院点,你画我猜
由男生表演女生来猜词语,男生各种惟妙惟肖的表演逗得现场围观群众捧腹大笑,这类游戏十分考验cp组合的默契,有的小组最短用时居然五个只用了49s,令人十分怀疑这两人不莫不是恋爱很久了的真正情侣。同时,也有部分搭档直呼玩的不过瘾,但由于各项活动时间限制只能工作人员只能表示抱歉,现场一片欢笑声与运动场上的欢呼声不相上下!
地点:桂园食堂
活动负责人:童慧敏
法学院点,识面识心
法学院负责湖滨任务点,并成功利用 stroop效应(利用的刺激材料在颜色和意义上相矛盾,要求被试说出字的颜色)构造了“识面知心”游戏。该游戏通过让契约情侣共同参加游戏、互相帮助理解游戏规则、讨论游戏分工等方式,拉进了契约情侣之间的距离。不时 传出的阵阵欢声笑语还吸引了不少“围观群众”,达到了一定的心理压力疏导与放松效果。分点活动结束后,我们完成了线下活动成绩的录入与前三名获奖者的筛选,并制作了最快完 成游戏前八名契约情侣的奖品。
地点:湖滨食堂
活动展示
这次活动的成功举办离不开各学院的积极宣传和参与,同时也为下一届心理健康节提供了很好的素材模板,但也有一些细节问题需要得到重视,比如一开始校研会没有协调好场地的问题,让活动开展磕磕绊绊,场地得不到批准中途不得不停止活动,再有由于参加活动院系过多,整个系统过于庞大冗杂,人员调动起来心有余而力不足,可以给下一届活动一个建议,减少参加院会,有针对有目的地去联合院系,这样活动积极性会变高,参与人员也不至于像这次线下报名远少于线上报名的情况出现。总体而言,这次活动成功而有意义,真的会有几对cp因为这个活动而找到人生的另一半,那我们这个活动也是有了它最好的意义了~
活动总结
武汉大学第一届研究生心理健康节之“研究生婚恋心理初探”线下活动的举办十分成功,从最初三院联合敲定活动举办方案,制定活动规格,细化活动过程,到最后的紧张筹备和成功举办,此次心理健康节为全校研究生同学开创了一个心里交流趣味类的新平台。不仅和相关学院借此活动建立了良好的沟通渠道,而且听到了全校研究生来自不同专业对异性加强交流的心声,得到了一致好评。
虽然活动已经结束了,但是我们希望,通过这次的活动,所有参与者都能收获一份满满的幸福,怀揣一份满满的喜悦。我们期待着大家能在参与了我们的活动之后,能够更加热爱武汉大学这个充满爱的大家庭,促进两性之间的交流,同时在紧张的科研之外还有很多生活的美好细节等着我们去发现,在自己的校园文化生活添上多彩的一笔。
第一届研究生心理节
系列活动之
“研究生婚恋心理初探”
——心理电影赏析
活动总结
主办单位:武汉大学艺术学院研究生会
武汉大学动力与机械学院研究生会
二零一七年十一月
结合院系特色创新交友平台健康心理新模式
武汉大学第一届研究生心理健康节旨在创建和谐校园文化、营造健康心理环境,培育和引导广大研究生形成自尊自信、理性平和、积极向上的健康心态,促进研究生思想道德素质、科学文化素质和心理健康素质协调发展,争做“有理想、有本领、有担当”的新时代的弄潮儿!
本次活动的举办宗旨是“在娱乐中交流感情,在交流中感悟自我”,举办心理健康节的目的在于满足研究生群体的切实需求,所以各研究生会积极带动身边同学参与,切实提高研究生群体的心理健康水平,希望大家做“心里有阳光,脚下有力量”的有志青年!一方面我们要关注自己的心理健康,肯定自我,悦纳自我;另一方面要积极开展心理互助活动,与身边朋友多沟通多交流,在遇到心理问题时主动寻求心理帮助,在他人的帮助下健康成长。最主要目的还是通过联谊这个过程让大家排解心中苦闷、学习心理学知识、提供社会交际能力,更好的完成学校交给的心理知识教育的目的。
此次活动由武汉大学十四个院系的研究生会共同组织的,面向全院研究生,历时近半个月,具有较强的实践性、娱乐性和趣味性。本次活动的筹备工作历时一个月,先后经历了活动形式策划、前期宣传、现场节目排演、相关工作人员培训等环节,所有筹备工作环环相扣,有条不紊的依次展开。在“心理电影赏析”板块我们有意选择了与恋爱题材相关的电影内容,针对这个特点进行宣传。本次活动的成功举办,能够丰富学生们的校园文化生活,引导学生们在恋爱这门必修课中更加积极的展现自己,以更加饱满的热情对待学习、爱情、生活。同时,这项活动也结合了我院的专业特色,展现了艺术学院的风采,体现了艺术学院和动力与机械学院健康的、活泼的、趣味的、生动的院系文化。
下面我们将从三大部分来总结汇报我院和动力与机械学院在承办武汉大学第一届研究生心理健康节系列活动中“心理电影赏析”板块所进行的工作。第一部分是将向大家详细展示我们的筹备工作细节,第二部分是活动现场的风采展示,尾声部分我们将针对活动过程中暴露出的问题做出详细的反思,对我们的优点进行总结归纳,为下一届活动的成功举办提供一个完备的参考方案。
第一章 活动筹备
依稀记得当初我们研会第一次开会讨论的场景,大家在热闹的讨论中多次出现“院系联谊”、“院系沟通”等话题。也确实是这样的,由于各院系的课程、活动等等大都是各个小集体内部开展,所以我们学校的各个院系学生联系比想象中要少的多。
正值“武汉大学第一届研究生心理健康节”,也为了增强院系之间联谊,帮助同学们的心理问题解答和心理知识普及,以及提升社交能力。我们中一个院系发出了院系间联谊的活动设想,各个院系云集响应,由此开启了由我们14个院系共同举办的“研究生婚恋心理初探活动”,艺术学院与动力与机械学院的研究生会积极申办活动中的“心理电影赏析板块”。主要目的还是通过联谊这个过程让大家排解心中苦闷、学习心理学知识、提供社会交际能力,更好的完成学校交给的心理知识教育的目的。
(一)积极开展筹备工作
在艺术学院研会心理部初步制定方案后,与动力与机械学院的研会负责同学和本院研会同学召开了讨论会议,详细布置了研会各部门的工作任务,并将每部分任务按职能的不同细化安排到了各个部门,各部门通力合作,为活动做好准备,以求高效地完成各项工作。
会议之后,各项工作有序开展,主持、道具、场地、工作人员等都按照预先排布的时间表一一确定。为了对活动现场可能出现的各种问题进行应对,研会全体同仁提前一天进行了彩排,发现了很多问题也及时做出了调整。艺术学院研会的同学提前准备本次观影活动的高清电影资源和实体物资。
(二)步步为营广泛宣传
在做好与各院系密切联系的同时,宣传工作也已经紧锣密鼓的展开。动力与机械学院研会的同学经历了制定了精美完善的宣传推文。在活动启动之后,我院与动力机械学院积极通过院研会官方微信平台定期发送推送,同时紧跟时代特色,通过学生利用较多的 QQ、微信、微博等方式同步扩大影响力。

 利用微信推文进行活动宣传
利用微信推文进行活动宣传
第二章 活动现场展示
经历了紧锣密鼓的前期筹备工作,“研究生婚恋心理初探”之心理电影赏析缓缓拉开了帷幕。
参加活动的的对象主要来自前期配对的契约情侣,也面向全校研究生同学开放。艺术学院的同学负责,场地和设备支持及现场主持讲解,动力与机械学院的同学则负责场地布置,横幅张贴等工作。
电影赏析现场布置
为了确保前来观看的同学们更熟悉活动流程,艺术学院研究生会的工作人员现场给大家讲解活动流程,让大家更深刻的了解放送电影的意义,更明白我们此次活动的意义。
同时,活动前的彩排和演练还加深了艺术与动机两个研会之间的团结协作能力,及时发现准备工作的中不足之处,对活动的顺利开展起到了宝贵的支持作用。
活动彩排现场
11月12日晚 6 点半,“研究生婚恋心理初探”之心理电影赏析“LOVE”正式开始。首先是艺术学院研会主席介绍活动流程。然后开始了活动的第一环节“你画我猜”。增进了契约情侣的默契。第一部分开始后,会场灯光暗下,播放了恋爱心理电影“LOVE”,最后,由艺术学院电影学专业的研究生同大家共同分析,赏析电影中的恋爱观。电影“LOVE”诙谐风趣,轻松灵动,现场还准备了小零食供大家以更轻松的状态观看电影,给在场人员带来一场视觉和听觉的享受盛宴。本次活动妙趣横生、欢笑连连,在大家的欢笑声中,第一届研究生心理健 康节系列活动之“研究生婚恋心理初探”——心理电影赏析活动圆满结束。
契约情侣的“你画我猜”环节
欢声笑语的观后互动现场
活动参与人员与工作人员全家福
第六章 活动总结
从最初的敲定活动形式,制定活动内容,到后来的筹备工作和成功举办,本次电影放映活动为全校以及艺术学院和动力与机械学院的的全体同学开创了一个心理健康交流的新平台。
相较于以往心理健康活动的讲座式单调普及,本次“研究生婚恋心理初探”——心理电影赏析的活动形式更加新颖。对于在读的研究生而言,是一次不可多得锻炼自己恋爱心理的机会。我们认为本次活动让大家在走下课堂,走出实验室之余,让身心都得到了完美的放松。从影视元素到恋爱哲学,育心理健康学习于娱乐。
当然,在经历了成功举办了活动的背后,我们也进行了深刻的反思。虽然曾详细推敲每一个环节的设计,但终究还是在活动过程中出现了一些意想不到的情况。例如在电影放映环节,由于音频与视频中间差了一秒钟导致出现了一分钟的音画不同步,影响了参与者的观感,使场面出现了小尴尬,虽然下面工作人员及时解决了问题,仍然值得我们在问题中反思,为下一次举办活动提供经验,争取把将心理电影放映活动,扩展到全校,吸引更多的同学参与进来,丰富更多的同学的校园文化生活。
虽然活动已经结束了,但是我们希望,通过这次的活动,所有参与者都能收获一份爱,怀揣一份满满的喜悦。我们期待着大家能在参与了我们的活动之后,对我们的心理健康有更深层次的理解,促进恋爱心理的健康发展,也为自己的校园爱情生活添上一笔宝贵的财富!

第一届研究生心理健 康节系列活动之
“研究生婚恋心理初探”
——恋爱心理学美文征集
活动总结
主办单位:武汉大学资源与环境学院研究生会
武汉大学国家文化创新研究中心研究生会
武汉大学口腔医学院研究生会
武汉大学政治与公共管理学院研究生会
二零一七年十一月
武汉大学第一届研究生心理健康节旨在创建和谐校园文化、营造健康心理环境,培育和引导广大研究生形成自尊自信、理性平和、积极向上的健康心态,促进研究生思想道德素质、科学文化素质和心理健康素质协调发展,争做“有理想、有本领、有担当”的新时代的弄潮儿!
本次活动的举办宗旨是“在娱乐中交流感情,在交流中感悟自我”,举办心理健康节的目的在于满足研究生群体的切实需求,所以各研究生会积极带动身边同学参与,切实提高研究生群体的心理健康水平,希望大家做“心里有阳光,脚下有力量”的有志青年!一方面我们要关注自己的心理健康,肯定自我,悦纳自我;另一方面要积极开展心理互助活动,与身边朋友多沟通多交流,在遇到心理问题时主动寻求心理帮助,在他人的帮助下健康成长。
此次活动由武汉大学十四个院系的研究生会共同组织的,面向全院研究生,历时近半个月,具有较强的实践性、娱乐性和趣味性。本次活动的筹备工作历时一个月,先后经历了活动形式策划、前期宣传、现场节目排演、相关工作人员培训等环节,所有筹备工作环环相扣,有条不紊的依次展开。在“恋爱心理学美文征集”板块中,本次活动积极引导活动参与者乃至全校诸多院系的情侣回忆与彼此间的暖心小故事,珍视当下幸福快乐的时光,并畅想彼此一起可能的未来,旨在营造出浓烈的恋爱氛围,促使契约情侣交流更加深刻,加深与巩固正在恋爱中的情侣之间的感情,也为诸多单身同志提供了一个学习借鉴的机会。
下面我们将从三大部分来总结汇报我院和国家文化创新研究中心、口腔医学院在承办武汉大学第一届研究生心理健康节系列活动中“恋爱心理学美文征集”情诗美文征集板块中所进行的工作。第一部分是宣传工作,第二部分是稿件整理与评审,第三部分是现场颁奖与公开展览,第四部分是我们对活动中问题的反思,争取为下一届活动的成功举办提供一个完备的参考方案。
第一章 筹备宣传
(一)筹备工作
我院与国家文化创新研究中心、口腔医学院三院共同承办“研究生婚恋心理初探”之“恋爱心理学美文征集”,商议活动的大致流程与分工,并在之后的活动中主动沟通,积极参与。
我院率先完成“恋爱心理学美文征集”的活动策划的撰写,对于活动的预算,奖品购置与具体时间安排等内容与其他院系积极交流后确定,之后由口腔院完成了活动宣传推文的撰写,而文创院完成了宣传海报的制作。



(二)广泛宣传
在保证与其他各院系联络的同时,我们三院的宣传工作也在积极展开当中。在线上方面,我们三院研会官方微信平台发送推文,并由相关人员转发,进一步通过微博,QQ扩大该活动的宣传影响范围。
在线下宣传上,我院负责将海报分别挂在各学部食堂,教学楼等显眼位置,争取将活动宣传范围扩散至全校范围。
第二章 稿件整理与评审
从活动开展至截稿期止时,我们的宣传活动未曾懈怠,最终共收到稿件30多份。对所收到的所有稿件,在隐去投稿人信息后在三院系中进行内部盲审, 遴选出票数最高的12份稿件,作为参加网络投票最终评选的作品。在确认入选作品的作者后,我院及时通过短信、QQ等方式对其进行通知,并向所有投稿者致谢。
为保证活动进度如期推进,我们及时将入选作品整理、排版、美化,形成可投票推文,并确定网络投票环节从15日开始,于17日下午三点截止,最终获奖作品由网络投票所得票数决定。对于该推文,我们多院同样通过官方微信推送、QQ转发等形式进行宣传,力求扩大鉴赏投票群体。
在网络投票截止后,对票数结果进行统计,确定活动最终的一、二、三等奖获奖名单,并对所有入选作品作者进行致谢,通知获奖作者闭幕晚会及奖品领取的时间地点。
而在“致我的契约情侣”活动中,在第一天配对CP线下活动时,我们提倡他们将自己心中的想法或者见面的感受写给对方,再交由我们保管至活动最后一天,届时再收到来自对方的信件。我们相信,当配对CP经过七天相处后,也许还在感动和不安中探索,也许成为了好朋友,或者已经认定彼此,但是不管怎样,当活动结束他们拿到这封属于“过去”的信件时,心中一定都是充满着感动和温暖的。
第七章颁奖及展览
在11月17号晚6点半电信院举办的闭幕晚会上,首先由我们将“致我的契约情侣”信件转交给契约情侣双方。当初他们将信件交给我们时,能够看出脸上带有一丝犹豫,也有一丝期待,而我们很开心,他们能够信任我们。此刻活动将要结束时,伴随着整个活动的回忆视频与甜蜜的歌声,我们将信件发送到收信人手上,他们脸上多了一份快乐与自信。我们很开心能够参与到他们的心路历程中。
接着,情诗美文征集活动由我院心理健康部部长对各位参赛获奖作者进行颁奖,并邀请他们一起合影留念,每个人脸上都洋溢着幸福的笑容,这是对彼此感情的肯定,也是对我们活动的肯定。
在闭幕仪式结束后,我院对获奖作品进行排版、打印,于18日在信息学部二食堂北门处进行展览一日,19日将其回收处理。
至此,“恋爱心理学美文征集”情诗美文征集活动正式完结。
第八章活动总结
从确定活动策划,安排活动进度,组织人员分工前期筹备工作,中期线上线下宣传活动,收集整理稿件,院系内部初审,到后期网络投票,颁奖仪式,“恋爱心理学美文征集”情诗美文征集活动凝结着资环院、文创院与口腔院以及其他诸多院系共同的心血汗水,本次活动的顺利进行与收尾也是所有工作人员共同努力的成果,十分感谢在本次活动发挥聪明才智,劳心劳力,大力宣传的所有同学。
本次活动旨在为契约情侣创造深入交流沟通的机会以及双方未来无限的可能性,也是为校园中众多情侣们回忆初心,升温感情,再次表白真心创造机会,营造出一种恋爱中温馨的气氛。让同学们在生活学习之余,不忘初心,珍视感情,珍重彼此相伴的他or她,在尊重对方的基础上共同思考未来;也能让诸多单身同学习得恋爱技巧,锻炼恋爱心理,为早日脱单积累经验。
在活动顺利收尾后,我们对活动中出现的诸多问题也进行了相应地反思。首先,活动宣传力有不逮,尽管我们主办三院与其他兄弟院系对该次活动大力宣传,大部分同学对本活动的了解仍然不多,兴趣寥寥;其次,本次活动吸引力不够强,无法吸引同学广泛参与,最终收集到的所有稿件中大部分是我们主办三院同学的投稿,可能是最终奖品不够诱人,也可能是我们对于活动的诠释宣传不够到位等原因。尽管本次活动如期顺利完成收尾,但是其中存在的问题仍然值得我们不断推敲,改善,从而为以后的类似的活动举行提供借鉴。“恋爱心理学美文征集”情诗美文征集活动本身具备话题性,希望下一次举办能够将活动影响范围进一步扩大,吸引更多的同学参与,成为热点活动。
活动已然结束,相信每个参与其中的同学都有自己的收获,无论是回忆曾经的温馨与喜悦,还是对彼此深入了解的兴奋与感动,亦或者是在幕后默默奉献的欣喜。在笔者写下信件、稿件上的一字一句,相信心中也是充满喜悦,悸动不已;在收信者看到信件,审稿者看到故事的时候,心中也同样会掀起波澜。希望这次活动能够为所有同学带来对恋爱的进一步思考与理解,为校园生活中留下属于爱情浓墨重彩的一笔!
下面的程序设计是本人自己设计出来的改了最少三版:
-
个人信息 ——姓名 电话 微信号
-
不敏感信息——家乡 学部
-
自身条件——
-
理想对象条件——
-
自身的期望
-
学位、时间排序;
-
乐高积木模型(遴选池);
-
再进行细化-因素匹配;
|
项目
|
学部(√)
|
院系(√)
|
年级
男女
|
年龄
男女
|
身高
男女
|
体重(√)
|
性格标签(多选)
|
家乡(√)
|
| 自身条件 |
6
|
8
|
10
|
14
|
16
|
18
|
22
|
3
|
|
理想条件
|
7(无所谓)
|
9
|
11(无所谓)false
|
15
|
17(无所谓)false
|
19(无所谓)
|
23
|
|
|
处理方式
|
core_deal_single_add |
core_deal_single
|
core_deal_special
|
core_deal_year
|
core_deal_special
|
core_deal_add
|
core_deal_two_up
|
core_deal_single
|
|
加权值
|
30
|
-80
|
40
|
100
|
70
|
20
|
50
|
80
|
|
项目
|
恋爱次数(√)
|
时间段(√)
|
恋爱原因(多选,其它)
|
择偶标准(多选,其它)
|
婚前性行为(√)
|
理想爱情(其它)
|
维持感情(其它)
|
异性朋友(√)
(无所谓)
|
自拍狂(√)
|
课余活动(其它)
|
| 自身条件 |
24
|
25
|
26
|
27
|
28
|
29
|
30
|
31
|
32
|
33
|
|
理想条件
|
|
|
|
|
|
|
|
|
|
|
|
处理方式
|
core_deal
|
core_deal
|
core_deal_two_dwon
|
core_deal_two_up
|
core_deal
|
core_deal_up
|
core_deal_up
|
core_deal_add
|
core_deal
|
core_deal_up
|
|
加权值
|
20
|
20
|
60
|
60
|
100
|
50
|
50
|
80
|
30
|
50
|
-
姓名
-
性别
-
家乡(30)
-
手机号
-
微信号
-
学部(10)
-
理想型学部(10)
-
院系(10)
-
理想型院系(10)
-
年级(30)
-
理想型年级(30)
-
星座(10)
-
理想型星座(10)
-
年龄(30)
-
理想型年龄范围(30)
-
身高(20)
-
理想型身高(20)
-
体重()
-
理想型体重
-
兴趣爱好
-
喜欢菜品口味
-
性格标签
-
理想型性格标签
-
恋爱次数
-
最近一次恋爱期
-
恋爱主观原因
-
择偶标准
-
婚前性行为
-
期待的理想爱情
-
维持感情重要的是
-
异性朋友看法
-
朋友圈晒自拍
-
课余活动
注:后期放弃了分级筛选(主要原因还是因为时间问题,刚开始我们的活动预期报名人数80人,最后有效报名:682人,女生比男生多23人左右)
处理程序设计1(原始数据量化处理):
功能:
1;对原始文字标签数据进行数字量化处理,易于后续处理;
2,对学位进行敏感度排序(学院相关领导要求优先解决博士单身问题,我们的排序顺序遵循先学位博士-硕士-本科排序,后报名时间排序,排序越靠前进行选择的相关度匹配值越高也符合参与者两人的择偶预期);
3,分别生成男生、女生数据集为后续进行优先级交替筛选。
1 import xlrd 2 import re 3 import os 4 5 6 7 #功能块 8 def file_name(file_dir): 9 L = [] 10 for root, dirs, files in os.walk(file_dir): 11 #print root #当前目录路径 12 #print dirs #当前路径下所有子目录 13 #print files #当前路径下所有非目录子文件 14 for file in files: 15 if os.path.splitext(file)[1] != '.py'and os.path.splitext(file)[0] != '男女生数据集生成' \ 16 and os.path.splitext(file)[0] != '男生数据集'and os.path.splitext(file)[0] != '女生数据集' \ 17 and os.path.splitext(file)[0] != '最终数据集' and os.path.splitext(file)[1] != '.exe': 18 L.append(os.path.join(root,file)) 19 return L 20 21 root_folder = os.path.dirname(os.path.realpath(__file__)) 22 files = file_name(root_folder) 23 24 data = xlrd.open_workbook(files[0]) 25 26 table = data.sheets()[0] 27 28 nrows = table.nrows #行数 29 # print(nrows) 30 ncols = table.ncols #列数 31 # print(ncols) 32 # print("\n") 33 34 35 ''' 36 1,量化处理 37 ''' 38 def key_value(i): 39 40 data_mid = [] 41 for j in range(ncols-7):#将照片栏隐去 42 43 data_mid.append(table.row_values(i)[j+6]) 44 45 if data_mid[1] == '男': 46 data_mid[1] = 1 47 else: 48 data_mid[1] = 2 49 50 #家乡——数值化 51 if data_mid[2] == '安徽': 52 data_mid[2] = 1 53 elif data_mid[2] == '北京': 54 data_mid[2] = 2 55 elif data_mid[2] == '重庆': 56 data_mid[2] = 3 57 elif data_mid[2] == '福建': 58 data_mid[2] = 4 59 elif data_mid[2] == '甘肃': 60 data_mid[2] = 5 61 elif data_mid[2] == '广东': 62 data_mid[2] = 6 63 elif data_mid[2] == '广西': 64 data_mid[2] = 7 65 elif data_mid[2] == '贵州': 66 data_mid[2] = 8 67 elif data_mid[2] == '海南': 68 data_mid[2] = 9 69 elif data_mid[2] == '河北': 70 data_mid[2] = 10 71 elif data_mid[2] == '黑龙江': 72 data_mid[2] = 11 73 elif data_mid[2] == '河南': 74 data_mid[2] = 12 75 elif data_mid[2] == '香港': 76 data_mid[2] = 13 77 elif data_mid[2] == '湖北': 78 data_mid[2] = 14 79 elif data_mid[2] == '湖南': 80 data_mid[2] = 15 81 elif data_mid[2] == '江苏': 82 data_mid[2] = 16 83 elif data_mid[2] == '江西': 84 data_mid[2] = 17 85 elif data_mid[2] == '吉林': 86 data_mid[2] = 18 87 elif data_mid[2] == '辽宁': 88 data_mid[2] = 19 89 elif data_mid[2] == '澳门': 90 data_mid[2] = 20 91 elif data_mid[2] == '内蒙古': 92 data_mid[2] = 21 93 elif data_mid[2] == '宁夏': 94 data_mid[2] = 22 95 elif data_mid[2] == '青海': 96 data_mid[2] = 23 97 elif data_mid[2] == '山东': 98 data_mid[2] = 24 99 elif data_mid[2] == '上海': 100 data_mid[2] = 25 101 elif data_mid[2] == '山西': 102 data_mid[2] = 26 103 elif data_mid[2] == '陕西': 104 data_mid[2] = 27 105 elif data_mid[2] == '四川': 106 data_mid[2] = 28 107 elif data_mid[2] == '台湾': 108 data_mid[2] = 29 109 elif data_mid[2] == '天津': 110 data_mid[2] = 30 111 elif data_mid[2] == '新疆': 112 data_mid[2] = 31 113 elif data_mid[2] == '西藏': 114 data_mid[2] = 32 115 elif data_mid[2] == '云南': 116 data_mid[2] = 33 117 elif data_mid[2] == '浙江': 118 data_mid[2] = 34 119 elif data_mid[2] == '海外': 120 data_mid[2] = 35 121 122 123 #学部——数值化 124 if data_mid[5] == '文理学部': 125 data_mid[5] = 1 126 elif data_mid[5] == '工学部': 127 data_mid[5] = 2 128 elif data_mid[5] == '信息学部': 129 data_mid[5] = 3 130 else:#医学部 131 data_mid[5] = 4 132 133 #理想型学部——数值化 134 if data_mid[6] == '文理学部': 135 data_mid[6] = 1 136 elif data_mid[6] == '工学部': 137 data_mid[6] = 2 138 elif data_mid[6] == '信息学部': 139 data_mid[6] = 3 140 elif data_mid[6] == '医学部': 141 data_mid[6] = 4 142 else:#无所谓 143 data_mid[6] = 5 144 145 #年级——数值化 146 if data_mid[9] == '研一': 147 data_mid[9] = 1 148 elif data_mid[9] == '研二': 149 data_mid[9] = 2 150 elif data_mid[9] == '研三': 151 data_mid[9] = 3 152 elif data_mid[9] == '博士': 153 data_mid[9] = 4 154 155 #理想年级——数值化 156 if data_mid[10] == '研一': 157 data_mid[10] = 1 158 elif data_mid[10] == '研二': 159 data_mid[10] = 2 160 elif data_mid[10] == '研三': 161 data_mid[10] = 3 162 elif data_mid[10] == '博士': 163 data_mid[10] = 4 164 else:#无所谓 165 data_mid[10] = 5 166 167 #data_mid[13] = int(data_mid[13]) 168 169 #身高——数值化 170 if data_mid[15] == '160以下': 171 data_mid[15] = 1 172 elif data_mid[15] == '160-165': 173 data_mid[15] = 2 174 elif data_mid[15] == '166-170': 175 data_mid[15] = 3 176 elif data_mid[15] == '170-175': 177 data_mid[15] = 4 178 elif data_mid[15] == '175-180': 179 data_mid[15] = 5 180 elif data_mid[15] == '180以上': 181 data_mid[15] = 6 182 183 #理想身高——数值化 184 if data_mid[16] == '160以下': 185 data_mid[16] = 1 186 elif data_mid[16] == '160-165': 187 data_mid[16] = 2 188 elif data_mid[16] == '166-170': 189 data_mid[16] = 3 190 elif data_mid[16] == '170-175': 191 data_mid[16] = 4 192 elif data_mid[16] == '175-180': 193 data_mid[16] = 5 194 elif data_mid[16] == '180以上': 195 data_mid[16] = 6 196 else:#无所谓 197 data_mid[16] = 7 198 199 #体重——数值化 200 if data_mid[17] == '瘦': 201 data_mid[17] = 1 202 elif data_mid[17] == '微瘦': 203 data_mid[17] = 2 204 elif data_mid[17] == '适中': 205 data_mid[17] = 3 206 elif data_mid[17] == '微胖': 207 data_mid[17] = 4 208 elif data_mid[17] == '胖': 209 data_mid[17] = 5 210 211 #理想体重——数值化 212 if data_mid[18] == '瘦': 213 data_mid[18] = 1 214 elif data_mid[18] == '微瘦': 215 data_mid[18] = 2 216 elif data_mid[18] == '适中': 217 data_mid[18] = 3 218 elif data_mid[18] == '微胖': 219 data_mid[18] = 4 220 elif data_mid[18] == '胖': 221 data_mid[18] = 5 222 elif data_mid[18] == '无所谓': 223 data_mid[18] = 6 224 225 #自己的性格标签——数值化 226 a = data_mid[21] 227 y = re.split('┋',a)#分割该栏目内容 228 if len(y) == 2: 229 for k in range(len(y)): 230 if y[k] == '完美型完美主义者': 231 y[k] = 1 232 elif y[k] == '全爱型给予者': 233 y[k] = 2 234 elif y[k] == '成就型实干者': 235 y[k] = 3 236 elif y[k] == '艺术型浪漫者': 237 y[k] = 4 238 elif y[k] == '智慧型观察者': 239 y[k] = 5 240 elif y[k] == '忠诚型怀疑论者': 241 y[k] = 6 242 elif y[k] == '活跃型享乐者': 243 y[k] = 7 244 elif y[k] == '领袖型能力者': 245 y[k] = 8 246 elif y[k] == '和平型调停者': 247 y[k] = 9 248 else: 249 # print(y) 250 # print(y[0]) 251 if y[0] == '完美型完美主义者': 252 y[0] = 1 253 elif y[0] == '全爱型给予者': 254 y[0] = 2 255 elif y[0] == '成就型实干者': 256 y[0] = 3 257 elif y[0] == '艺术型浪漫者': 258 y[0] = 4 259 elif y[0] == '智慧型观察者': 260 y[0] = 5 261 elif y[0] == '忠诚型怀疑论者': 262 y[0] = 6 263 elif y[0] == '活跃型享乐者': 264 y[0] = 7 265 elif y[0] == '领袖型能力者': 266 y[0] = 8 267 elif y[0] == '和平型调停者': 268 y[0] = 9 269 data_mid[21] = y[0] 270 271 272 #理想的性格标签——数值化 273 a = data_mid[22] 274 y = re.split('┋',a)#分割该栏目内容 275 #此处代码段有bug,已修复 276 #print(y) 277 if len(y) == 2: 278 #print('test00') 279 for k in range(len(y)): 280 if y[k] == '完美型完美主义者': 281 y[k] = 1 282 elif y[k] == '全爱型给予者': 283 y[k] = 2 284 elif y[k] == '成就型实干者': 285 y[k] = 3 286 elif y[k] == '艺术型浪漫者': 287 y[k] = 4 288 elif y[k] == '智慧型观察者': 289 y[k] = 5 290 elif y[k] == '忠诚型怀疑论者': 291 y[k] = 6 292 elif y[k] == '活跃型享乐者': 293 y[k] = 7 294 elif y[k] == '领袖型能力者': 295 y[k] = 8 296 elif y[k] == '和平型调停者': 297 y[k] = 9 298 else: 299 # print('test01') 300 # print(y[0]) 301 if y[0] == '完美型完美主义者': 302 y[0] = 1 303 elif y[0] == '全爱型给予者': 304 y[0] = 2 305 elif y[0] == '成就型实干者': 306 y[0] = 3 307 elif y[0] == '艺术型浪漫者': 308 y[0] = 4 309 elif y[0] == '智慧型观察者': 310 y[0] = 5 311 elif y[0] == '忠诚型怀疑论者': 312 y[0] = 6 313 elif y[0] == '活跃型享乐者': 314 y[0] = 7 315 elif y[0] == '领袖型能力者': 316 y[0] = 8 317 elif y[0] == '和平型调停者': 318 y[0] = 9 319 data_mid[22] = y[0] 320 321 322 323 #恋爱次数——数值化 324 if data_mid[23] == '无': 325 data_mid[23] = 1 326 elif data_mid[23] == '一次': 327 data_mid[23] = 2 328 elif data_mid[23] == '二次': 329 data_mid[23] = 3 330 elif data_mid[23] == '三次及三次以上': 331 data_mid[23] = 4 332 333 #最近一次恋爱持续时间——数值化 334 if data_mid[24] == '1~3个月': 335 data_mid[24] = 1 336 elif data_mid[24] == '4~6个月': 337 data_mid[24] = 2 338 elif data_mid[24] == '半年~1年': 339 data_mid[24] = 3 340 elif data_mid[24] == '三次及三次以上': 341 data_mid[24] = 4 342 elif data_mid[24] == '1~2年': 343 data_mid[24] = 5 344 elif data_mid[24] == '2年以上': 345 data_mid[24] = 6 346 elif data_mid[24] == '无恋爱经历': 347 data_mid[24] = 7 348 349 #你恋爱的最重要的主观原因——数值化 350 b = data_mid[25] 351 x = re.split('┋',b)#分割该栏目内容 352 #此处代码有误,已修复 353 #print(x) 354 if len(x) == 2: 355 for k in range(len(x)): 356 if x[k] == '感情上有所寄托': 357 x[k] = 1 358 elif x[k] == '出于爱情,为婚姻打基础': 359 x[k] = 2 360 elif x[k] == '希望尝试恋爱滋味': 361 x[k] = 3 362 elif x[k] == '被对方吸引': 363 x[k] = 4 364 elif x[k] == '了解异性': 365 x[k] = 5 366 elif x[k] == '生理和心理的需要': 367 x[k] = 6 368 elif x[k] == '生活空虚,寻求刺激': 369 x[k] = 7 370 elif x[k] == '跟随时代潮流': 371 x[k] = 8 372 elif x[k] == '不谈恋爱怕别人瞧不起': 373 x[k] = 9 374 elif x[k] == '证明自身价值': 375 x[k] = 10 376 elif x[k] == '对学习失去兴趣,兴奋点转移': 377 x[k] = 11 378 elif x[k] == '出于经济目的': 379 x[k] = 12 380 # elif x[k] == '其他': 381 # x[k] = 12 382 else: 383 x[k] = 13 384 else: 385 if x[0] == '感情上有所寄托': 386 x[0] = 1 387 elif x[0] == '出于爱情,为婚姻打基础': 388 x[0] = 2 389 elif x[0] == '希望尝试恋爱滋味': 390 x[0] = 3 391 elif x[0] == '被对方吸引': 392 x[0] = 4 393 elif x[0] == '了解异性': 394 x[0] = 5 395 elif x[0] == '生理和心理的需要': 396 x[0] = 6 397 elif x[0] == '生活空虚,寻求刺激': 398 x[0] = 7 399 elif x[0] == '跟随时代潮流': 400 x[0] = 8 401 elif x[0] == '不谈恋爱怕别人瞧不起': 402 x[0] = 9 403 elif x[0] == '证明自身价值': 404 x[0] = 10 405 elif x[0] == '对学习失去兴趣,兴奋点转移': 406 x[0] = 11 407 elif x[0] == '出于经济目的': 408 x[0] = 12 409 # elif x[0] == '其他': 410 else: 411 x[0] = 13 412 data_mid[25] = x 413 414 415 #你的择偶标准——数值化 416 c = data_mid[26] 417 z = re.split('┋',c)#分割该栏目内容 418 if len(z) == 2: 419 for l in range(len(z)): 420 if z[l] == '外貌': 421 z[l] = 1 422 elif z[l] == '品德': 423 z[l] = 2 424 elif z[l] == '性格': 425 z[l] = 3 426 elif z[l] == '家庭': 427 z[l] = 4 428 elif z[l] == '才华': 429 z[l] = 5 430 elif z[l] == '志趣相投': 431 z[l] = 6 432 # elif z[l] == '其它': 433 else: 434 z[l] = 7 435 else: 436 if z[0] == '外貌': 437 z[0] = 1 438 elif z[0] == '品德': 439 z[0] = 2 440 elif z[0] == '性格': 441 z[0] = 3 442 elif z[0] == '家庭': 443 z[0] = 4 444 elif z[0] == '才华': 445 z[0] = 5 446 elif z[0] == '志趣相投': 447 z[0] = 6 448 # elif z[0] == '其它': 449 else: 450 z[0] = 7 451 data_mid[26] = z 452 453 454 #你对大学生婚前性行为的态度——数值化 455 if data_mid[27] == '可以理解且自己会去尝试': 456 data_mid[27] = 1 457 elif data_mid[27] == '可以理解但自己不会去尝试': 458 data_mid[27] = 2 459 elif data_mid[27] == '不能理解,如果发生也无所谓': 460 data_mid[27] = 3 461 elif data_mid[27] == '不能理解,如果发生终身后悔': 462 data_mid[27] = 4 463 464 #你所期待的理想爱情——数值化 465 if data_mid[28] == '电视电影里的浪漫爱情': 466 data_mid[28] = 1 467 elif data_mid[28] == '经典文学作品里的刻骨铭心': 468 data_mid[28] = 2 469 elif data_mid[28] == '像父母之间稳定的爱情': 470 data_mid[28] = 3 471 elif data_mid[28] == '柏拉图式的精神恋爱': 472 data_mid[28] = 4 473 # else:#直接空运算,不变动原始值 474 # data_mid[28] = 475 else: 476 data_mid[28] = 5 477 478 #你认为你和你的“另一半”维持感情,重要的是——数值化 479 if data_mid[29] == '坦诚': 480 data_mid[29] = 1 481 elif data_mid[29] == '责任心': 482 data_mid[29] = 2 483 elif data_mid[29] == '忍耐和包容': 484 data_mid[29] = 3 485 elif data_mid[29] == '有共同话题': 486 data_mid[29] = 4 487 elif data_mid[29] == '浪漫幽默': 488 data_mid[29] = 5 489 else: 490 data_mid[29] = 6 491 492 #你对异性朋友的看法——数值化 493 if data_mid[30] == '认为异性之间存在纯洁的友谊,所以有男(女)闺蜜很正常': 494 data_mid[30] = 1 495 elif data_mid[30] == '认为异性之间存在纯洁的友谊,但关系不应该过好': 496 data_mid[30] = 2 497 elif data_mid[30] == '认为异性之间不存在纯洁的友谊,所以不应该存在男(女)闺蜜': 498 data_mid[30] = 3 499 elif data_mid[30] == '无所谓': 500 data_mid[30] = 4 501 502 #介不介意男(女)朋友在朋友圈晒自拍的行为——数值化 503 if data_mid[31] == '介意': 504 data_mid[31] = 1 505 elif data_mid[31] == '不介意': 506 data_mid[31] = 2 507 elif data_mid[31] == '频率不高可以接受': 508 data_mid[31] = 3 509 510 #日常除了睡觉吃饭学术占用时间最多的活动——数值化 511 if data_mid[32] == '兼职': 512 data_mid[32] = 1 513 elif data_mid[32] == '运动': 514 data_mid[32] = 2 515 elif data_mid[32] == '社团活动': 516 data_mid[32] = 3 517 elif data_mid[32] == '电影电视剧': 518 data_mid[32] = 4 519 elif data_mid[32] == '游戏': 520 data_mid[32] = 5 521 elif data_mid[32] == '阅读': 522 data_mid[32] = 6 523 else:#其它 524 data_mid[32] = 7 525 526 #print(data_mid) 527 data_mid.insert(0,table.row_values(i)[0]) 528 return data_mid 529 530 531 532 ''' 533 2,生成字典 534 ''' 535 data = {} 536 for i in range(1,nrows): 537 data[i] = key_value(i) 538 539 540 # ''' 541 # 序号生成,第一个为序号值 542 # ''' 543 # for key in data: 544 # data[key].insert(0,key+5) 545 546 # print(data[369]) 547 # print(data[369][0]) 548 549 ''' 550 3,将男生女生进行重新排序 551 ''' 552 data_men = {} 553 data_women = {} 554 i = 0 555 j = 0 556 #print(len(data))#共有398个数据 557 for key in data: 558 559 if data[key][2] == 1: #代表男生 560 i += 1 561 data_men[i] = data[key] 562 else: 563 j += 1 564 data_women[j] = data[key] 565 566 print('男生人数:') 567 print(len(data_men)) 568 print('\n') 569 print('女生人数:') 570 print(len(data_women)) 571 572 573 data_degree = {} 574 ''' 575 4,对男生学位进行简单排序,先是博士 576 ''' 577 data_change = {} 578 i = 0 579 for key in data_men: 580 if data_men[key][10] == 4: 581 i += 1 582 data_change[i] = data_men[key] 583 #print(len(data_change)) 584 data_degree[1] = [len(data_change)] 585 586 ''' 587 研三 588 ''' 589 i = len(data_change) 590 for key in data_men: 591 if data_men[key][10] == 3: 592 i += 1 593 data_change[i] = data_men[key] 594 595 #print(len(data_change)) 596 data_degree[1].append(len(data_change)-data_degree[1][0]) 597 598 ''' 599 硕二 600 ''' 601 i = len(data_change) 602 for key in data_men: 603 if data_men[key][10] == 2: 604 i += 1 605 data_change[i] = data_men[key] 606 607 data_degree[1].append(len(data_change)-data_degree[1][0]-data_degree[1][1]) 608 609 ''' 610 硕一 611 ''' 612 i = len(data_change) 613 for key in data_men: 614 if data_men[key][10] == 1: 615 i += 1 616 data_change[i] = data_men[key] 617 618 data_degree[1].append(len(data_change)-data_degree[1][0]-data_degree[1][1]-data_degree[1][2]) 619 620 data_men = {} 621 data_men = data_change 622 data_change = {} 623 624 # for key in data_change: 625 # print('\n') 626 # print(key) 627 # print(data_change[key]) 628 629 630 631 ''' 632 5,对女生学位进行简单排序,先是博士 633 ''' 634 data_change = {} 635 i = 0 636 for key in data_women: 637 if data_women[key][10] == 4: 638 i += 1 639 data_change[i] = data_women[key] 640 #print(len(data_change)) 641 data_degree[2] = [len(data_change)] 642 643 644 ''' 645 研三 646 ''' 647 i = len(data_change) 648 for key in data_women: 649 if data_women[key][10] == 3: 650 i += 1 651 data_change[i] = data_women[key] 652 653 #print(len(data_change)) 654 data_degree[2].append(len(data_change)-data_degree[2][0]) 655 656 ''' 657 硕二 658 ''' 659 i = len(data_change) 660 for key in data_women: 661 if data_women[key][10] == 2: 662 i += 1 663 data_change[i] = data_women[key] 664 665 data_degree[2].append(len(data_change)-data_degree[2][0]-data_degree[2][1]) 666 667 ''' 668 硕一 669 ''' 670 i = len(data_change) 671 for key in data_women: 672 if data_women[key][10] == 1: 673 i += 1 674 data_change[i] = data_women[key] 675 data_degree[2].append(len(data_change)-data_degree[2][0]-data_degree[2][1]-data_degree[2][2]) 676 677 # for key in data_change: 678 # print('\n') 679 # print(key) 680 # print(data_change[key]) 681 682 data_women = {} 683 data_women = data_change 684 data_change = {} 685 686 # for key in data_women: 687 # print('\n') 688 # print(key) 689 # print(data_women[key]) 690 691 ''' 692 693 现在的程序状况: 694 data 原始数据 695 data_men 排序后的男生 696 data_women 排序后的女生 697 data_degree 各个学位段的人数 698 699 ''' 700 #写Excel操作 701 from xlwt import * 702 file = Workbook(encoding = 'utf-8') 703 table = file.add_sheet('女生数据集.xls') 704 705 #for key in data_women: 706 for key in data_women: 707 for i in range(len(data_women[1])): 708 #print(data_women[key][i]) 709 values_now = data_women[key][i] 710 table.write(key,i,str(values_now)) 711 712 file.save('E:\data\personal\社团\1+1=π活动\后期数据\源程序\\女生数据集.xls') 713 714 715 716 from xlwt import * 717 file = Workbook(encoding = 'utf-8') 718 table = file.add_sheet('男生数据集.xls') 719 720 #for key in data_men: 721 for key in data_men: 722 for i in range(len(data_men[1])): 723 #print(data_men[key][i]) 724 values_now = data_men[key][i] 725 table.write(key,i,str(values_now)) 726 727 file.save('E:\data\personal\社团\1+1=π活动\后期数据\源程序\\男生数据集.xls') 728 729 print('\n') 730 print("男女生数据集已成功生成!") 731 print('\n')
程序设计2(正式筛选程序):
功能:
1,男女生数据集读取,分别生成排序规则队列;
2,进行优先级交替穷举,每个数据都生成对应所有的数据相关匹配值再次进行相关度的排序(由高到低),将相关匹配值最高的数据和当前数据混合、同时将这两个数据都从队列中删除(局部最优);
1 #数据加权运算 2 3 import xlrd 4 import re 5 6 def data_out(path): 7 data = xlrd.open_workbook(path) 8 table = data.sheets()[0] 9 nrows = table.nrows #行数 10 #print(nrows) 11 ncols = table.ncols #列数 12 #print(ncols) 13 # print("\n") 14 dict = {} 15 for i in range(1,nrows): 16 dict[i] = table.row_values(i) 17 return dict 18 19 #print(table.row_values(1)) 20 #print(table.row_values[1]) #错误示范 21 22 23 24 #此处是数据处理比对模块 25 def data_deal(data_a,data_b): 26 data_ultilate = {} 27 for key_a in data_a: #遍历data_a 28 29 old_sum = [0,0] 30 #print(key_a) 31 for key_b in data_b: #遍历data_b 32 #print(key_b) 33 sum = 0 34 35 #确认 36 sum = core_deal_single(sum,data_a,key_a,data_b,key_b,3,3,80)#家乡 37 38 #带有无所谓选项 39 sum = core_deal_single_add(sum,data_a,key_a,data_b,key_b,6,7,30,5)#学部 40 sum = core_deal_single_add(sum,data_a,key_a,data_b,key_b,7,6,30,5)#学部 41 42 sum = core_deal_single(sum,data_a,key_a,data_b,key_b,8,8,-80)#院系 43 44 #带有无所谓选项 45 #这里有一些问题,注意,需要后期解决 46 #有可能是float数据形式的问题 47 #就按照双选的结果来吧 48 49 sum = core_deal_add(sum,data_a,key_a,data_b,key_b,10,11,40,5)#年级 50 sum = core_deal_add(sum,data_a,key_a,data_b,key_b,11,10,40,5)#年级 51 52 #这里需要认真对待 53 #年龄,需要谨慎对待 54 sum = core_deal_year(sum,data_a,key_a,data_b,key_b,14,14,100)#年龄 55 56 57 sum = core_deal(sum,data_a,key_a,data_b,key_b,16,17,70)#身高 58 sum = core_deal(sum,data_a,key_a,data_b,key_b,17,16,70)#身高 59 60 #带有无所谓选项 61 sum = core_deal_add(sum,data_a,key_a,data_b,key_b,18,19,20,6)#体重 62 sum = core_deal_add(sum,data_a,key_a,data_b,key_b,19,18,20,6)#体重 63 64 #双选 65 sum = core_deal_two_up(sum,data_a,key_a,data_b,key_b,22,23,50)#性格 66 sum = core_deal_two_up(sum,data_a,key_a,data_b,key_b,23,22,50)#性格 67 68 69 70 71 #上面的初始化——比较 72 73 74 75 sum = core_deal(sum,data_a,key_a,data_b,key_b,24,24,20)#恋爱次数 76 77 sum = core_deal(sum,data_a,key_a,data_b,key_b,25,25,20)#最近一次恋爱持续时间: 78 79 #双选、其它 80 sum = core_deal_two_dwon(sum,data_a,key_a,data_b,key_b,26,26,60)#你恋爱的最重要的主观原因: 81 82 #双选、其它 83 sum = core_deal_two_up(sum,data_a,key_a,data_b,key_b,27,27,60)#你的择偶标准是: 84 85 86 sum = core_deal(sum,data_a,key_a,data_b,key_b,28,28,100)#你对大学生婚前性行为的态度是: 87 88 #其它 89 sum = core_deal(sum,data_a,key_a,data_b,key_b,29,29,50)#你所期待的理想爱情是什么样的: 90 #其它 91 sum = core_deal(sum,data_a,key_a,data_b,key_b,30,30,50)#你认为你和你的“另一半”维持感情,重要的是 92 #其它 93 sum = core_deal(sum,data_a,key_a,data_b,key_b,31,31,80)#你对异性朋友的看法是 94 95 sum = core_deal(sum,data_a,key_a,data_b,key_b,32,32,30)#介不介意男(女)朋友在朋友圈晒自拍的行为 96 #其它 97 sum = core_deal(sum,data_a,key_a,data_b,key_b,33,33,50)#日常除了睡觉吃饭学术占用时间最多的活动 98 99 100 if sum >= old_sum[0]: 101 old_sum[0] = sum 102 old_sum[1] = key_b 103 104 105 106 # data_a[key_a].insert(1,old_sum[1]) 107 # data_a[key_a].insert(2,old_sum[0]) 108 data_ultilate[key_a] = [data_a[key_a][0]] #序号 109 data_ultilate[key_a].append(data_a[key_a][1]) #姓名 110 111 data_ultilate[key_a].append(data_a[key_a][4]) #电话 112 data_ultilate[key_a].append(data_a[key_a][5]) #微信 113 114 115 data_ultilate[key_a].append(data_b[old_sum[1]][0]) #序号 116 data_ultilate[key_a].append(data_b[old_sum[1]][1]) #姓名 117 data_ultilate[key_a].append(data_b[old_sum[1]][4]) #电话 118 data_ultilate[key_a].append(data_b[old_sum[1]][5]) #微信 119 120 data_ultilate[key_a].append(old_sum[0]) 121 del data_b[old_sum[1]] 122 123 124 return(data_ultilate) 125 126 127 #正确 128 #特异性的家乡、院系 匹配数值 129 def core_deal_single(sum,data_a,key_a,data_b,key_b,i,j,k):#i 表示data_a第几列,j表示data_b第几列,k表示加权值 130 if data_a[key_a][i] == data_b[key_b][j]: 131 sum = sum + k 132 return sum 133 134 135 #正确 136 def core_deal_single_add(sum,data_a,key_a,data_b,key_b,i,j,k,n):#i 表示data_a第几列,j表示data_b第几列,k表示加权值 137 if data_a[key_a][i] == n or data_b[key_b][j] == n: 138 sum = sum + k 139 else: 140 q = abs(int(data_a[key_a][i]) - int(data_b[key_b][j])) 141 if q == 0: 142 sum = sum + k/1 143 return sum 144 145 146 147 148 #单项选择有效,调整相近的答案的一半分 149 def core_deal(sum,data_a,key_a,data_b,key_b,i,j,k):#i 表示data_a第几列,j表示data_b第几列,k表示加权值 150 q = abs(int(data_a[key_a][i]) - int(data_b[key_b][j])) 151 if q == 0: 152 sum = sum + k 153 elif q == 1: 154 sum = sum + k/3 155 elif q == 2: 156 sum = sum - k/3 157 elif q == 3: 158 sum = sum - k 159 else: 160 sum = sum -k*2 161 return sum 162 163 #单项选择,但是有无所谓选项的值 164 def core_deal_add(sum,data_a,key_a,data_b,key_b,i,j,k,n):#i 表示data_a第几列,j表示data_b第几列,k表示加权值 165 if data_a[key_a][i] == n or data_b[key_b][j] == n: 166 sum = sum + k 167 else: 168 q = abs(int(data_a[key_a][i]) - int(data_b[key_b][j])) 169 if q == 0: 170 sum = sum + k 171 elif q == 1: 172 sum = sum + k/3 173 elif q == 2: 174 sum = sum - k/3 175 elif q == 3: 176 sum = sum - k 177 else: 178 sum = sum -k*2 179 return sum 180 181 #双选 up 182 def core_deal_two_up(sum,data_a,key_a,data_b,key_b,i,j,k):#i 表示data_a第几列,j表示data_b第几列,k表示加权值 183 for m in range(len(data_a[key_a][i])): 184 for n in range(len(data_b[key_b][j])): 185 # if data_a[key_a][i][m] == data_b[key_b][j][n]: 186 # sum = sum + k 187 q = abs( data_a[key_a][i][m] == data_b[key_b][j][n]) 188 if q == 0: 189 sum = sum + k/2 190 elif q == 1: 191 sum = sum + k/4 192 elif q == 2: 193 sum = sum + k/8 194 return sum 195 196 #双选 dwon 恋爱原因 197 def core_deal_two_dwon(sum,data_a,key_a,data_b,key_b,i,j,k):#i 表示data_a第几列,j表示data_b第几列,k表示加权值 198 for m in range(len(data_a[key_a][i])): 199 for n in range(len(data_b[key_b][j])): 200 # if data_a[key_a][i][m] == data_b[key_b][j][n]: 201 # sum = sum + k 202 q = abs( data_a[key_a][i][m] == data_b[key_b][j][n]) 203 if q == 0: 204 sum = sum + k/2 205 elif q == 1: 206 sum = sum + k/4 207 elif q == 2: 208 sum = sum + k/8 209 elif q == 3: 210 sum = sum - k/8 211 elif q == 4: 212 sum = sum - k/4 213 elif q == 5: 214 sum = sum - k/2 215 elif q == 6: 216 sum = sum - k 217 elif q == 7: 218 sum = sum - k*3/2 219 elif q == 8: 220 sum = sum - k*2 221 else: 222 sum = sum -k*3 223 return sum 224 225 #处理年龄数据 226 def core_deal_year(sum,data_a,key_a,data_b,key_b,i,j,k): 227 if data_a[key_a][2] == 2: 228 year_women = float(data_a[key_a][14] ) 229 yaer_men = float(data_b[key_b][14] ) 230 else: 231 year_women = float(data_b[key_b][14]) 232 yaer_men = float(data_a[key_a][14]) 233 q = yaer_men - year_women 234 if q == 1: 235 sum = sum + k 236 elif q == 2: 237 sum = sum + k*3/4 238 elif q == 3: 239 sum = sum + k/4 240 elif q == 4: 241 sum = sum - k*3/4 242 elif q == 5: 243 sum = sum - k*4/3 244 elif q == 6: 245 sum = sum - k*2 246 elif q == 0: 247 sum = sum + k/2 248 elif q == -1: 249 sum = sum - k/2 250 elif q == -2: 251 sum = sum - k*3/4 252 elif q == -3: 253 sum = sum - k*4/3 254 else: 255 sum = sum - k*2 256 return sum 257 258 #处理身高、年级数据 259 def core_deal_special(sum,data_a,key_a,data_b,key_b,i,j,k): 260 if data_a[key_a][2] == 2: 261 year_women = data_a[key_a][i] 262 yaer_men = data_b[key_b][j] 263 else: 264 year_women = data_b[key_b][j] 265 yaer_men = data_a[key_a][i] 266 q = yaer_men - year_women 267 if q == 1: 268 sum = sum + k 269 elif q == 2: 270 sum = sum + k*3/4 271 elif q == 3: 272 sum = sum + k/4 273 elif q == 4: 274 sum = sum - k*3/4 275 elif q == 5: 276 sum = sum - k*4/3 277 elif q == 6: 278 sum = sum - k*2 279 elif q == 0: 280 sum = sum + k/2 281 elif q == -1: 282 sum = sum - k/2 283 elif q == -2: 284 sum = sum - k*3/4 285 elif q == -3: 286 sum = sum - k*4/3 287 else: 288 sum = sum - k*2 289 return sum 290 291 292 293 294 #男生,女生数据集 worked 295 path_name = 'F:\\作业\\1+1=π活动\\后期数据\\源程序\\女生数据集.xls' 296 data_women = {} 297 data_women = data_out(path_name) 298 path_name = 'F:\\作业\\1+1=π活动\\后期数据\\源程序\\男生数据集.xls' 299 data_men = {} 300 data_men = data_out(path_name) 301 302 data_degree = {} 303 data_degree[1] = [] 304 data_degree[2] = [] 305 306 #数量较少的一方开始筛选 worked 307 if len(data_men) <= len(data_women): 308 data_ultilate = data_deal(data_men,data_women) 309 else: 310 data_ultilate = data_deal(data_women,data_men) 311 312 #输出最终的匹配结果 313 # for key in data_ultilate: 314 # print(data_ultilate[key]) 315 # print('\n') 316 317 318 from xlwt import * 319 file = Workbook(encoding = 'utf-8') 320 table = file.add_sheet('最终数据集.xls') 321 322 for key in data_ultilate: 323 for i in range(len(data_ultilate[1])): 324 #print(data_ultilate[key][i]) 325 values_now = data_ultilate[key][i] 326 table.write(key,i,str(values_now)) 327 328 file.save('F:\\作业\\1+1=π活动\\后期数据\\源程序\\最终数据集.xls') 329 330 print('已生成匹配数据')
注:上面的程序是我由硬件转向软甲开发的第一个面向实用的程序设计,另外这个程序好像还不是最终版本
本次活动我们的1+1=π 活动所有活动中的评分最高,院系获得“优秀组织单位奖”,我个人以及活动中的城设学院的一个干活很踏实的同学都获得“先进个人”,13个院系共同获颁“结项证书”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号