
Python爬数据
我当时想弄微信群聊机器人(成语接龙),wxpy用不了(微信不让网页登录)。然后就没有然后了。
记录一下爬数据的代码。(写了好几个月了,现在po上来)
首先说一下,爬数据前看看网站下的robots.txt。
如果人家不允许任何爬虫爬取数据,那就不要去爬人家的数据,要不然真的缺德。(robots.txt只是口头协议,防君子,不防小人)
具体robots.txt规则,我就不贴出来了,百度一大堆。
我爬的这个网站,我看过了,没有robots.txt。(好几个月前看的,现在不知道有没有)
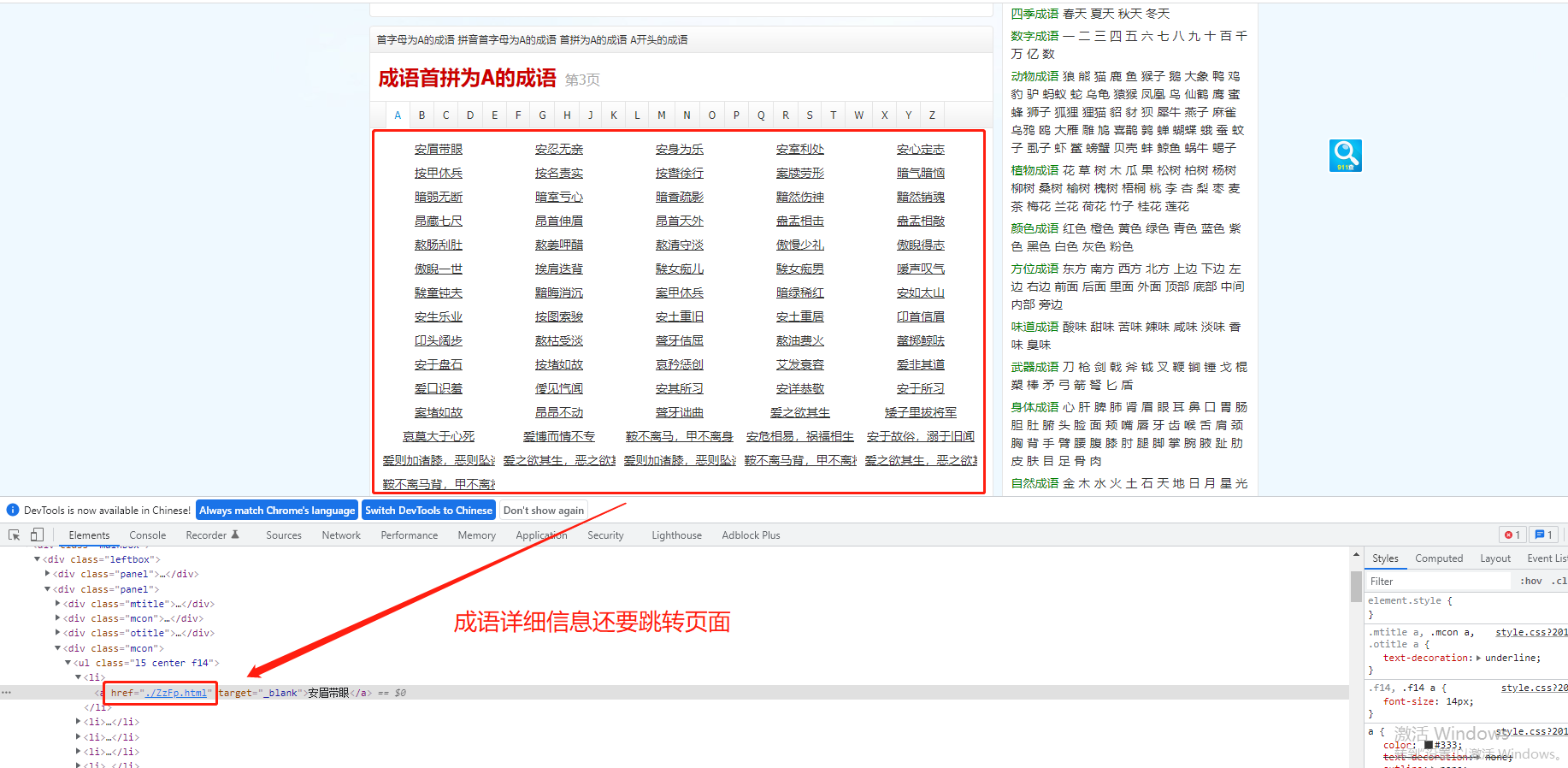
贴爬取页面长相如下:
图一:
图二:
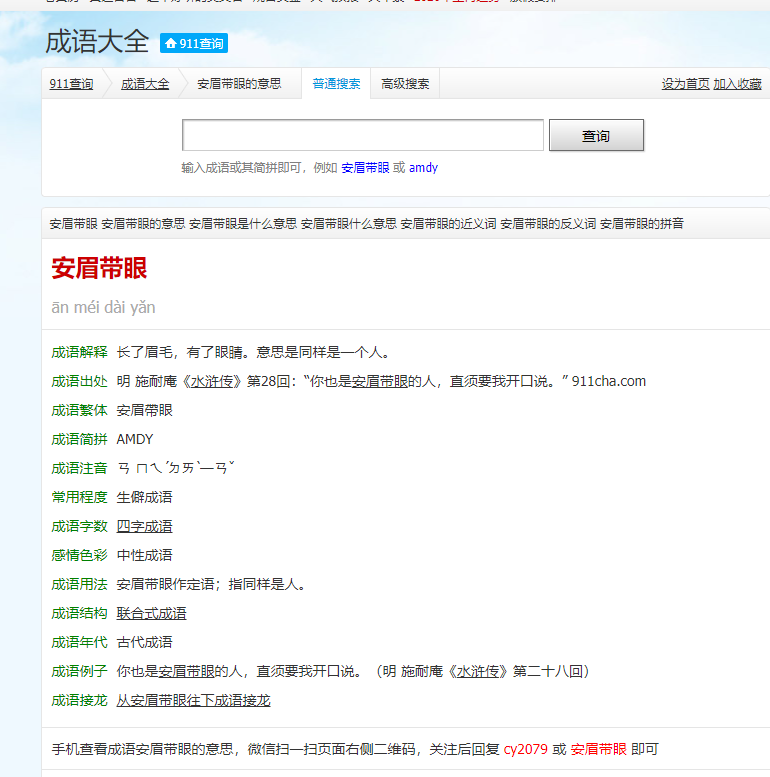
简单说一下就是从图一的a标签中读取详细地址,然后到图二拿取成语具体信息。我就直接po代码了,具体爬数据看页面结构。
from requests_html import HTMLSession # pprint可以把数据打印得更整齐 from pprint import pprint import json import unicodedata #主页面网址 main_url = 'https://chengyu.911cha.com/pinyin_a_p3.html' session = HTMLSession() #headers信息伪装 ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36' re = 'https://chengyu.911cha.com/pinyin_a.html' #主页面html代码 result = session.get(main_url, headers={'user-agent': ua,'referer':re}) #获取主页面html内所有的a标签 a_s = result.html.xpath('/html/body/div[2]/div[1]/div[2]/div[4]/ul/li/a') #打开txt文件(a:追加,w:替换,r:读取) f1 = open('test.txt','a',encoding='utf8') #循环 for a in a_s: #成语的详细地址 href = a.attrs['href'] #拼接成语的详细地址 get_url = 'https://chengyu.911cha.com' + href[1:] session = HTMLSession() #详细成语页面 get_result = session.get(get_url, headers={'user-agent': ua}) #成语 name = get_result.html.xpath('/html/body/div[2]/div[1]/div[2]/div[2]/h2/text()')[0] #有音调的拼音 pinyin = get_result.html.xpath('/html/body/div[2]/div[1]/div[2]/div[2]/div/text()')[0] #无音调的拼音 rpinyin = unicodedata.normalize('NFKD', pinyin).encode('ascii','ignore').decode() #词意 mean = get_result.html.xpath('/html/body/div[2]/div[1]/div[2]/div[3]/p[1]/text()')[0] #保存至txt f1.write('\n{0}|{1}|{2}|{3}'.format(name, pinyin,rpinyin,mean)) print("结束啦")
小tip:xpath就是打开前端Elements,找到想要的html代码,右键=>Copy=>Copy Xpath
结果:

后记:2022年10月看测试人员用JMeter进行接口测试。JMeter也可以爬数据哟!~

