RandLANet
处理大规模点云,可单词处理100万个点
小尺度点云采样方法:最远点采样、逆密度采样
贡献
1、随机采样会造成信息丢失;使用局部特征聚合模块
2、用随机采样在大规模点云上(小尺度用不到)
3、证明baseline上显著的内存和计算收益,在多个大规模基准上超越了目前最先进的语义分割方法
局部特征聚合(Local Feature Aggregation_LFA):
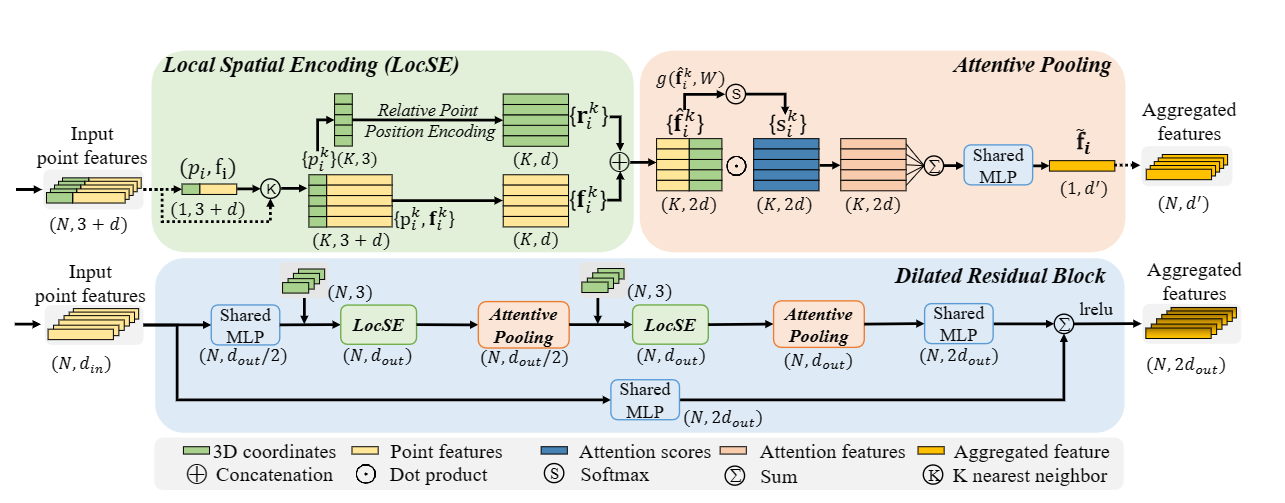
局部空间编码(Local Spatial Encoding)
input:Point Cloud(P)+per-point feature(原始RGB/中间学习特征)
i、找临近点,点Pi,采用简单临近算法(KNN)收集临近点,得到{Pi1……Pik……PiK}
ii、相关点位置编码(学习局部位置特征):
\[r_i^k=MLP(P_i⊕P_i^k⊕(P_i-P_i^k)⊕||P_i-P_i^k||)
\]
\[P_i和P_i^k是对应点的(x,y,z);⊕连接操作;||·||计算临近点和中心点欧氏距离
\]
\[r_i^k是从多余的点位置编码
\]
iii、点特征增强
对每个临近点Pik都得到她对应特征rik,两者相连,的到fik,之后通过LocSE单元输出记为Fik(是向量)
注意力池化
目的:整合临近点特征的几何
使用注意力机制自动学习重要的局部特征
\[input :\vec{F_i}={\vec{f_i^1},\cdots\vec{f_i^k}\cdots\vec{f_i^K}}
\]
i、计算注意力分数
\[s_i^k=g(\vec{f_i^k},W);\quad g():共享的MLP+softmax\quad W:共享MLP的可学习权重
\]
ii、加权求和
\[f_i^{'}=\sum_{k=1}^{k}(\vec{f_i^k}·\vec{s_i^k})
\]
扩展残差块
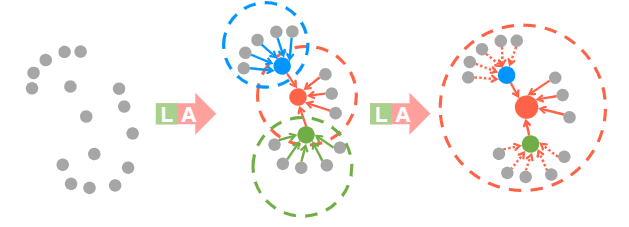
显著低增加每个点的接受域,保留几何细节

 浙公网安备 33010602011771号
浙公网安备 33010602011771号