
视觉识别学习笔记
- Feed forward neural networks (FF or FFNN) and perceptrons (P) 前馈神经网络和感知机
- Radial basis function (RBF)径向基函数网络
- Hopfield网络
- 马尔可夫链 或离散时间马尔可夫链 算是BMs和HNs的雏形
- 玻尔兹曼机,和Hopfield网络
- 受限玻尔兹曼机
- 自动编码
- 稀疏自动编码
- 变分自动编码
- 去噪自动编码
- 深度信念网络
- 卷积神经网络 CNN,图像领域
- 去卷积网络
- 深度卷积逆向图网络3
- 生成对抗网络
- 循环神经网络 RNN,序列数据,音频,语言
- 长短期记忆网络
- 门循环单元
- 神经图灵机
- 双向循环神经网络、双向长短期记忆网络和双向门控循环单元
- 深度残差网络
- 回声状态网络
- 极限学习机
- 液态机
-
Kohonen networks (KN, also self organising (feature) map, SOM, SOFM)
Kohonen 网络
练手网址:练手|常见26种深度学习模型的实现 - 知乎 (zhihu.com)
解释网址:(49条消息) 常用的深度学习模型_杰径通幽的博客-CSDN博客_深度学习模型
结构化数据:表格形式具有清晰的代表意义
非结构化数据:音频、图片,没有清晰代表意义
图像数据库案例名称:CIFAR-10
1、有TensorFlow 官方示例的CIFAR-10 代码文件
2、CIFAR-10 数据集的数据文件名及用途:
| 文件名 | 文件用途 | |
| batches.meta. bet | 文件存储了每个类别的英文名称。可以用记事本或其他文本文件阅读器打开浏览查看 | |
|
data batch I.bin 、 data batch 2.bm 、 …… data batch 5.bin |
这5 个文件是CIFAR- 10 数据集中的训练数据。每个文件以二进制格式存储了10000 张32 × 32 的彩色图像和这些图像 | 对应的类别标签。一共50000 张训练图像 |
| test batch.bin | 这个文件存储的是测试图像和测试图像的标签。一共10000 张 | |
| readme.html | 数据集介绍文件 |
3、基于CIFAR-10数据集最新算法预测准确率对比:Classification datasets results
图像分类:
若:距离的选择:L1distance:d(I1,I2)=∑p |I1p -I2p|
计算方式:test image(矩阵)-training image(矩阵)=pixel-wise absolute value differences(像素绝对值差异)→数值
TensorFlow
操作对照表:(50条消息) Tensorflow一些常用基本概念与函数(1)_林海山波的博客-CSDN博客
神经网络基础
神经网络目标:调整W,
-
线性函数
从输入→输出的映射 ƒ(x,W) =每个类别的得分,(x:image;W:parament(参数))
ƒ(x,W,b) =Wx(+b) 可以得到每个类别的得分
-
损失函数(代价函数)
衡量分类结果准确性
Li=Σj≠yimax(0,sj-syi+1)syi实际类别 sj其他类别 1—代表对损失的容忍程度Δ,Δ越大,对容忍程度越小
损失函数=数据损失+正则化惩罚项(由于权重参数带来的损失)降噪处理
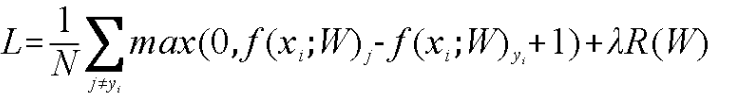
-
Softmax分类器
对W归一化处理,在计算损失值
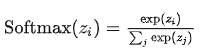
计算损失值:Li = - logP(Y=yi | X=xi)
类别 W exp(W) softmax
-
- cat 3.1 24.5 0.13 Li=-log(0.13)=0.89
- car 5.1 164.0 0.87
- frog -1.7 0.18 0.00
-
激活函数
在逻辑回归外面嵌套一个函数——激活函数
输入的input经过一系列加权求和后作用于另一个函数
向神经网络中引入非线性因素,通过激活函数神经网络就可以拟合各种曲线。
分类:
| 饱和激活函数(Saturated Neurons) | 例如:Sigmoid和Tanh | |
| 非饱和函数(One-sided Saturations) | 可以解决梯度消失问题 | 可以加速收敛 |
激活函数种类 - 潘峰YiRan - 博客园 (cnblogs.com)
-
前向传播
得出损失值:
输入图像→线性函数 分数 →损失函数+R(W)→L损失值
-
梯度下降
例子:(50条消息) 梯度下降算法原理讲解——机器学习_zhangpaopao0609的博客-CSDN博客_梯度下降 array([ 3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12, 11, 13, 13, 16, 17, 18, 17, 19, 21]).reshape(m, 1)#重建为m维数组,一列
主要目的:通过迭代找到目标函数的最小值,或者收敛到最小值
找到梯度最大值的点,朝着梯度相反方向,函数值下降的最快
梯度函数:▽J(Θ)=⟨∂J/∂θ1,∂J/∂θ2,∂J/∂θ3⟩
梯度下降:Θ1=Θ0+α▽J(Θ)
例:J(θ)=θ12+θ22 选择起始点θ0(1,3) 初始学习率:α=0.1
θ0=(1,3)
θ1 = θ 0 − α ∗ J ′ ( θ 0 ) = (1,3) −0.1*(2,6)= (0.8,2.4)
θ 2 = θ 1 − α ∗ J ′ ( θ 1 ) = (0.8,2.4)−0.1*(1.6,4.8) =(0.64,1.92)
θ 3 = (0.5124,1.536)
θ 4 = (0.4096,1.22880000000001)
……
-
反向传播
通过构造输出值与真实值的损失函数作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯度,作为修改权值的依据,网络的学习在权值修改过程中完成。输出值与真实值的误差达到所期望值时,网络学习结束。
链式法则
梯度是一步一步传的
-
- 加法门单元:均等分配 x+y 求导
- MAX门单元:给最大值
- 乘法门单元:互换的感觉 xy 求导
神经网络
数据二分类:可视化:对玩具 2D 数据进行分类 (stanford.edu)
-
整体架构
层次结构+神经元+全连接+非线性
非线性:
-
正则化
惩罚力度:力度越大,分类界限越规则
-
激活函数
激活函数——非线性变化
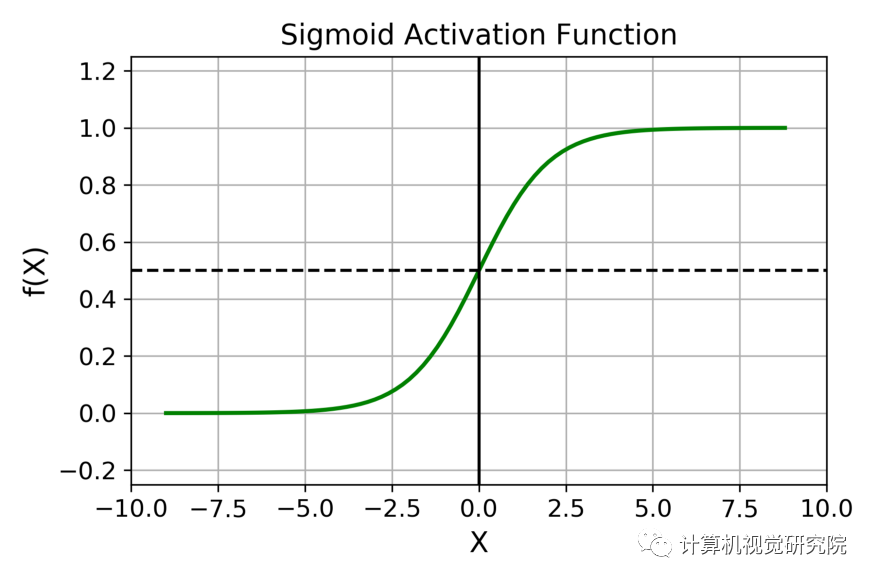
sigmoid:
relu:
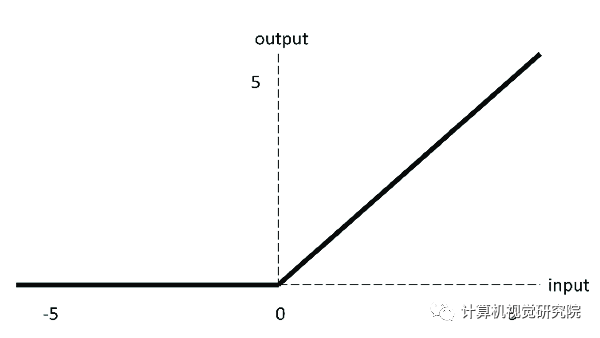 f(x)=max(0,x)
f(x)=max(0,x)
-
数据预处理
例:标准化
去中心化
-
参数初始化
通常用随机策略来进行参数初始化
W=0.01*np.random.randn(D,H)
-
DROP-OUT(传说中的七伤拳)
过拟合是神经网络非常头痛的一个大问题,所以在每一次训练时,在每层上随机删除几个神经元

 浙公网安备 33010602011771号
浙公网安备 33010602011771号