github博客传送门
csdn博客传送门
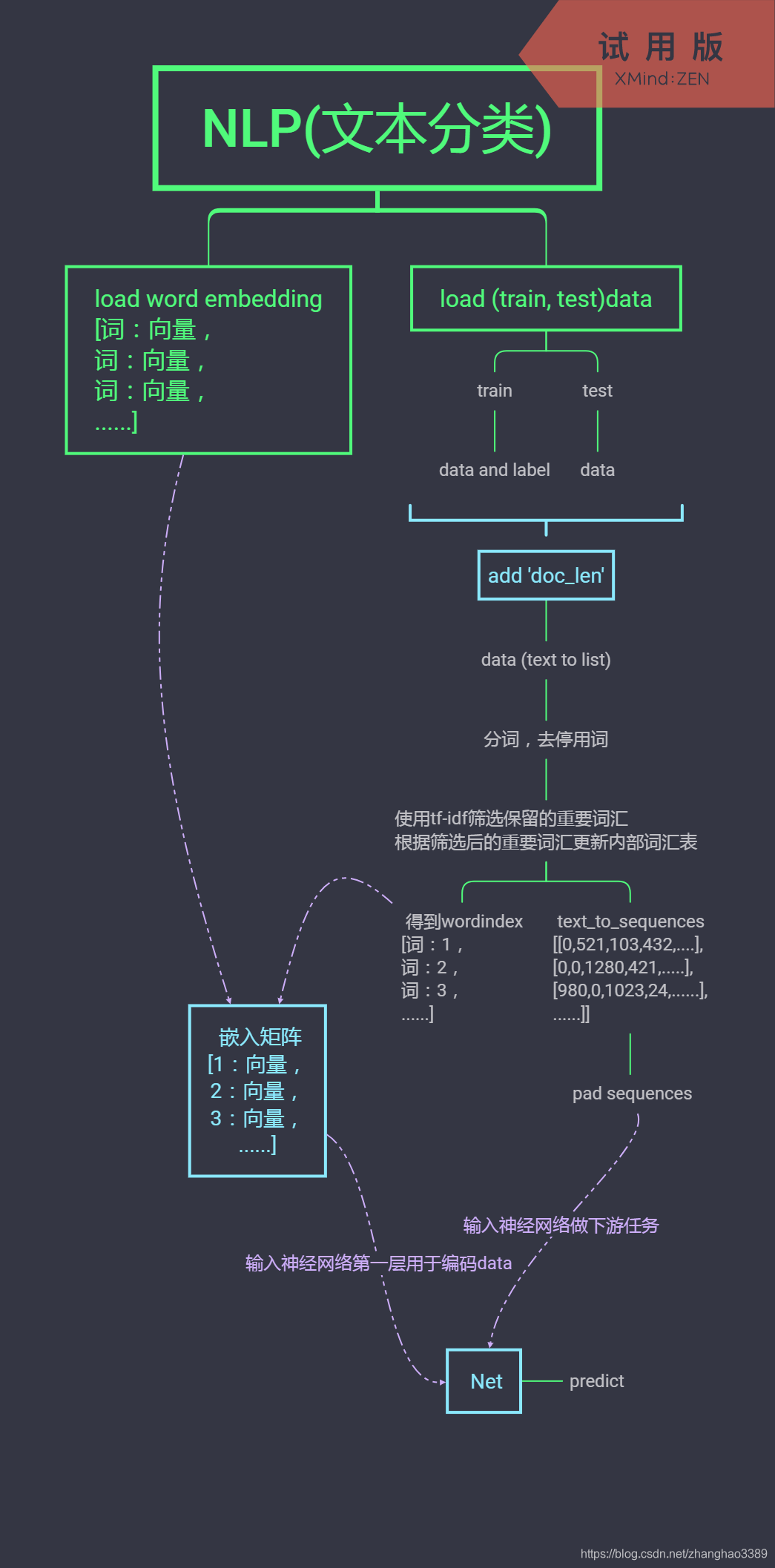
- 加载词嵌入矩阵(一般情况为字典形式 {词0:300维的向量, 词1:300维的向量, 词2:300维的向量...})
- 加载任务数据(一般情况为字符串形式 "我喜欢编程" 或者 "I love play computer")
- 对加载的所有任务数据求一个最大字符串长度 以便后面将所有数据填充至一样的长度
- 将每条数据以每个样本的形式存入列表 ["我在家", "他在打球", "I am tired"...]
- 对每个样本 进行分词 例如: (分词前["我在天安门"]) (分词后["我","在","天安门"]) #仅供参考
- 对每个样本去停用词 例如:(去停用词前["他", "在", "美丽", "的", "草坪", "下", "晒", "太阳"]) (去停用词后["他", "在", "草坪", "晒", "太阳"]) #仅供参考不一定正确
- 对所有的词汇汇总 使用tf-idf(当然还有其它的方法不止tf-idf这一种,tf-idf具体原理自己google)对词汇加权等等一堆东西 算出前10000(根据任务自己设定词嵌入的大小) 一般为字典形式
- 同时将数据转换为 词 对应 7 步骤字典中的序号 例如(["我", "在", "家"]) 转换后可能为([14, 383, 2015])
- 将 8 步骤转换后的数据 padding 为 3 步骤最大长度以便神经网络收到同一长度(padding 0)
- 用第 1 步骤得到的词嵌入 和 第 7 步骤得到的汇总词汇的索引取出一个嵌入矩阵随后对所有的训练数据进行编码 形如
- 最后将 10 步骤的词嵌入矩阵加载到神经网络的第一层(并设置为不训练)对所有数据进行编码.
- 接着就可以使用神经网络对数据进行训练并预测啦.
print_r('点个赞吧');
var_dump('点个赞吧');
NSLog(@"点个赞吧!")
System.out.println("点个赞吧!");
console.log("点个赞吧!");
print("点个赞吧!");
printf("点个赞吧!\n");
cout << "点个赞吧!" << endl;
Console.WriteLine("点个赞吧!");
fmt.Println("点个赞吧!")
Response.Write("点个赞吧");
alert(’点个赞吧’)



