

29、springboot与检索(1)
一、检索
我们的应用经常需要添加检索功能,开源的 ElasticSearch 是目前全文搜索引擎的首选。
他可以快速的存储、搜索和分析海量数据。Spring Boot通过整合Spring Data ElasticSearch
为我们提供了非常便捷的检索功能支持;
Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,
采用多shard(分片)的方式保证数据安全,并且提供自动resharding的功能,
github等大型的站点也是采用了ElasticSearch作为其搜索服务,
二、ElasticSearch
1、使用docker下载ElasticSearch
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name es1 4f7e4c61f09d
这里的-e是设置初始化时的内存,不设置时开启时需要较大的内存!!!
测试:
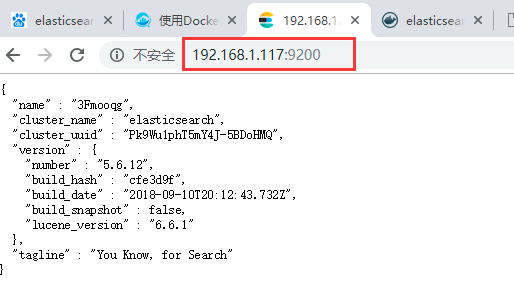
出现上述图文即表示服务开启成功!!!
2、Elasticsearch相关使用和用法
Elasticsearch 是 面向文档 的,意味着它存储整个对象或 文档_。Elasticsearch 不仅存储文档,
而且 _索引 每个文档的内容使之可以被检索。在 Elasticsearch 中,你 对文档进行索引、
检索、排序和过滤--而不是对行列数据。这是一种完全不同的思考数据的方式,
也是 Elasticsearch 能支持复杂全文检索的原因。
JSON编辑
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。
JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读
一个 Elasticsearch 集群可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。
这些不同的类型存储着多个 文档 ,每个文档又有多个 属性 。
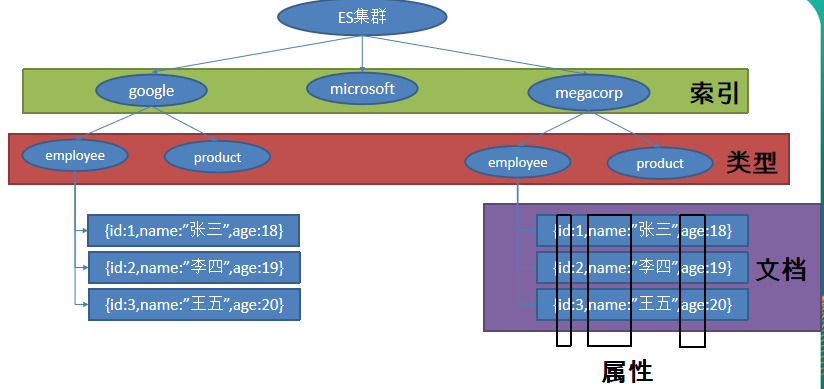
对于雇员目录,我们将做如下操作:
- 每个雇员索引一个文档,包含该雇员的所有信息。
- 每个文档都将是 employee 类型 。
- 该类型位于 索引 megacorp 内。
- 该索引保存在我们的 Elasticsearch 集群中。
megacorp- 索引名称
employee- 类型名称
1- 特定雇员的ID
- 测试:
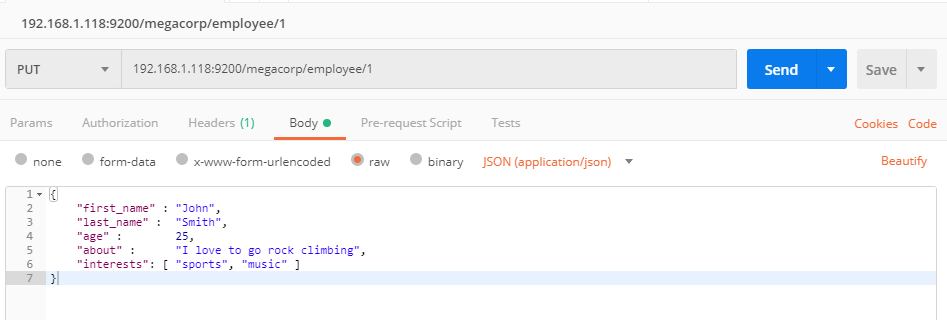
此时的相应:
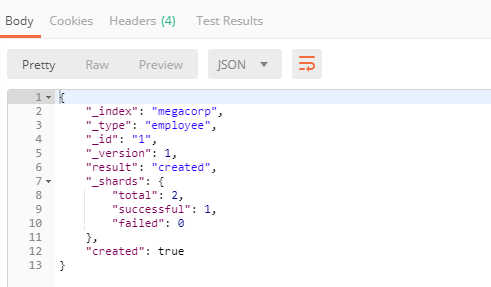
此时在加入两条数据:

检索文档
目前我们已经在 Elasticsearch 中存储了一些数据, 接下来就能专注于实现应用的业务需求了。
第一个需求是可以检索到单个雇员的数据。
这在 Elasticsearch 中很简单。简单地执行 一个 HTTP GET 请求并指定文档的地址——索引库、
类型和ID。 使用这三个信息可以返回原始的 JSON 文档:
GET /megacorp/employee/1
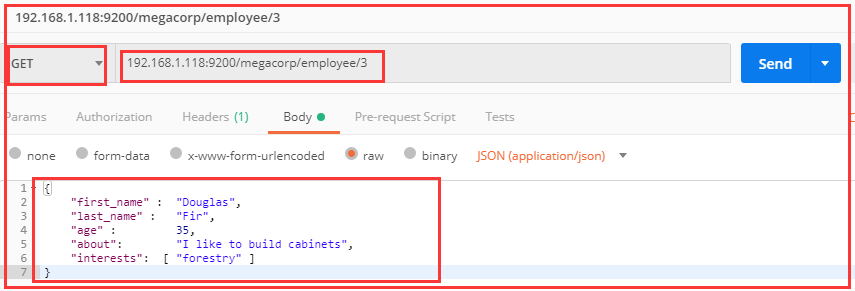
HEAD是检验是否存在
DELETA是删除
将 HTTP 命令由 PUT 改为 GET 可以用来检索文档,同样的,
可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。
如果想更新已存在的文档,只需再次 PUT 。
轻量搜索
一个 GET 是相当简单的,可以直接得到指定的文档。 现在尝试点儿稍微高级的功能,
比如一个简单的搜索!
第一个尝试的几乎是最简单的搜索了。我们使用下列请求来搜索所有雇员:
GET /megacorp/employee/_search
192.168.1.118:9200/megacorp/employee/_search
注意:返回结果不仅告知匹配了哪些文档,还包含了整个文档本身:显示搜索结果给最终用户所需的全部信息。
使用查询表达式搜索
更复杂的搜索
全文搜索
短语搜索
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询
高亮搜索

