

Redis主从复制
Redis的复制(Master/Slave)
是什么:
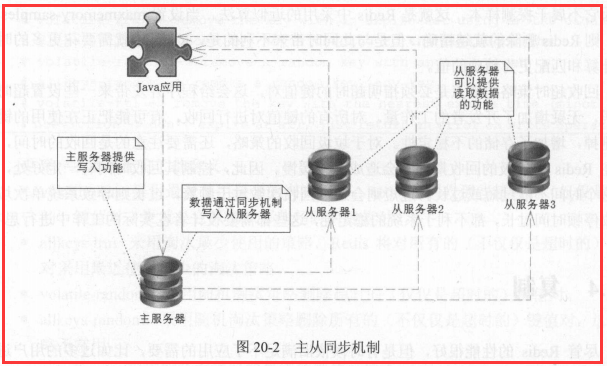
行话:也就是我们所说的主从复制,主机数据更新后根据配置和策略,
自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
-在多台数据服务器中,只有 台主服务器,而主服务器只负责写入数据,不负责让
外部程序读取数据
-存在多台从服务器,从服务器不写入数据,只负责同步主服务器的数据,并让外部
程序读取数据。
-主服务器在写入数据后,即刻将写入数据的命令发送给从服务器,从而使得主从数
据同步。
-应用程序可以随 读取某 台从 务器的数据, 这样就分摊了读数据的压力。
-当从服务器不能工作的时候,整个系统将不受影响: 当主服务器不能工作的时候,
可以方便地从从服务器中选举 台来当主服务器
能干吗:
读写分离
容灾恢复
常用3招
a.一主二仆
b.薪火相传
c.反客为主
一主二仆
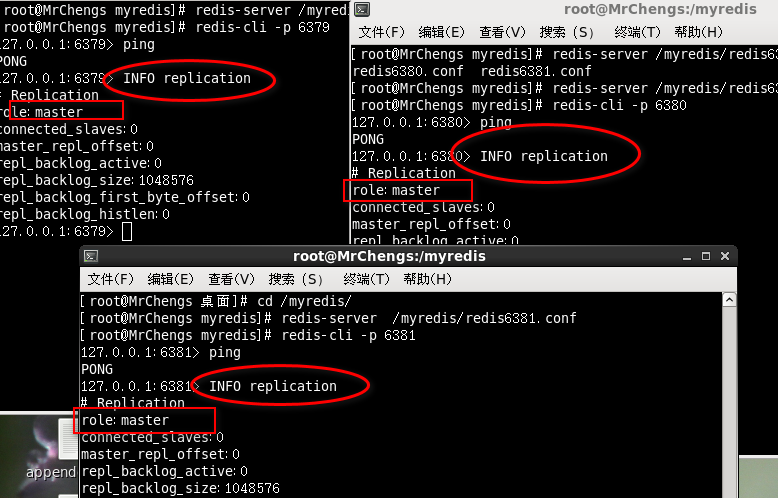
一个Master两个Slave
日志查看:主机日志,备机日志, info replication
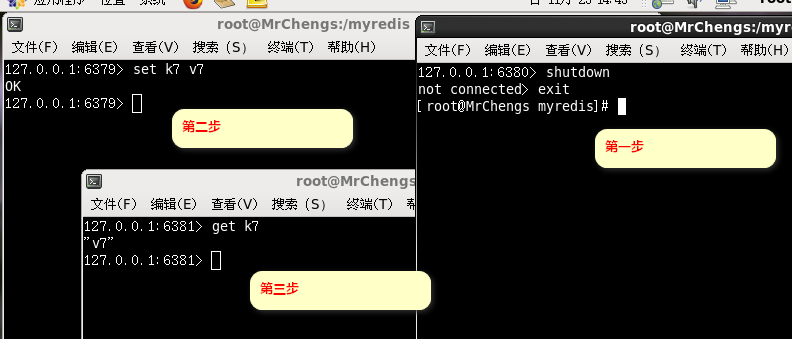
主从问题演示
测试:修改配置文件实现三个端口同时开启服务
INFO replication
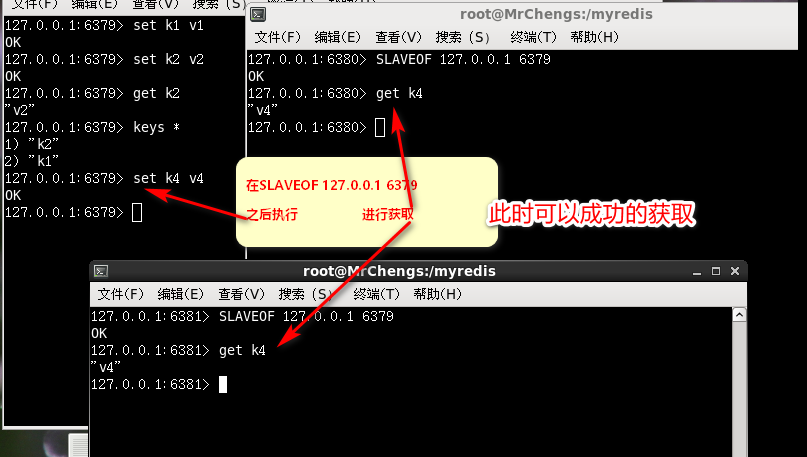
SLAVEOF 127.0.0.1 6379
从机执行备份
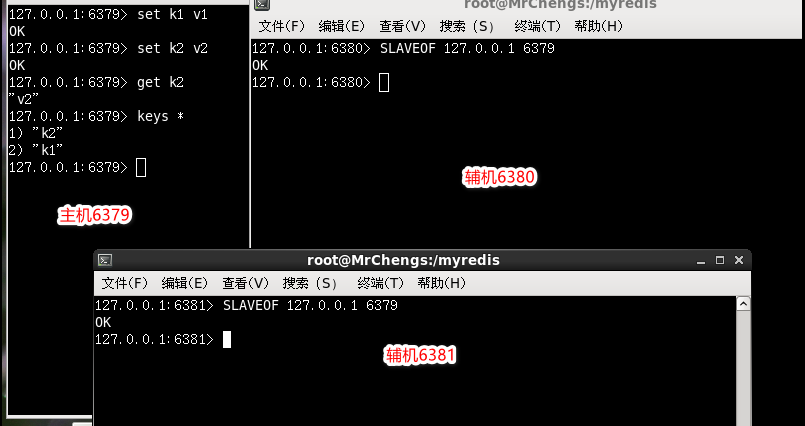
在从主机同步之后的从机
在获取主机新建的数据,依然能得到
从机从头到尾复制备份
INFO replication

此时出现的问题
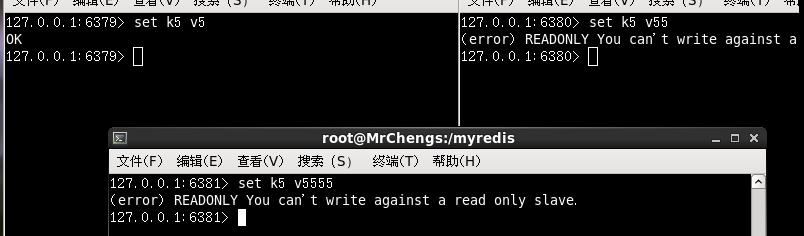
主机和两个从机同时执行下面的命令
set k5 v5
此时只有主机可以写,从机报错
主机出问题:
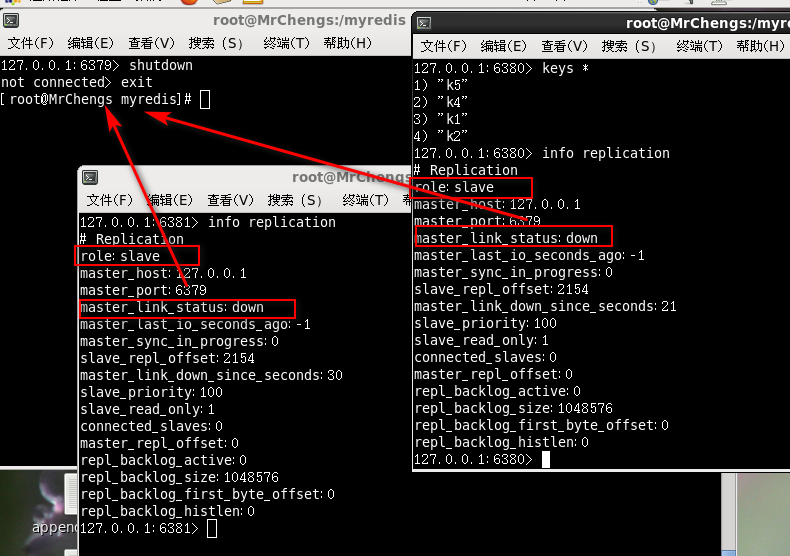
从机何去何从
从机依然存在,坚守岗位,但是连接状态改变
从机的数据依然存在
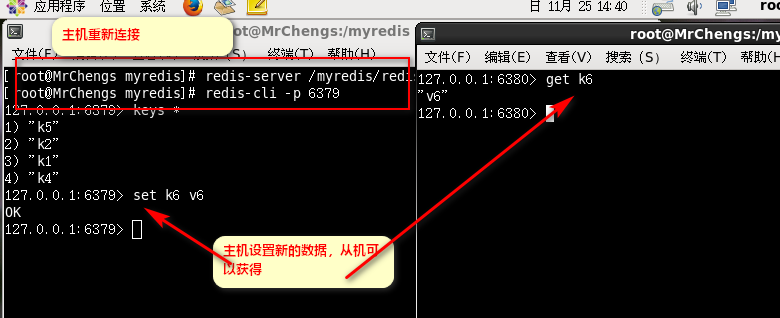
主机重新上线
从机依然可以获取到最新的主机的数据
从机会一直待命等待主机的回来
从机出现问题:
假设80从机死了
81可以获取最新的数据
每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
info replication
SLAVEOF 127.0.0.1 6379
薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他slaves的连接和同步请求,
那么该slave作为了链条中下一个的master,可以有效减轻master的写压力
中途变更转向:会清除之前的数据,重新建立拷贝最新的
slaveof 新主库IP 新主库端口
现在就是:
79 --> 80 --> 81

反客为主
SLAVEOF no one
使当前数据库停止与其他数据库的同步,转成主数据库
测试的前提是回到一主二仆
此时主机死了
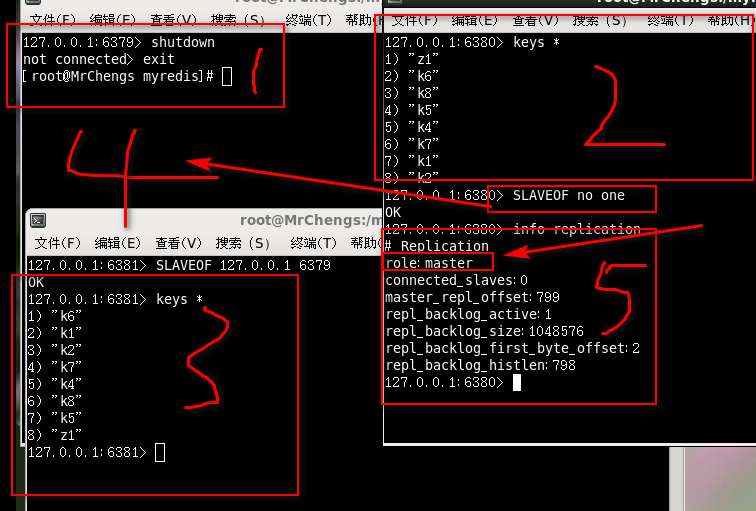
此时80上位
81继而连接81

此时79主机回来
依然是主机但是和80 81已经不是一个体系

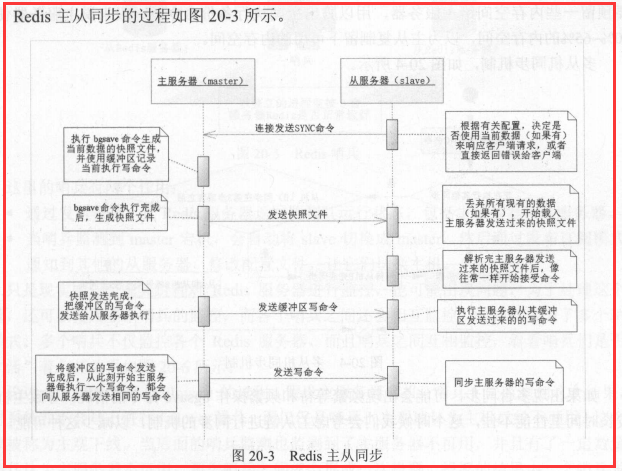
复制原理
slave启动成功连接到master后会发送一个sync命令
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,
在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,
在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
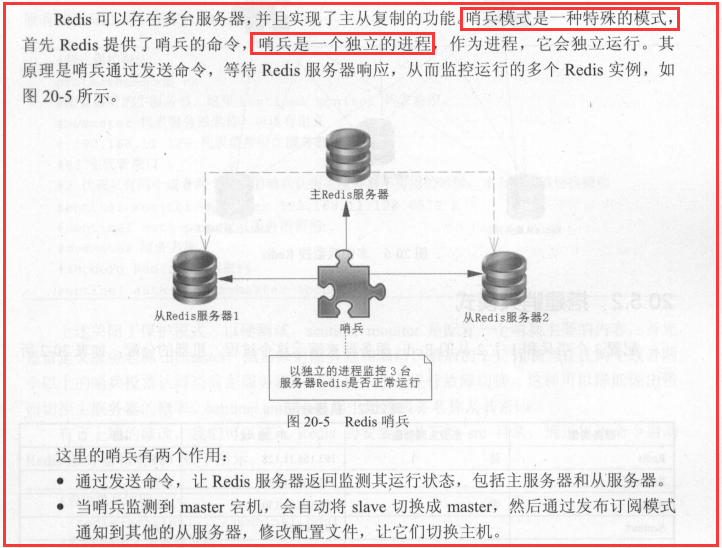
哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
一组sentinel能同时监控多个Master
1.调整结构,6379带着80、81
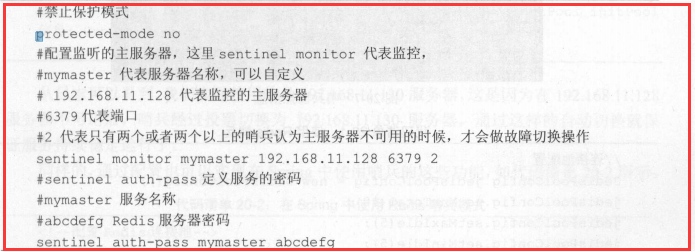
2.自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错-----》touch sentinel.conf
3.配置哨兵,填写内容
a.sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1
b.面最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机
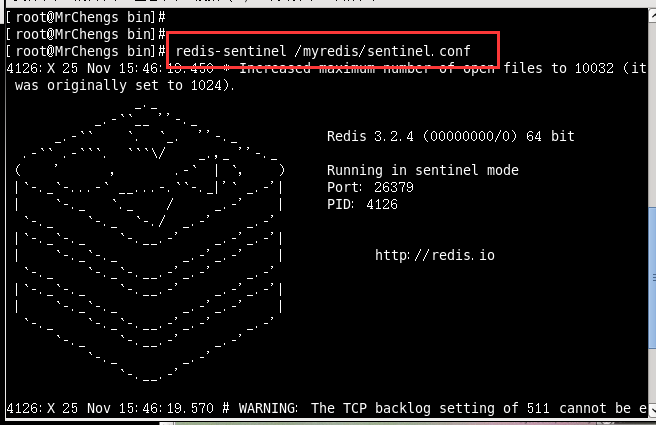
4.启动哨兵
a.redis-sentinel /myredis/sentinel.conf
b.上述目录依照各自的实际情况配置,可能目录不同
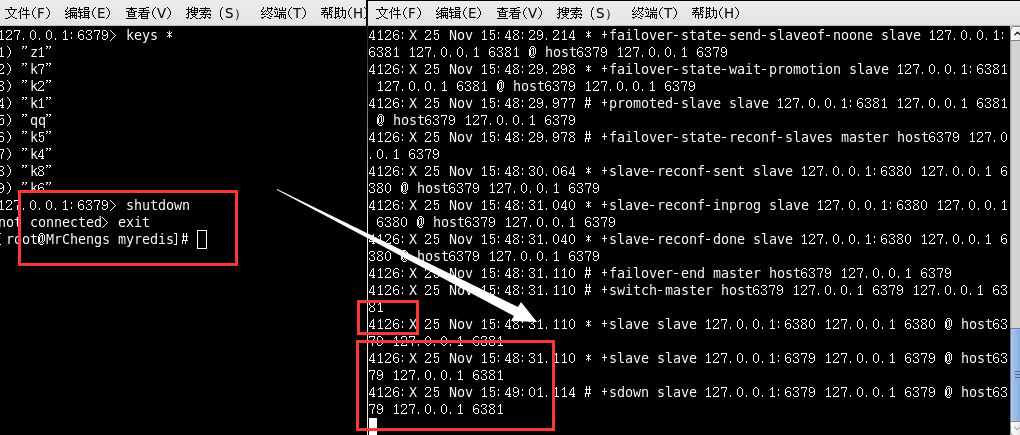
此时79关机
哨兵检测到79问题
此时让81充当主机
此时80 81自称一套体系


此时79重新上线
此时79成为slave成为81的从机

复制的缺点
复制延时:
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,
当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。

