到底为什么不要用SELECT *
# SELECT *
无论工作还是面试,说到sql优化,比说的一个问题就是,代码中sql不要出现 SELECT *,之前一直也没有深入去研究研究,为什么,只是记住了,代码中注意了,但是就在今天逛某某论坛时,又看到有同学在发布这样的经验分享,读完,有感觉模模糊糊,懵懵懂懂。
遂下定决心,整理一篇,为什么不要使用**SELECT * **,直接进入正。
一、为什么不要使用_SELECT *_
首先我们参考一下《阿里java开发手册(泰山版)》中 MySQL 部分描述:
4 - 1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:
- 增加查询分析器解析成本。
- 增减字段容易与 resultMap 配置不一致。
- 无用字段增加网络 消耗,尤其是 text 类型的字段。
在阿里的开发手册中,大面的概括了上面几点。
二、详细解读原因
1. 使用 * 号查询,会查询出多个我们不需要的字段,增加sql执行的时间,同时大量的多余字段,会增加网络开销
-
用
“SELECT * ”数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担 -
"SELECT * "经常会带上无用且大文本字段(比如LOG,),当出现这情况时,对于网络开销来说,是一种巨大的负担,甚至网络开销会几何倍数增加,另外如果DB和应用程序不在同一台机器,这种开销非常明显 -
即使 mysql 服务器和客户端是在同一台机器上,使用的协议还是 tcp,通信也是需要额外的时间。
2.对于无用的大字段,如 varchar、blob、text,会增加 io 操作
- 准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式。
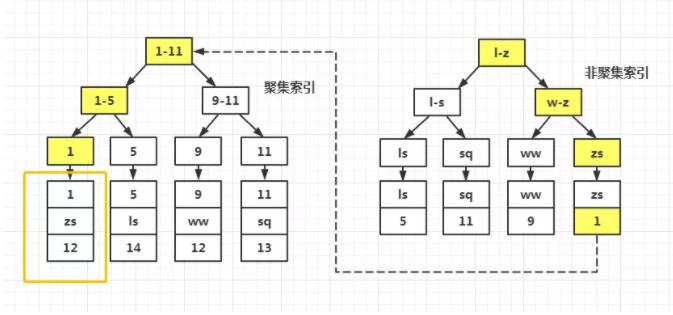
例如:有一个表为t(a,b,c,d,e,f),其中,a为主键,b列有索引。
- 这种情况,首先我们要搞明白,mysql会给我们创建那些索引;
- 我们知道在mysql中(Innodb引擎)聚集索引是一定存在的,如果表结构中定义了主键,聚集索引就根据主键建立,否则如果有唯一列就用唯一列,否则就会自动在每条记录中生成一个隐藏的ID列并以此建立聚集索引,聚集索引的叶子节点就是真实的数据。
- 因此上面的示例会创建两种索引:1、聚集索引(a,b,c,d,e,f) 2、联合索引(a,b)[这里也包含单列索引]
- 当我们查询的时候,走索引的大致流程分两步,一是先根据索引列在联合索引树中找到ID,然后根据ID在聚集索引中找到对应的记录(这一步也称为回表)
- 根据上面查询索引过程就会发现问题,也就是联合索引中其实已经包含了a,b字段的数据。那如果我查询语句中查询的就是这两个字段的数据,并且搜索条件中也是这两列中的一列,那我还有必要分两步操作吗?还有必要进行回表操作吗?需要在联合索引树中进行搜索即可以对于这种情况,如果用
select a,b from table where a = '1'这种指定列的查询只需走联合索引中的单列索引即可,无需回表,并且索引的每条记录不含有隐藏列,加载内存的操作会更快如果用select *的话,因为联合索引树中并没有c等其它字段,所以根本走不了联合索引,只能对聚集索引进行全表扫描,在数据量大的情况下,性能影响还是很可观的。 - 如果用户使用
SELECT*,获取了不需要的数据,则首先通过辅助索引过滤数据,然后再通过聚集索引获取所有的列,这就多了一次b+树查询,速度必然会慢很多。
- 由于辅助索引的数据比聚集索引少很多,很多情况下,通过辅助索引进行覆盖索引(通过索引就能获取用户需要的所有列),都不读磁盘,直接从内存取,而聚集索引很可能数据在磁盘(外存)中(取决于buffer pool的大小和命中率),这种情况下,一个是内存读,一个是磁盘读,速度差异就很显著了,几乎是数量级的差异。
2.连接查询时,使用*无法进入缓冲池
- mysql中连接查询的原理是先对驱动表进行查询操作,然后再用从驱动表得到的数据作为条件,逐条的到被驱动表进行查询。
- 每次驱动表加载一条数据到内存中,然后被驱动表所有的数据都需要往内存中加载一遍进行比较。效率很低,所以mysql中可以指定一个缓冲池的大小,缓冲池大的话可以同时加载多条驱动表的数据进行比较,放的数据条数越多性能io操作就越少,性能也就越好。所以,如果此时使用
select *放一些无用的列,只会白白的占用缓冲空间。浪费本可以提高性能的机会。
索引知识延伸
1.联合索引
1.1联合索引认识
mysql索引比较简单的是单列索引(b+tree)。遇到多条件查询时,不可避免会使用到多列索引。联合索引又叫复合索引
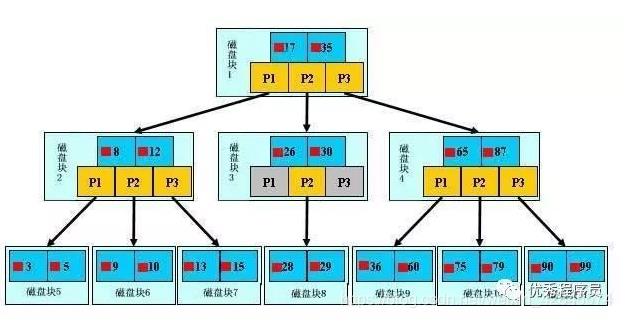
b+tree结构如下图
每一个磁盘块在mysql中是一个页,页大小是固定的,mysql innodb的默认的页大小是16k,每个索引会分配在页上的数量是由字段的大小决定。当字段值的长度越长,每一页上的数量就会越少,因此在一定数据量的情况下,索引的深度会越深,影响索引的查找效率。
对于复合索引(多列b+tree,使用多列值组合而成的b+tree索引)。遵循最左侧原则,从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a a,b a,b,c 3种组合进行查找,但不支持 b,c进行查找。当使用最左侧字段时,索引就十分有效。
创建表test如下:
create table test(
a int,
b int,
c int,
KEY a(a,b,c));
- 查(a,b,c)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(a=? and b=? and c=?)这样的数据来检索的时候,b+树会优先比较a列来确定下一步的所搜方向,如果a列相同再依次比较b列和c列,最后得到检索的数据;但当(b=? and c=?)这样的没有a列的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候a列就是第一个比较因子,必须要先根据a列来搜索才能知道下一步去哪里查询。比如当(a=? and c=?)这样的数据来检索时,b+树可以用a列来指定搜索方向,但下一个字段b列的缺失,所以只能把a列的数据找到,然后再匹配c列的数据了, 这个是非常重要的性质,即索引的最左匹配特性。以下通过例子分析索引的使用情况,以便于更好的理解联合索引的查询方式和使用范围
1.2多列索引在and查询中应用
select * from test where a=? and b=? and c=?;查询效率最高,索引全覆盖。
select * from test where a=? and b=?;索引覆盖a和b。
select * from test where b=? and a=?;经过mysql的查询分析器的优化,索引覆盖a和b。
select * from test where a=?;索引覆盖a。
select * from test where b=? and c=?;没有a列,不走索引,索引失效。
select * from test where c=?;没有a列,不走索引,索引失效。
1.3多列索引在范围查询中应用
select * from test where a=? and b between ? and ? and c=?;索引覆盖a和b,因b列是范围查询,因此c列不能走索引。
select * from test where a between ? and ? and b=?;a列走索引,因a列是范围查询,因此b列是无法使用索引。
select * from test where a between ? and ? and b between ? and ? and c=?;a列走索引,因a列是范围查询,b列是范围查询也不能使用索引。
1.4多列索引在排序中应用
select * from test where a=? and b=? order by c;a、b、c三列全覆盖索引,查询效率最高。
select * from test where a=? and b between ? and ? order by c;a、b列使用索引查找,因b列是范围查询,因此c列不能使用索引,会出现file sort。
1.5联合索引的优势
- 减少开销
- 建一个联合索引 (a,b,c) ,实际相当于建了 (a)、(a,b)、(a,b,c) 三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销
- 覆盖索引
对联合索引 (a,b,c),如果有如下 sql 的,
SELECT a,b,c from table where a='xx' and b = 'xx';
- 那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机 io 操作。减少 io 操作,特别是随机 io 其实是 DBA 主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
- 效率高
索引列多,通过联合索引筛选出的数据越少。比如有 1000W 条数据的表,有如下SQL:
select col1,col2,col3 from table where col1=1 and col2=2 and col3=3;
假设:假设每个条件可以筛选出10% 的数据。
- A. 如果只有单列索引,那么通过该索引能筛选出
1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页,以此类推(递归); - B. 如果是(col1,col2,col3)联合索引,通过三列索引筛选出
1000w10% 10% *10%=1w,效率提升可想而知!
索引是建的越多越好吗
答案自然是否定的
* 数据量小的表不需要建立索引,建立会增加额外的索引开销
* 不经常引用的列不要建立索引,因为不常用,即使建立了索引也没有多大意义
* 经常频繁更新的列不要建立索引,因为肯定会影响插入或更新的效率
* 数据重复且分布平均的字段,因此他建立索引就没有太大的效果(例如性别字段,只有男女,不适合建立索引)
* 数据变更需要维护索引,意味着索引越多维护成本越高。
* 更多的索引也需要更多的存储空间
1.6联合索引小结
- 总结联合索引的使用在写where条件的顺序无关,mysql查询分析会进行优化而使用索引。但是减轻查询分析器的压力,最好和索引的从左到右的顺序一致。使用等值查询,多列同时查询,索引会一直传递并生效。因此等值查询效率最好(无需回表,)。索引查找遵循最左侧原则。但是遇到范围查询列之后的列索引失效。排序也能使用索引,合理使用索引排序,避免出现file sort。
其他
select中要不要使用 *
除了极少数情况下,绝大多数情况下,使用 * 是一种糟糕的编程习惯!
分析如下:
1、如果采用 select * 进行查找时,查询到的列是按照它们在表的原始位置展示的;如果客户端同样采用列的原始位置进行引用,如果更改表结构,会导致难以察觉的错误;
2、使用 * 时,数据库会先查数据字典,明确 * 代表什么,这会在分析阶段造成大量开销;
3、select * 最大的问题是可能会多出一些不用的列,导致无法使用索引覆盖,导致查询成本几何层级的增加
4、不需要的字段会增加数据传输的时间,如果是本地客户端,连接的事本地的mysql服务器,tcp协议传输数据会增加额外时间;如果是db和客户端不在同一台机器,比如连接到阿里云,则开销会更加明显
5、如果查询的时候获取了不必要的列,字段较多时,mysql并非一次性保存,而是主次分布内存,当时用完后,再次分配。如此会导致多次分配,频繁分配会增加额外消耗时间
6、如果sql语句复杂,select * 会解析更多的对象,字段,权限,属性等内容,增加数据库负担

 浙公网安备 33010602011771号
浙公网安备 33010602011771号