clickhouse压缩与编码
1.通用编码
None:无压缩
LZ4:默认的压缩算法,缺省值也是使用默认的压缩算法
LZ4HC[(level)]:z4高压缩率压缩算法版本, level默认值为9,支持[1~12],推荐选用[4~9]
ZSTD[(level)]:zstd压缩算法,level默认值为1,支持[1~22]
2.特殊编码
LowCardinality:枚举值小于1w的字符串
Delta:时间序列类型的数据,不会对数据进行压缩
T64:比较适合Int类型数据
DoubleDelta:适用缓慢变化的序列:比如时间序列,对于递增序列效果很好
Gorilla:使用缓慢变化的数值类型
特殊编码与通用的压缩算法相比,区别在于,通用的LZ4和ZSTD压缩算法是普适行的,不关心数据的分布特点,而特殊编码类型对于特定场景下的数据会有更好的压缩效果。
3.使用
压缩算法和特殊编码两者可以结合起来一起使用
CREATE TABLE k19_ods.test8 ( `found _time` Uint32, `recv_timet` UInt32 CODEC ( NONE ), `recv_time2` UInt32, `recv_time3` Ulnt32 CODEC ( LZ4 ), `recv_time4` UInt32 CODEC (LZ4HC ( 9 )), `recv_time5` UInt32 CODEC (ZSTD ( 9 ), `recv_time6` Ulnt32 CODEC ( T640 ), `name0` String CODEC (Delta (, LZ4 ), `name1` String CODEC ( DoubleDelta0 )), `name2` String CODEC ( Gorilla ( 0 ), `name4` String cODEC ( Gorilla ), Lz4 ) ) ENGINE = MergeTree () PARTITION BYtoYYYYMMDD ( toDateTime(found_time )) ORDER BY found_time
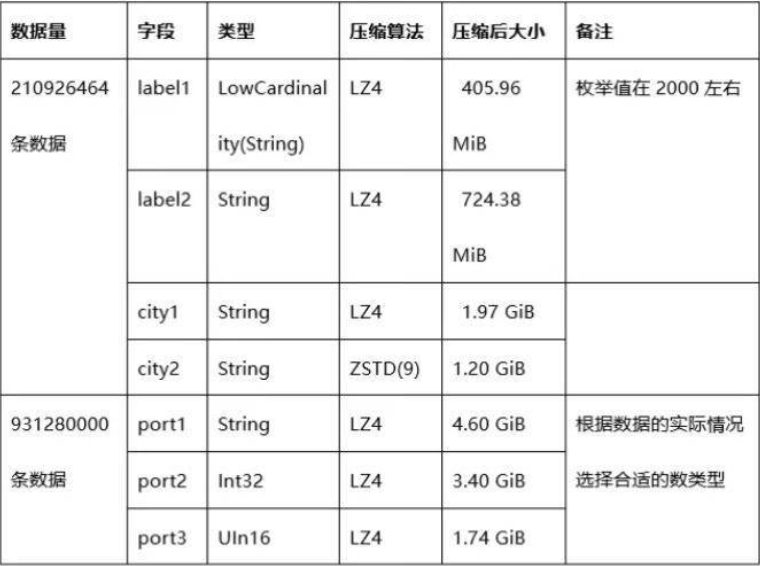
4.压缩效果对比
需要注意一点就是,对于LZ4HC和ZSTD选择的压缩level越高,压缩效果越好,但是CPU的使用率也会相应的越高。如果插入的数据量很大,会明显看到较高的CPU使用率。