
clickhouse配置query_log查询记录
配置针对的是集群中所有机器,注意保持集群各个服务器设置日志保持统一。
一、配置步骤
1.打开clickhouse的users.xml文件,在profiles中加入<log_queries>1</log_queries>

2.打开config.xml文件,在yandex中加入query_log的配置
<query_log> <database>system</database> <table>query_log</table> <partition_by>toYYYYMM(event_date)</partition_by> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log>
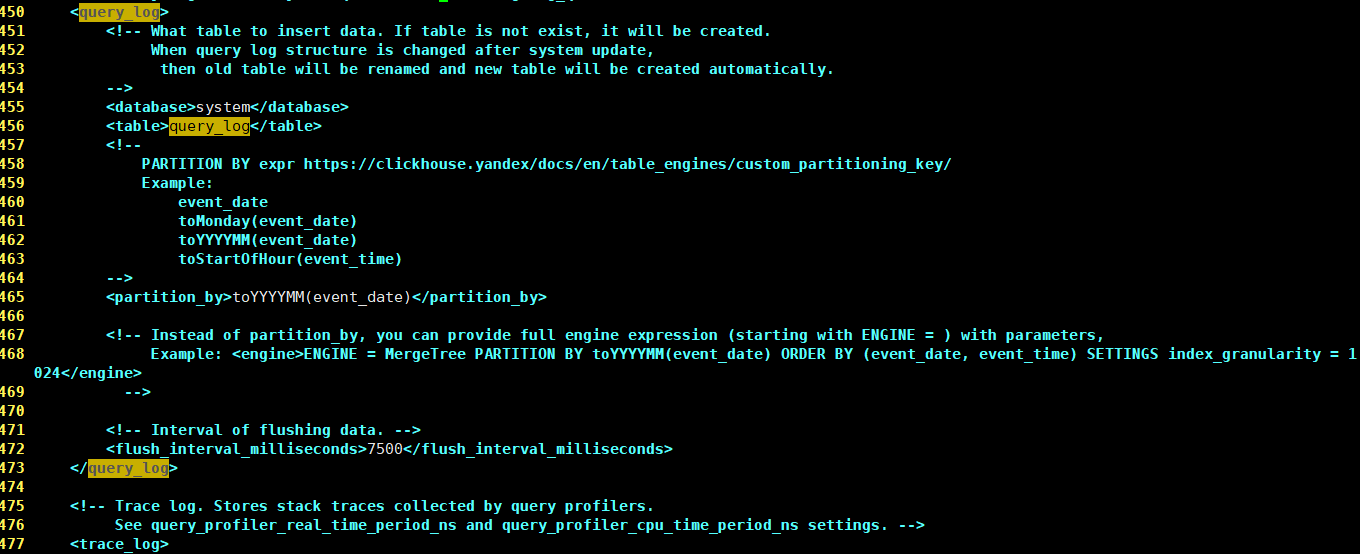
如添加上述参数之后表不自动创建,重启clickhouse-server服务即可。
partition_by表示查询日志表的分区列,语法与普通建表时相同,默认按月分区。flush_interval_milliseconds则表示日志刷入表中的周期,默认7.5秒,可以根据取数时效自己调节。
3.配置一个分布式表,用来外部查询
CREATE TABLE IF NOT EXISTS system.query_log_all ON CLUSTER yk_ck_cluster AS system.query_log ENGINE = Distributed(yk_ck_cluster,system,query_log,rand())
4.配置过期TTL
由于query_log表没有自动清理功能,为了防止日志表过大占用太多的内存,设置一个自动清理表数据的TTL。
ALTER TABLE system.query_log on cluster yk_ck_cluster MODIFY TTL event_date + INTERVAL 15 DAY
二、query_log内容介绍
1.system.query_log注册了两种查询:
1)由客户端直接运行的初始查询。
2)由其他查询发起的子查询(分布式查询执行)。对于这些类型的查询,有关父查询的信息显示在initial_*列中。
2.每个查询会在query_log表中创建1-2行,取决于查询的状态:
1)如果查询执行成功,将创建两个类型为1和2的事件(参考type列)。
2)如果查询处理过程中发生错误,将创建两个类型为1和4的事件。
3)如果查询运行前发生错误,将只创建一个类型为3的事件。
3.默认情况下,每隔7.5秒向表添加一次日志。可以在query_log服务器设置中设置这个时间间隔(参考flush_interval_milliseconds参数)。要将日志从内存缓冲区强制刷新到表中,可以使用SYSTEM FLUSH LOGS。
列信息介绍:

type (Enum8) — 执行查询时发生的事件类型。 ‘QueryStart’ = 1 — 查询执行成功开始。 ‘QueryFinish’ = 2 — 查询执行成功结束。 ‘ExceptionBeforeStart’ = 3 — 在开始执行查询之前发生异常。 ‘ExceptionWhileProcessing’ = 4 — 查询执行期间的异常。 event_date (Date) — 查询开始日期。 event_time (DateTime) — 查询开始时间。 query_start_time (DateTime) — 查询执行开始时间。 query_duration_ms (UInt64) — 查询执行持续时间。 read_rows (UInt64) — 读取的行数。 read_bytes (UInt64) — 读取的字节数。 written_rows (UInt64) — 对于插入查询,写入的行数。对于其他查询,值为0。 written_bytes (UInt64) — 对于插入查询,写入的字节数。对于其他查询,值为0。 result_rows (UInt64) — 结果中的行数。 result_bytes (UInt64) — 结果中的字节数。 memory_usage (UInt64) — 查询消耗的内存。 query (String) — 查询字符串。 exception (String) — 异常信息。 stack_trace (String) — 堆栈调用信息(在发生错误之前调用的方法列表)。如果查询成功完成,则为空字符串。 is_initial_query (UInt8) — 查询类型。可能的取值: 1 — 查询由客户端发起。 0 — 查询由另一个查询发起,用于分布式查询执行。 user (String) — 发起当前查询的用户的名称。 query_id (String) — 查询ID。 address (IPv6) — 发起查询的IP地址。 port (UInt16) —发起行查询的客户端端口。 initial_user (String) — 运行初始查询的用户名(用于分布式查询执行)。 initial_query_id (String) — 初始查询的ID(用于分布式查询执行)。 initial_address (IPv6) — 启动父查询的IP地址。 initial_port (UInt16) — 发起父查询的客户端端口。 interface (UInt8) — 发起查询的接口。可能的取值: 1 — TCP 2 — HTTP os_user (String) — 运行clickhouse-client的操作系统的用户名。 client_hostname (String) — 运行clickhouse-client或另一个TCP客户端的客户端机器的主机名。 client_name (String) — clickhouse-client或另一个TCP客户端名称。 client_revision (UInt32) — clickhouse-client或另一个TCP客户端的修订版。 client_version_major (UInt32) — lickhouse-client或另一个TCP客户端的主要版本。 client_version_minor (UInt32) — lickhouse-client或另一个TCP客户端的小版本。 client_version_patch (UInt32) — clickhouse-client或另一个TCP客户端版本的补丁组件。 http_method (UInt8) — 发起查询的HTTP方法。可能的取值: 0 — 查询是从TCP接口启动的。 1 — 使用GET方法。 2 — 采用POST方法。 http_user_agent (String) —在HTTP请求中传递的UserAgent请求头。 quota_key (String) — 配额设置中指定的配额键。 revision (UInt32) — ClickHouse 修订版。 thread_numbers (Array(UInt32)) — 参与查询执行的线程数。 ProfileEvents.Names (Array(String)) — 测量不同指标的机器数。它们的描述可以在system.events表中找到 ProfileEvents.Values (Array(UInt64)) — 在ProfileEvents.Names 列中列出的指标值。 Settings.Names (Array(String)) — 客户端运行查询时更改的设置的名称。要启用对设置的日志记录,将log_query_settings参数设置为1。 Settings.Values (Array(String)) —Settings.Names列中列出的设置的值。
分类:
clickhouse数据库



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~