

SQL中常见的开窗函数
OVER的定义
OVER用于为行定义一个窗口,它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
OVER的语法
OVER ( [ PARTITION BY column ] [ ORDER BY culumn ] )
PARTITION BY 子句进行分组;
ORDER BY 子句进行排序。
窗口函数OVER()指定一组行,开窗函数计算从窗口函数输出的结果集中各行的值。
开窗函数不需要使用GROUP BY就可以对数据进行分组,还可以同时返回基础行的列和聚合列。
OVER的用法
OVER开窗函数必须与聚合函数或排序函数一起使用,聚合函数一般指SUM(),MAX(),MIN,COUNT(),AVG()等常见函数。排序函数一般指RANK(),ROW_NUMBER(),DENSE_RANK(),NTILE()等。
OVER在聚合函数中使用的示例
我们以SUM和COUNT函数作为示例来给大家演示。

--建立测试表和测试数据 CREATE TABLE Employee ( ID INT PRIMARY KEY, Name VARCHAR(20), GroupName VARCHAR(20), Salary INT ) INSERT INTO Employee VALUES(1,'小明','开发部',8000), (4,'小张','开发部',7600), (5,'小白','开发部',7000), (8,'小王','财务部',5000), (9, null,'财务部',NULL), (15,'小刘','财务部',6000), (16,'小高','行政部',4500), (18,'小王','行政部',4000), (23,'小李','行政部',4500), (29,'小吴','行政部',4700);
SUM后的开窗函数
SELECT *, SUM(Salary) OVER(PARTITION BY Groupname) 每个组的总工资, SUM(Salary) OVER(PARTITION BY groupname ORDER BY ID) 每个组的累计总工资, SUM(Salary) OVER(ORDER BY ID) 累计工资, SUM(Salary) OVER() 总工资 from Employee
(提示:可以左右滑动代码)
结果如下:
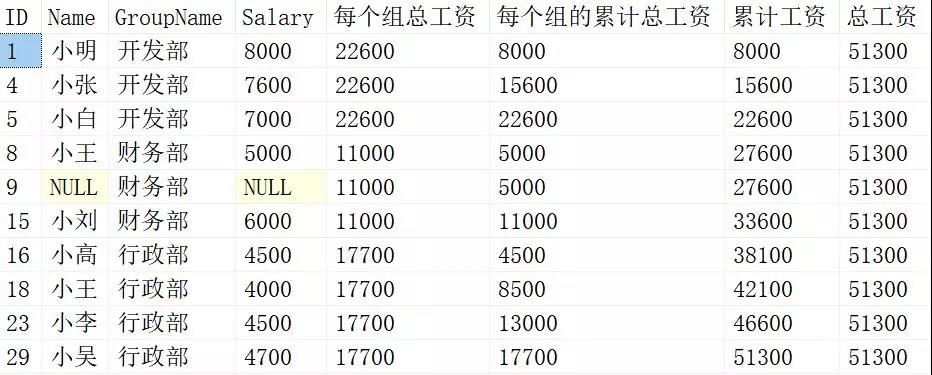
其中开窗函数的每个含义不同,我们来具体解读一下:
SUM(Salary) OVER (PARTITION BY Groupname)
只对PARTITION BY后面的列Groupname进行分组,分组后求解Salary的和。
SUM(Salary) OVER (PARTITION BY Groupname ORDER BY ID)
对PARTITION BY后面的列Groupname进行分组,然后按ORDER BY 后的ID进行排序,然后在组内对Salary进行累加处理。
SUM(Salary) OVER (ORDER BY ID)
只对ORDER BY 后的ID内容进行排序,对排完序后的Salary进行累加处理。
SUM(Salary) OVER ()
对Salary进行汇总处理
COUNT后的开窗函数
SELECT *, COUNT(*) OVER(PARTITION BY Groupname ) 每个组的个数, COUNT(*) OVER(PARTITION BY Groupname ORDER BY ID) 每个组的累积个数, COUNT(*) OVER(ORDER BY ID) 累积个数 , COUNT(*) OVER() 总个数 from Employee
返回的结果如下图:
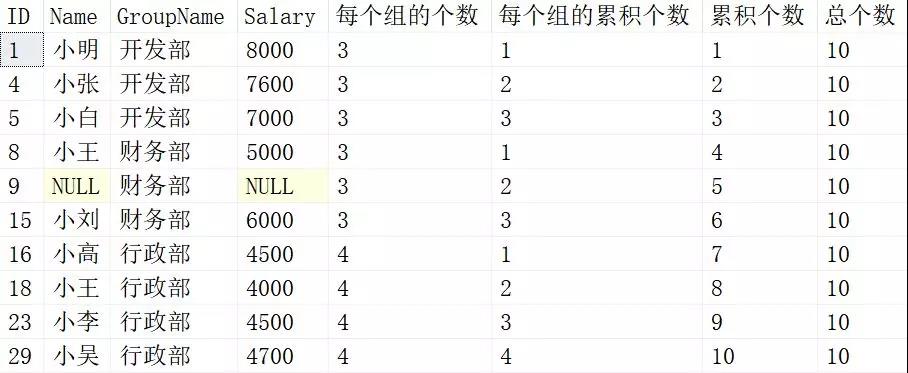
后面的每个开窗函数就不再一一解读了,可以对照上面SUM后的开窗函数进行一一对照。
OVER在排序函数中使用的示例
我们对4个排序函数一一演示
--先建立测试表和测试数据 WITH t AS (SELECT 1 StuID,'一班' ClassName,70 Score UNION ALL SELECT 2,'一班',85 UNION ALL SELECT 3,'一班',85 UNION ALL SELECT 4,'二班',80 UNION ALL SELECT 5,'二班',74 UNION ALL SELECT 6,'二班',80 ) SELECT * INTO Scores FROM t; SELECT * FROM Scores
ROW_NUMBER()
定义:ROW_NUMBER()函数作用就是将SELECT查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询,比如查询前10个 查询10-100个学生。ROW_NUMBER()必须与ORDER BY一起使用,否则会报错。
对学生成绩排序
SELECT *, ROW_NUMBER() OVER (PARTITION BY ClassName ORDER BY SCORE DESC) 班内排序, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores;
结果如下:

这里的PARTITION BY和ORDER BY的作用与我们在上面看到的聚合函数的作用一样,都是用来进行分组和排序使用的。
此外ROW_NUMBER()函数还可以取指定顺序的数据。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores ) t WHERE t.总排序=2;
结果如下:

RANK()
定义:RANK()函数,顾名思义排名函数,可以对某一个字段进行排名,这里和ROW_NUMBER()有什么不一样呢?ROW_NUMBER()是排序,当存在相同成绩的学生时,ROW_NUMBER()会依次进行排序,他们序号不相同,而Rank()则不一样。如果出现相同的,他们的排名是一样的。下面看例子:
示例
SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果:
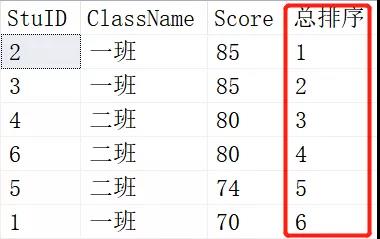

其中上图是ROW_NUMBER()的结果,下图是RANK()的结果。当出现两个学生成绩相同是里面出现变化。RANK()是1-1-3-3-5-6,而ROW_NUMBER()则还是1-2-3-4-5-6,这就是RANK()和ROW_NUMBER()的区别了。
DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?特别是对于有成绩相同的情况,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,一般情况下用的排名函数就是RANK() 我们看例子:
示例
SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT DENSE_RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果如下:
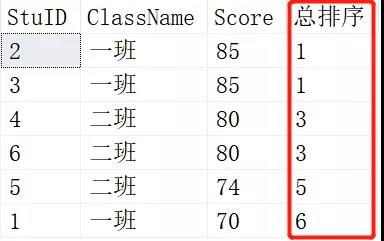

上面是RANK()的结果,下面是DENSE_RANK()的结果
NTILE()
定义:NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的'分区'一样 ,分为几个区,一个区会有多少个。
SELECT *,NTILE(1) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(2) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(3) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores;
结果如下:

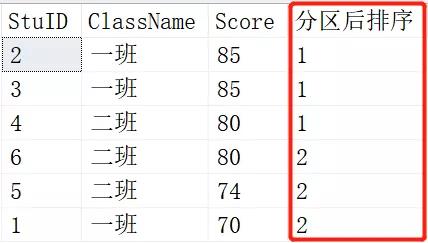
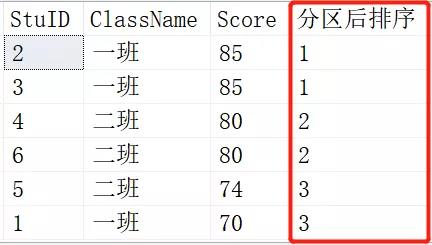
就是将查询出来的记录根据NTILE函数里的参数进行平分分区。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)