Java分布式:分布式锁之Zookeeper
Java分布式:分布式锁之Zookeeper
分布式锁系列教程重点分享锁实现原理
引入ZooKeeper
ZooKeeper是什么呢?
ZooKeeper 是一个开源的分布式协调服务,它可以在分布式系统中共享配置,协调锁资源,提供命名服务等。ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
原语: 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
ZooKeeper的数据模型
ZooKeeper 允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。 名称空间由 ZooKeeper 中的数据寄存器组成 - 称为znode,这些类似于文件和目录。 与为存储设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟。
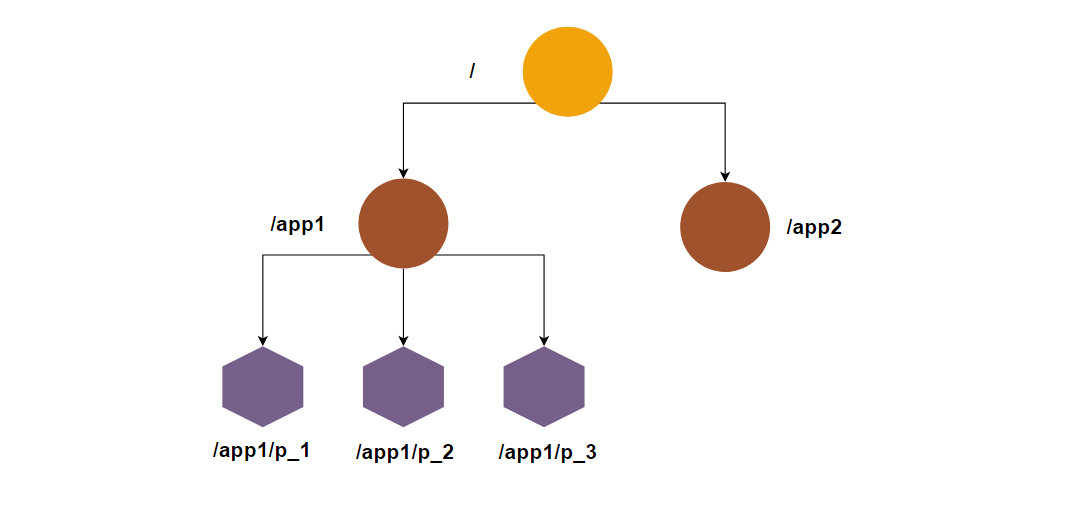
这样的层级结构,让每一个Znode节点拥有唯一的路径,每一个Znode节点主要由四个部分注册:
- data:Znode存储的数据信息。
- ACL:记录Znode的访问权限,即哪些人或哪些IP可以访问本节点。
- stat:包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等等。
- child:当前节点的子节点引用,类似于二叉树的左孩子右孩子。
Znode分为两种类型:
- 短暂/临时(Ephemeral):当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除
- 持久(Persistent):当客户端和服务端断开连接后,所创建的Znode(节点)不会删除
说明:ZooKeeper是为读多写少的场景所设计。Znode并不是用来存储大规模业务数据,而是用于存储少量的状态和配置信息,每个节点的数据最大不能超过1MB。
ZooKeeper分布式锁机制
在描述算法流程之前,先看下zookeeper中几个关于节点的有趣的性质:
-
有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号,也就是说如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
-
临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
-
事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:1)节点创建;2)节点删除;3)节点数据修改;4)子节点变更。
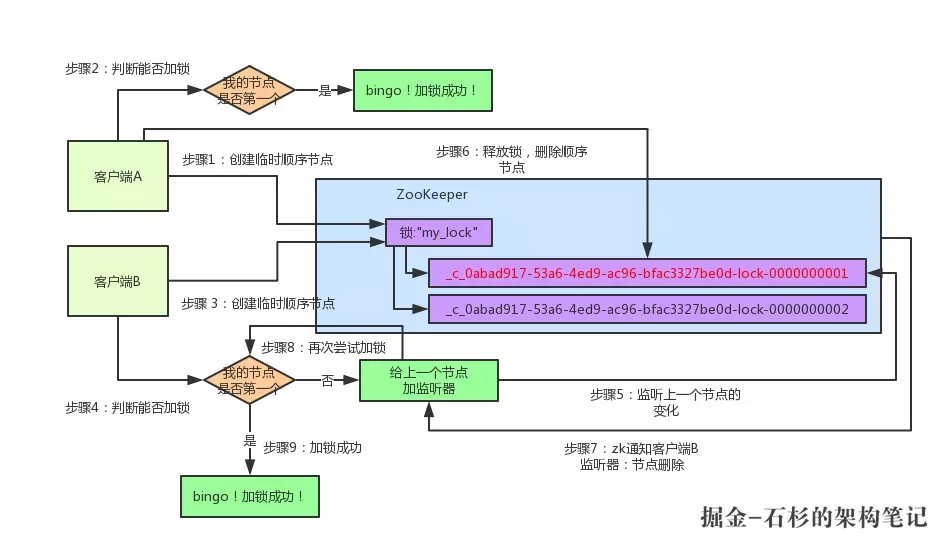
算法描述
-
客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推;
-
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁。
图解
参考资料
- https://segmentfault.com/a/1190000016349824
- https://juejin.im/post/5b037d5c518825426e024473
- https://juejin.im/post/5c01532ef265da61362232ed
- https://blog.csdn.net/qiangcuo6087/article/details/79067136
- https://juejin.im/post/5baf7db75188255c3d11622e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号