Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath
1、快速开始
XPath是一种可以快速在HTML文档中选择并抽取元素、属性和文本的方法。
在Chrome,打开开发者工具,可以使用$x工具函数来使用XPath来选择元素,比如选中所有的超链接。
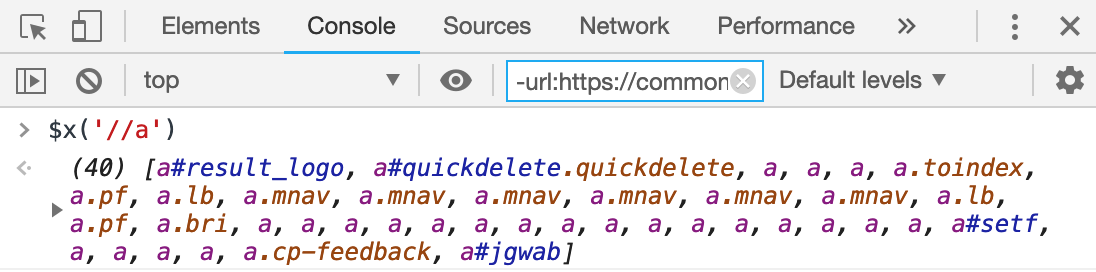
1.1、XPath的基本格式
XPath通过"路径表达式"(Path Expression)来选择节点。
在形式上,"路径表达式"与传统的文件系统非常类似。

比如我们依次获得Html节点(即最根节点)、Html下的Body节点、Html下的Body下的所有Div节点。
单斜杠与双斜杠:
在这里我们使用了单斜杠(/)作为最开始的元素,表示从根节点选取。如果我不想每次都从HTML元素出发,想直接取到Body元素,可以使用双斜杠(//),它表示直接命中待选择元素,而不考虑位置,如//body可以直接取到Body元素。

获取到节点的属性,可以使用@符号
[例1]
//h1/a/@id :获取所有h1元素直接子元素a的id属性。
获取节点的文本,使用text()函数
[例1]
//h1/a/text():获取所有h1元素直接子元素a的文本内容。
1.2、XPath的基本实例
我们以一个简易的类HTML文档,来进行实例分析。
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
[例1]
bookstore :选取 bookstore 元素的所有子节点。
[例2]
/bookstore :选取根节点bookstore,这是绝对路径写法。
[例3]
bookstore/book :选取所有属于 bookstore 的子元素的 book元素,这是相对路径写法。
[例4]
//book :选择所有 book 子元素,而不管它们在文档中的位置。
[例5]
bookstore//book :选择所有属于 bookstore 元素的后代的 book 元素,而不管它们位于 bookstore 之下的什么位置。
[例6]
//@lang :选取所有名为 lang 的属性。
2、XPath的谓语条件
谓语用来在查询的时候设置条件,来达到筛选的效果。
2.1、设置返回的节点数量

2.2、根据节点的属性或属性值来返回节点
[例1]
//div[@class] :选择文档中的所有拥有class属性的div节点。
[例2]
//div[@class='postTitle']:选择文档中的所有拥有class属性且值为postTitle的div节点。
2.3、根据节点是否有特点子元素来返回节点
[例1]
//div[a] :选择文档中的所有拥有a子元素的div节点。
3、XPath的通配符
"*"表示匹配任何元素节点。"@*"表示匹配任何属性值。node()表示匹配任何类型的节点。
[例1]
//* :选择文档中的所有元素节点。
[例2]
/*/* :表示选择所有第二层的元素节点。
[例3]
/HTML/* :表示选择HTML的所有元素子节点。
[例4]
//title[@*] :表示选择所有带有属性的title元素。
[例5]
//book/title | //book/price :表示同时选择book元素的title子元素和price子元素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号