

模型的深度探究
模型的深度探究
从图1-1中我们可以得出,当模型的层数越多,模型对应的错误率就降低。但这就可以得出模型的深度应该越深越好吗?实际上从图1-1上很难得出以上结论,因为当模型越深,模型所具备的参数具越多,就拥有更强的学习能力,错误率也就自然降低。因此,要探究模型深度对模型的影响,应该是在具备相同参数的前提下。

图1-1 模型深度与错误率
浅层模型和深层模型的效果
在对比浅层模型和深层模型时,应该是要使得两个模型的参数数量达到一致。显然,从图1-2中可以得出,当5x2k的模型和1x3772模型的参数几乎快一致时,深层的模型有更好的效果。甚至,增加单层模型的神经元时,模型的效果没并没有提高太多。

图1-2 浅层模型和深层模型
模组化解释
模组化是将深度学习中的每一个神经元当做一个基础分类器。在基础分类的结果上再进行分类。例如,要分辨长短发的男女四中类别,可以将这个分类问题拆分为更小的问题,即男女分类和长短发分类。在两个子分类的结果上,在进行最终问题的分类。
而在图像识别中,第一层神经元是用来分类基本的边、角,第二层神经元是用来分类线条,一次类推。越上层隐藏层就可以根据底层的分类结果,去进行分类更加复杂的对象。
普遍性定理(universality theorem)
Hornik在1989年证明了,只要有足够多的神经元,一层隐藏层的神经网络就可以拟合出任意的连续性函数。在这个理论的基础上,很多人就对深层的模型感到绝望,既然一层就可以解决的模型,又何必搭多层?但是,这个理论没有证明足够多的神经元到底要多少,也许足够多的神经元的数目已经超过能够承受的范围。而实验也证明搭建单层的神经网络往往没有搭建多层的神经网络来得更有效率。
端到端学习(End to End Learning)
有时候我们要解决的问题太过复杂,需要有多个子模型串接在一起来问题来解决(如图1-3所示)。而端到端的学习指的是只给模型输入和输出,让模型自己学习生产线的每个节点需要做什么。
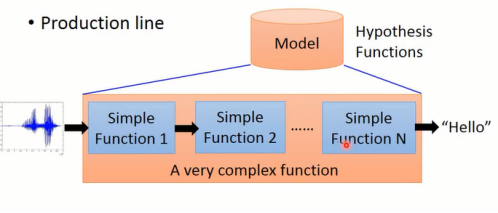
图1-3 语音识别“生产线”
复杂的实际问题
有时候我们面对的问题会比较复杂(如图1-4所示),如给定两个相似的输入数据,输出可能是不同的;也有给定两个不同的输入,输出却要求是相同的。这种情况用一层,可能是很难实现的。

图1-4 复杂的情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号