
2022 PRML Stock Prediction
关于RNN(循环神经网络)(简略了解):
https://zhuanlan.zhihu.com/p/105383343
关于LSTM(长短期记忆网络)以及GRU:
Q1:LSTM如何实现长短期记忆?(《百面深度学习》p54)
一般的RNN(循环神经网络)中,一般是参数共享的【1】,存在对于短期的数据敏感,但是对于长期数据不敏感的问题。LSTM能解决这个问题。首先,它增加了一个cell state单元(就是图里面的c参数,h参数是隐藏状态单元),在不同的时间有可变的权重,解决梯度消失,梯度爆炸的问题。(因为 在(U, W, b)这几个参数不变的情况下,梯度在反向传播过程中,不断连乘,数值不是越来越大就是越来越小)(对有价值的信息进行记忆,放弃冗余记忆,从而减小学习难度。) 它在内部引入了GRU门控单元(输入门,遗忘门,输出门)与内部记忆单元。具体计算见注释【2】。总而言之,LSTM通过门控单元h以及状态单元c的线性自循环,改变以往的信息传播方式,解决了RNN的长期依赖问题(随着输入序列增加,以往的信息无法被学习和利用的问题)
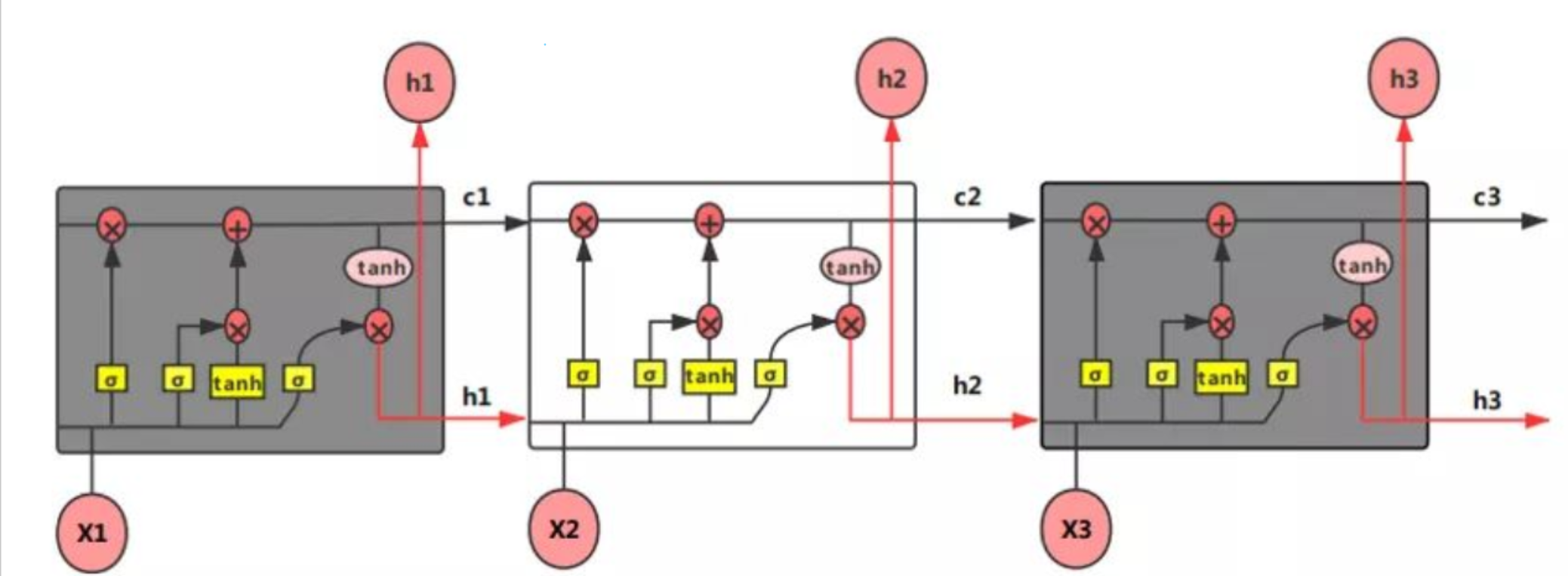
【1】:关于RNN的网络结构与参数共享:https://www.cnblogs.com/wisteria68/p/13488819.html
【2】:关于LSTM:https://zhuanlan.zhihu.com/p/106046810 https://blog.csdn.net/qian99/article/details/88628383
【3】:LSTM实现股票预测:https://zhuanlan.zhihu.com/p/108319473
Q2:GRU(门控循环单元)如何控制时间序列的记忆与遗忘行为?(《百面深度学习》p57)
使用了更新门代替遗忘门和记忆门的功能。遗忘多少就会记忆多少作为弥补。

【1】:关于GRU:https://zhuanlan.zhihu.com/p/106276295
关于AdaGrad优化算法:
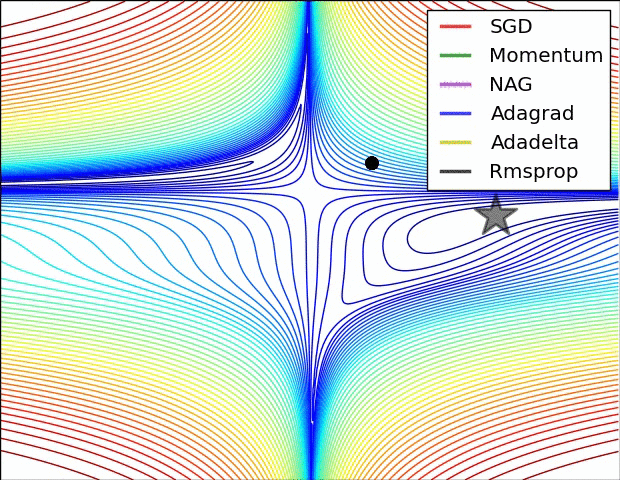
【2】见百面机器学习优化算法一章,需要系统学习。
关于期望方差explained_variance_score:
用于回归模型的准确率。
https://blog.csdn.net/frank_haha/article/details/115707717
(未完待续)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?