

《机器学习的数学》(浅学)
第四章 最优化方法
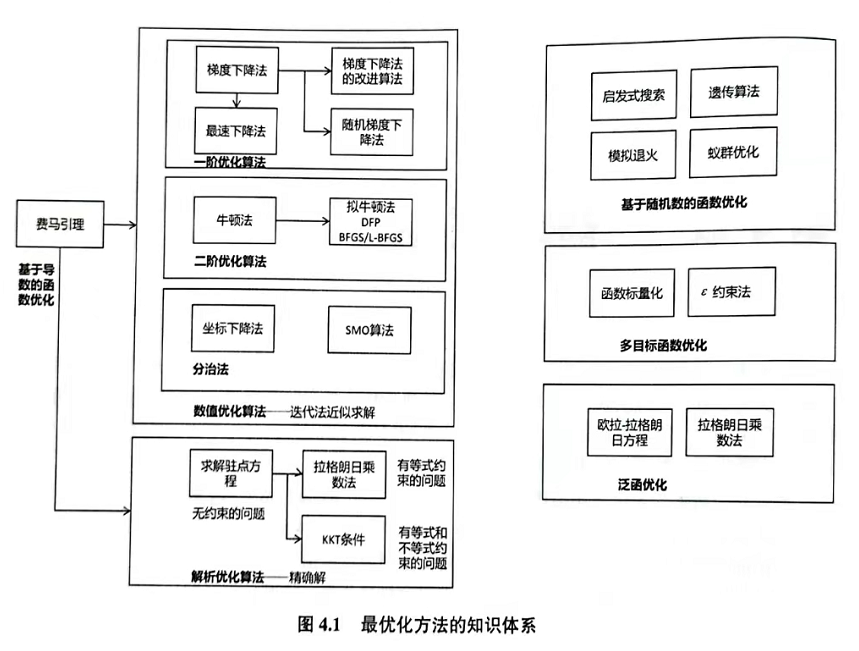
4.1.1 梯度下降法(SGD)
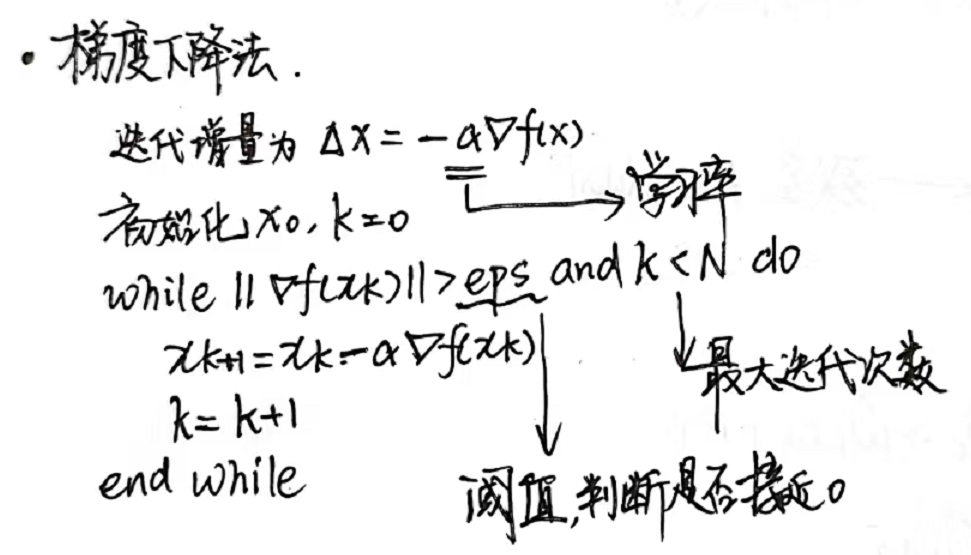

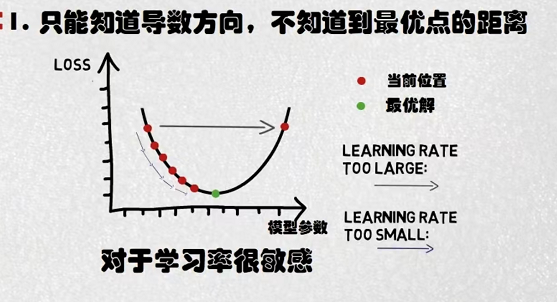
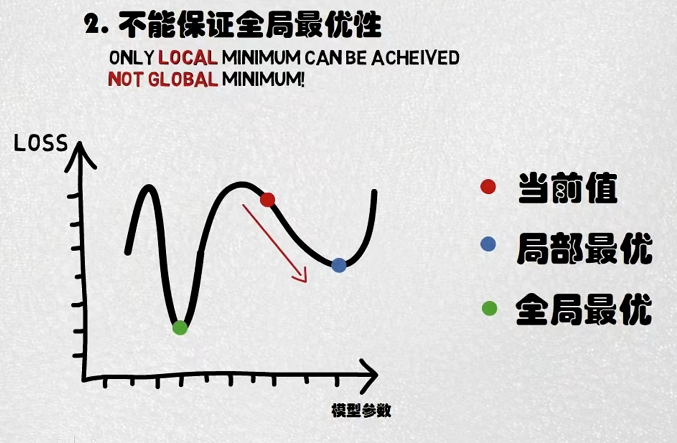
(2022 9 5 复习)补充:
例题有二:
https://blog.csdn.net/lhys666/article/details/120658034(9-6晚上来看)
https://blog.csdn.net/lhys666/article/details/119838278(继续看)
9.6晚上练习了一下梯度下降与随机梯度下降法(SGD与GD):

import torch import matplotlib.pyplot as plt import numpy as np x_data = [5,6,7,8.5,9,10,11.5,12] y_data = [1,2,8,4,5,6.5,7.5,8] w = 1 #初始权重 def forward(x): return x * w #MSE def cost(xs,ys): cost = 0 for x,y in zip(xs,ys): y_pred = forward(x) cost += (y-y_pred)**2 return cost/len(xs) def SGD_loss(xs,ys): y_pred = forward(xs) return (y_pred - ys)**2 def SGD_gradient(xs,ys): return 2*xs*(xs*w-ys) def gradient(xs,ys): grad = 0 for x,y in zip(xs,ys): grad += 2*x*(x*w-y) return grad/len(xs) def draw(x,y): fig = plt.figure(num=1, figsize=(4, 4)) ax = fig.add_subplot(111) ax.plot(x,y) plt.show() # epoch_lis =[] # loss_lis = [] # learning_rate = 0.012 # # for epoch in range(100): # cost_val = cost(x_data,y_data) # grad_val = gradient(x_data,y_data) # w -= learning_rate*grad_val # print("Epoch = {} w = {} loss = {} ".format(epoch,w,cost_val)) # epoch_lis.append(epoch) # loss_lis.append(cost_val) # print(forward(4)) # draw(epoch_lis,loss_lis) # draw(x_data,y_data) l_lis= [] epoch = [] learning_rate = 0.009 #SGD for epoch in range(10): for x,y in zip(x_data,y_data): grad = SGD_gradient(x,y) w -= learning_rate*grad print(" x:{} y:{} grad:{}".format(x,y,grad)) l = SGD_loss(x,y) print("loss: ",l) l_lis.append(l) X = [int(i) for i in range(len(l_lis))] draw(X,l_lis)
随机梯度GD下降用pytorch实现:(实现随机,上一个代码只是对每一个进行处理,而下面这个是随机实现)
import numpy as np import matplotlib.pyplot as plt X = np.arange(0.0, 10.0, 0.1) y = X * 2 w = 0.0 eta = 0.001 # 学习率 result = { 'w': [], 'loss': [] } # 进行预测 def predict(w, x): return w * x # 计算损失 def loss(y, y_pred): return (y_pred - y) ** 2 # 计算梯度 def gradient(x, y, y_pred): return 2 * x * (y_pred - y) for step in range(1, 10001): # 随机一个下标,取对应数据进行训练 index = np.random.randint(0, len(X)) # 预测值 y_pred = predict(w, X[index]) # 损失 Loss = loss(y[index], y_pred) # 梯度 grad = gradient(X[index], y[index], y_pred) # 存取结果 result['w'].append(w) result['loss'].append(Loss) # 输入训练情况 print('\rEpoch: {:>5d}/{} [{}{}] w={:>.4f} loss={:>.4f}'.format( step, 10000, '■' * int(step / 10000 * 50), '□' * (50 - int(step / 10000 * 50)), w, Loss ), end='') w -= eta * grad # 将数据集的顺序打乱 # data_index = list(range(len(X))) # np.random.shuffle(data_index) # X, y = np.array([X[i] for i in data_index]), np.array([y[i] for i in data_index]) # 绘图 plt.plot(result['w'], result['loss'], '-.', label='loss') plt.xlabel('w') plt.ylabel('loss') plt.legend() plt.show()
补充:
https://zhuanlan.zhihu.com/p/355411372
4.1.2 最速下降法
与梯度下降的区别:


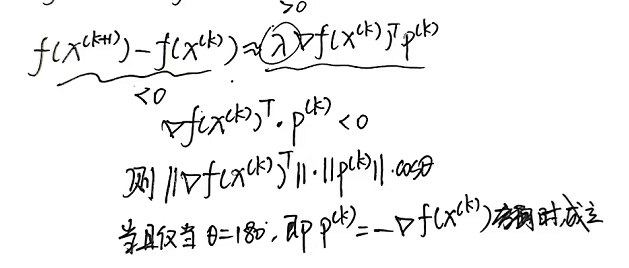







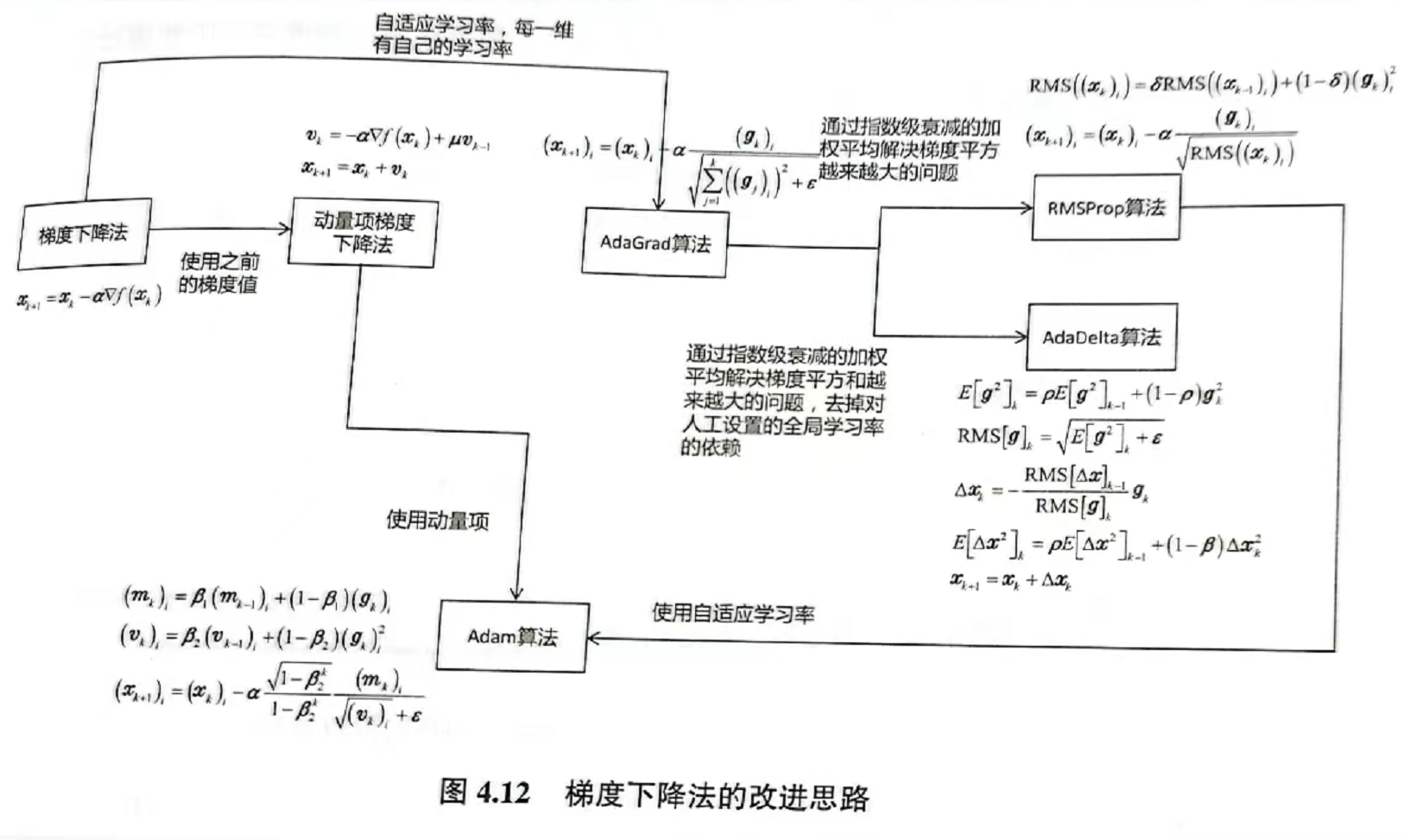
4.1.4梯度下降法的改进(略):
4.1.5 随机梯度下降法(GD)

4.2二阶优化算法
4.2.1牛顿法:


(评:1.正定保证了存在有逆矩阵的要求。2.点式体现出来了搜索方向p(k)(牛顿方向)以及为1的搜索步长)
下面补充对于该函数求梯度的具体解答:

(上文中推导正定矩阵平方仍然为正定矩阵是复习,和本题不相干,因为条件里面已经有矩阵平方正定。)
补充第三章的矩阵和向量求梯度:

-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

(注:剩下的还没有推导)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------



4.2.2拟牛顿法(Quasi-Newton Methods):
(BFGS是拟牛顿法中一种方法)
(DFP也是拟牛顿法中一种方法)
拟牛顿法解决了牛顿法中求hessian矩阵的逆非常困难的问题:用一个矩阵近似替代hessian矩阵的逆。

(1)DFP



于是乎可以按照这个写出Gk+1的迭代公式。
(2)BFGS算法:


(3)Broyden类算法:略

4.3 分治法
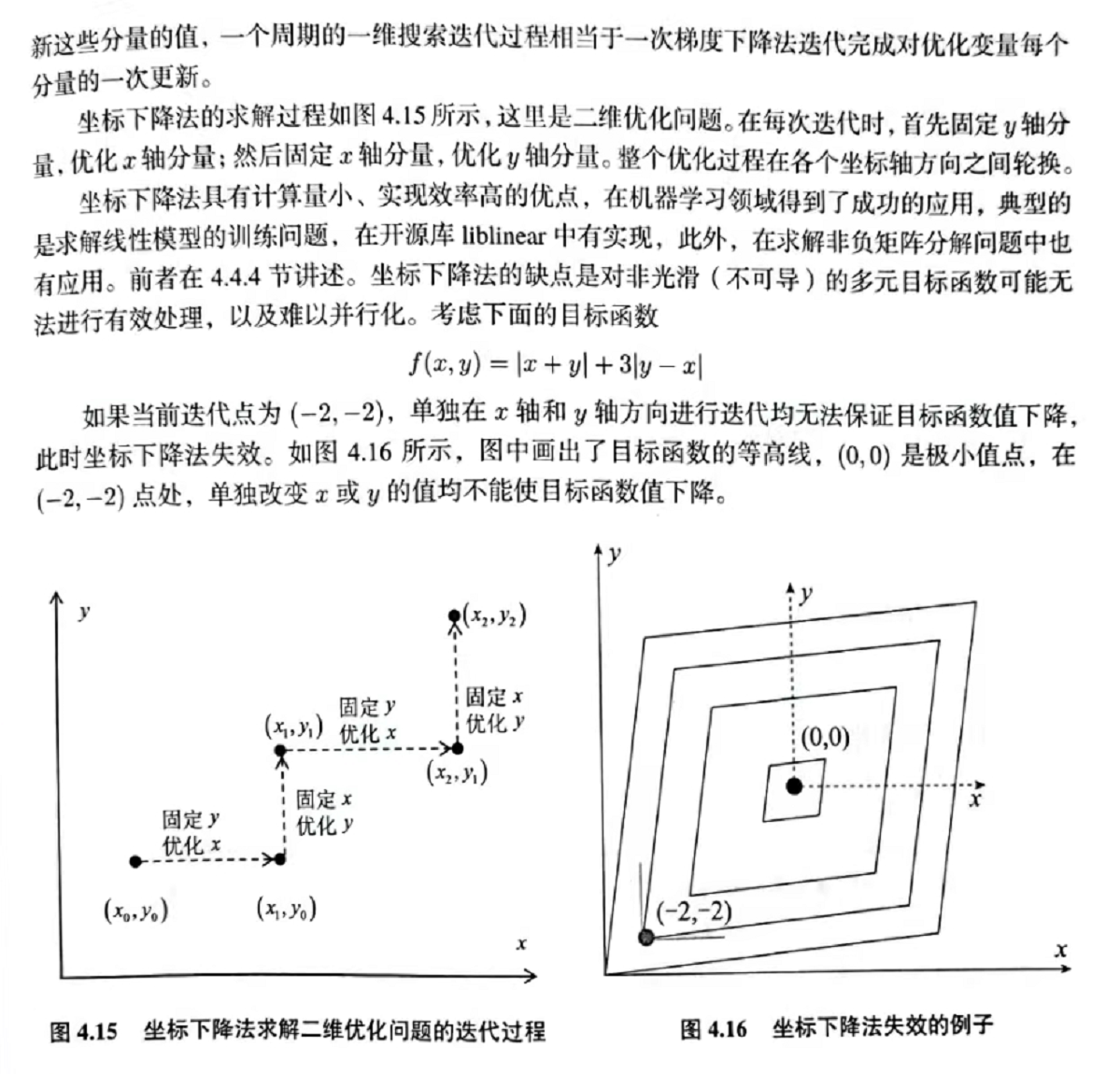
4.3.1坐标下降法


4.3.2 SMO算法


4.3.3分阶段优化
5.1凸优化问题
5.1.1


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本