Linux内存管理之UMA模型和NUMA模型
一、共享存储型多处理机模型
共享存储型多处理机模型有两种:
-
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)模型 (一致存储器访问结构)
- 非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型 (非一致存储器访问结构)
二、UMA模型和NUMA模型
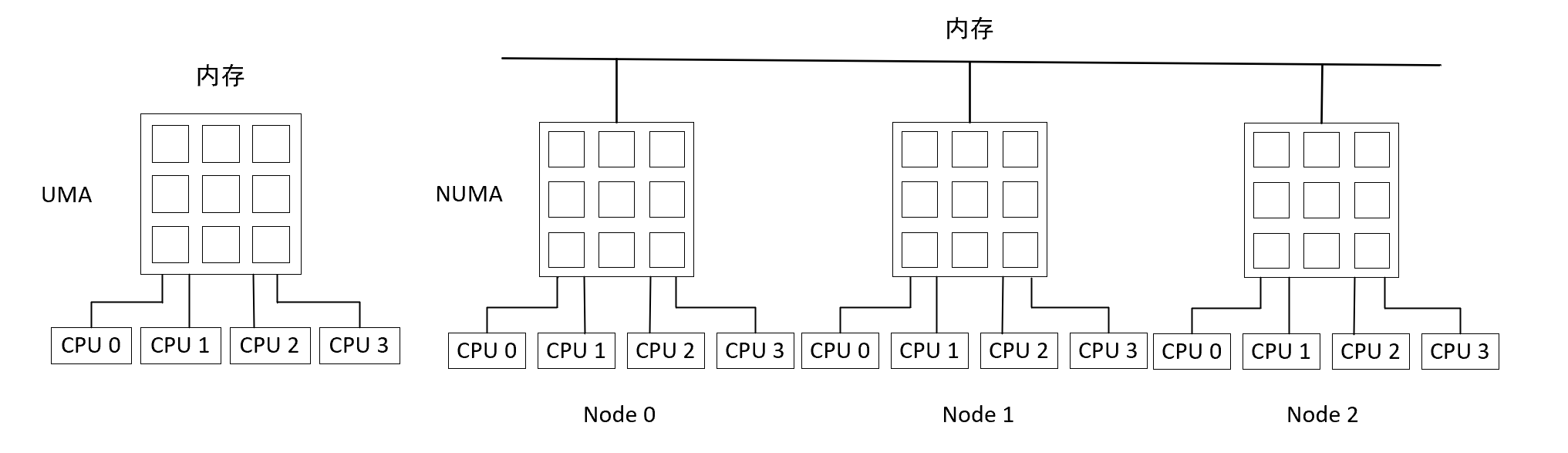
2.1 UMA模型
UMA模型将多个处理机与一个集中的存储器和I/O总线相连,物理存储器被所有处理机均匀共享,所有处理机对所有的存储单元都具有相同的存取时间。SMP(对称型多处理机)系统有时也被称之为一致存储器访问(UMA)结构体系。
UMA模型的最大特点就是共享。在该模型下,所有资源都是共享的,包括CPU、内存、I/O等。也正是由于这种特性,导致了UMA模型可伸缩性非常有限,因为内存是共享的,CPUs都会通过一条内存总线连接到内存上,这时,当多个CPU同时访问同一个内存块时就会产生冲突,因此当存储器和I/O接口达到饱和的时候,增加处理器并不能获得更高的性能。
2.2 NUMA模型
NUMA模型的基本特征是具有多个CPU模块,每个CPU模块又由多个CPU core(如4个)组成,并具有本地内存、I/O接口等,所以可以支持CPU对本地内存的快速访问。这里我们把CPU模块称为节点,每个节点被分配有本地存储器,各个节点之间通过总线连接起来,这样可以支持对其他节点中的本地内存的访问,当然这时访问远的内存就要比访问本地内存慢些。所有节点中的处理器都能够访问全部的物理存储器。
NUMA模型的最大优势是伸缩性。与UMA不同的是,NUMA具有多条内存总线,可以通过限制任何一条内存总线上的CPU数量以及依靠高速互连来连接各个节点,从而缓解UMA的瓶颈。NUMA理论上可以无限扩展的,但由于访问远地内存的延时远远超过访问本地内存,所以当CPU数量增加时,系统性能无法线性增加。
当然,两种模型的混合也是有可能的。
三、(N)UMA模型中的内存组织结构
内核对一致和非一致内存访问系统使用相同的数据结构,因此,对各种不同形式的内存布局,各个内存管理的算法几乎没有什么差别。在UMA系统中,内核只使用一个NUMA节点来管理整个系统内存。而内存管理的其他部分则相信它们是在处理一个伪NUMA系统。由于要引入NUMA,就需要存储管理机制的支持,因此,Linux内存从2.4版本开始就提供了对NUMA的支持(作为一个编译可选项CONFIG_NUMA)。
在NUMA模式下:
-
- 处理器被分割成多个节点,每个节点分配有自己的本地存储器。所有节点中的处理器都能够访问整个物理存储器,但是访问远端存储器的时间要多于访问本地存储器的时间。
- 内存被分割成多个区域称为簇,依据簇与处理器的距离不同,访问不同的簇的代码也不同。
Linux把物理内存划分为三个层次来管理:
-
- 存储节点(Node):是每个CPU对应的一个本地内存,在内核中表示为pg_data_t的实例。因为CPU被划分为多个节点,内存被划分为簇,每个CPU都对应一个本地物理内存,即一个CPU Node对应一个内存簇bank,即每个内存簇被认为是一个存储节点。在UMA结构下,只存在一个存储节点。
- 内存域(Zone):每个物理内存节点Node被划分为多个内存域, 用于表示不同范围的内存,内核可以使用不同的映射方式映射物理内存。
- 页面(Page):各个内存域都关联一个数组,用来组织属于该内存域的物理内存页(页帧)。页面是最基本的页面分配的单位。
具体可参考下图所示。

四、转载于
https://zhuanlan.zhihu.com/p/353918963
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15251906.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号