多个CPU、多核CPU以及超线程(Hyper-Threading)
一、中央处理器
1.1 简介
早期CPU由运算器和控制器组成,称为中央处理机。随着ULSI技术的发展,CPU芯片外部增加了一些逻辑功能部件,CPU越来越复杂,因此CPU基本部分有了运算器、cache、控制器三大部分,称为中央处理器。
1.2 CPU具有的功能
指令控制:由于程序是一个指令序列,这些指令的相互顺序不能任意颠倒,必须严格按程序规定的顺序进行。
操作控制: CPU管理并产生由内存取出的每条指令的操作信号,把各种操作信号送往相应部件,从而控制这些部件按指令的要求进行动作。
时间控制:对各种操作实施时间上的定时。
数据加工:对数据进行算术运算和逻辑运算处理。
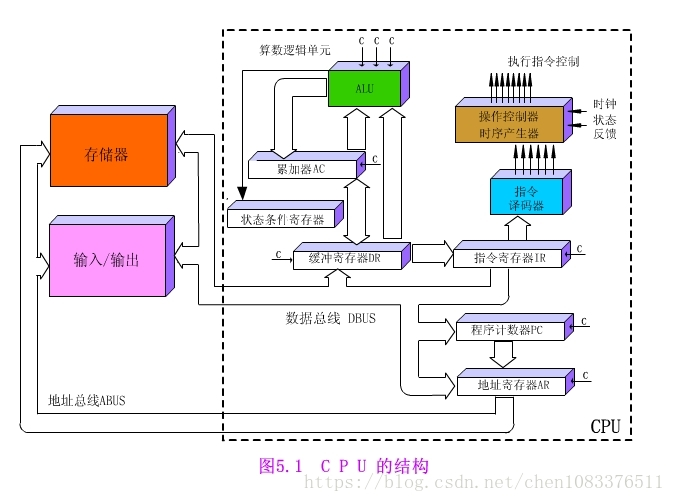
1.3 CPU的基本组成
1.3.1 控制器
1.3.1.1 组成
控制器由程序计数器、指令寄存器、指令译码器、时序产生器和操作控制器组成。
1.3.1.2 功能
控制器的功能:
(1)从指令cache中取出一条指令,并指出下一条指令在指令cache中的位置。
(2)对指令进行译码或测试,并产生相应的操作控制信号,以便启动规定的动作。比如一次数据cache的读/写操作,一个算术逻辑运算操作,或一个输入/输出操作。
(3)指挥并控制CPU、数据cache和输入/输出设备之间数据流动的方向。
1.3.2 运算器
1.3.2.1 组成
运算器由算术逻辑单元(ALU)、通用寄存器、数据缓冲寄存器DR和状态条件寄存器PSW组成。
1.3.2.2 功能
运算器的功能:
(1)执行所有的算术运算。
(2)执行所有的逻辑运算,并进行逻辑测试,如零值测试或两个值的比较。
通常,一个算术操作产生一个运算结果,而一个逻辑操作则产生一个判决。
1.4 CPU的结构图
二、多个CPU
贯穿这个数字计算机的历史,我们一直以来的目标就是想要计算机可以做更多的事情,并且做的更快。因此在hyper-threading 和 multi-core CPUs出现之前,人们想到通过增加CPU的数量来增加计算机的计算机能力和速度,但是这样的方法并没有在个人PC中得到普及,我们只会在一些超级计算机或者一些服务器上会看到这个多个CPU的计算机。因为多个CPU会需要主板有多个CPU socket - 多个CPU被插入到不同的socket中。同时主板也需要额外的硬件去连接这些CPU socket到RAM和一些其它的资源。如果CPU之间需要彼此通信,多个CPU的系统会有很大地开销。
三、Hyper-Threading
3.1 简介
由于多个CPU上面存在的缺点,因此它并没有进入普通大众的电脑中,因此消费者电脑的计算始终没有达到并行的状态,电脑的速度也一直没有加快。直到多核处理器和Hyper-Threading技术的出现,才改变了这一点。Hyper-threading这个概念是Intel提出的,这家伟大的公司想把计算机并行计算的能力带入到个人PC中,它第一次进入大众PC的产品是2002年的Pentium 4 HT,最初的这款处理器仅有单个CPU核心,因此它一次只能做一件事情。但是Hyper-threading技术的出现弥补了这个不足。
Hyper-threading 有时叫做 simultaneous multi-threading,它可以使我们的单核CPU执行多个控制流程。这个技术会涉及到备份一些CPU硬件的一些信息,比如程序计数器和寄存器文件等,而对于比如执行浮点运算的单元它只有一个备份,可以被共享。一个传统的处理器在线程之间切换大约需要20000时钟周期,而一个具有Hyperthreading技术的处理器只需要1个时钟周期,因此这大大减小了线程之间切换的成本。hyperthreading技术的关键点就是:当我们在处理器中执行代码时,很多时候处理器并不会使用到全部的计算能力,部分计算能力会处于空闲状态,而hyperthreading技术会更大程度地“压榨”处理器。举个例子,如果一个线程必须要等到一些数据加载到缓存中以后才能继续执行,此时CPU可以切换到另一个线程去执行,而不用去处于空闲状态,等待当前线程的IO执行完毕。
Hyper-threading 使操作系统认为处理器的核心数是实际核心数的2倍,因此如果有4个核心的处理器,操作系统会认为处理器有8个核心。这项技术通常会对程序有一个性能的提升,通常提升的范围大约在15%-30%之间,对于一些程序来说它的性能甚至会小于20%, 其实性能是否提升这完全取决于具体的程序。比如,这2个逻辑核心都需要用到处理器的同一个组件,那么一个线程必须要等待。因此,Hyper-threading只是一种“欺骗”手段,对于一些程序来说,它可以更有效地利用CPU的计算能力,但是它的性能远没有真正有2个核心的处理器性能好,因此它不能替代真正有2个核心的处理器。但是同样都是2核的处理器,一个有hyper-threading技术而另一个没有,那么有这项技术的处理器在大部分情况下都要比没有的好。
3.2 图说超线程
在操作系统中,有多线程(multi-threading)的概念,这很好理解,因为线程是进程最小的调度单位,一个进程至少包含一个线程。本文将介绍CPU特有的超线程技术。简单来说就是,多线程比较软,超线程比较硬,二者本质上都是虚拟化。
3.2.1 什么是超线程(hyper-threading)
超线程(hyper-threading)其实就是同时多线程(simultaneous multi-theading),是一项允许一个CPU执行多个控制流的技术。它的原理很简单,就是把一颗CPU当成两颗来用,将一颗具有超线程功能的物理CPU变成两颗逻辑CPU,而逻辑CPU对操作系统来说,跟物理CPU并没有什么区别。因此,操作系统会把工作线程分派给这两颗(逻辑)CPU上去执行,让(多个或单个)应用程序的多个线程,能够同时在同一颗CPU上被执行。注意:两颗逻辑CPU共享单颗物理CPU的所有执行资源。因此,我们可以认为,超线程技术就是对CPU的虚拟化。
3.2.2 超线程技术的由来
Hyper-Threading Technology is a form of simultaneous multithreading technology introduced by Intel, while the concept behind the technology has been patented by Sun Microsystems.
超线程技术是同时多线程技术的一种实现形式,由Intel公司提出,而该技术背后的概念则是Sun公司的专利。Sun公司虽然倒下了,但它永远是一个伟大的公司。
纵观计算机的历史,有两个需求是驱动计算机科技进步的持续动力。
-
- 第一,人类想让计算机做得更多;
- 第二,人类想让计算机跑得更快。
从这个意义上讲,那些把工程师当做机器的资本家或资本家豢养的打手在榨取程序员的剩余价值的时候,就是不断地追求上述两个需求。超线程技术的发明,就是基于这样的考虑,不榨干处理器的最后一滴油决不罢休。
3.2.3 单线程v.s.超线程
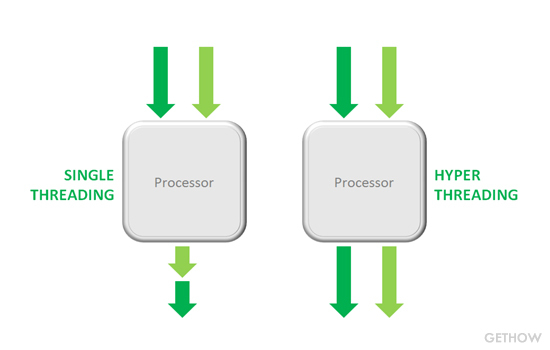
常规的CPU需要大约两万个时钟周期做不同线程间的切换,而超线程的CPU可以在单个时钟周期的基础上决定要执行哪一个线程。这使得CPU能够更好地利用它的处理资源。例如:假设一个线程必须等到某些数据被装入到cache中,那么CPU就可以继续去执行另一个线程。
Intel公司的超线程技术
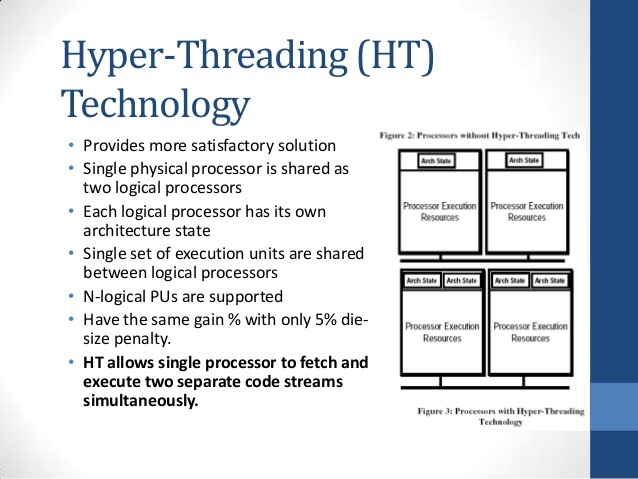
HT allows single processor to fetch and execute two separate code streams simultaneously.
超线程允许单个处理器在同一时刻并行地抓取和执行两个独立的代码流。
3.2.3 超线程是如何工作的

3.2.4 小结
由此可见,超线程技术虽然很酷,但需要方方面面的支持,否则就玩不转。 类似地,如果想最大可能地榨取程序员的剩余价值的话,给程序员提供实现超线程运行的软硬件环境也是必须地,否则一味地让他们拼体力(加班)实在不是个好办法,因为人毕竟不是机器,人只有需要休息好了才可能有创造力,疲惫的人们大多时候是在瞎折腾,往往事倍功半。
超线程(hyper-threading)本质上就是CPU支持的同时多线程(simultaneous multi-threading)技术,简单理解就是对CPU的虚拟化,一颗物理CPU可以被操作系统当做多颗CPU来使用。
四、多核CPU
相比于多个处理器而言,多核处理器把多个CPU(核心)集成到单个集成电路芯片(integrated circuit chip)中,因此主板的单个socket也可以适应这样的CPU,不需要去更更改一些硬件结构。一个双核的CPU有2个中央处理单元,因此不像上面我介绍的hyper-threading技术那样,操作系统看到的只是一种假象,这回操作系统看到的是真正的2个核心,所以2个不同的进程可以分别在不同的核心中同时执行,这大大加快了系统的速度。由于2个核心都在一个芯片上,因此它们之间的通信也要更快,系统也会有更小地延迟。处理器之间通过CPU内部总线进行通讯。而多CPU是指简单的多个CPU工作在同一个系统上,多个CPU之间的通讯是通过主板上的总线进行的。从以上原理可知,N个核的CPU,要比N个CPU在一起的工作效率要高(单核性能一致的情况下)。
下图展示了一个Intel Core i7处理器的一个组织结构,这个微处理器芯片中有4个CPU核,每个核中都有它自己的L1和L2缓存。
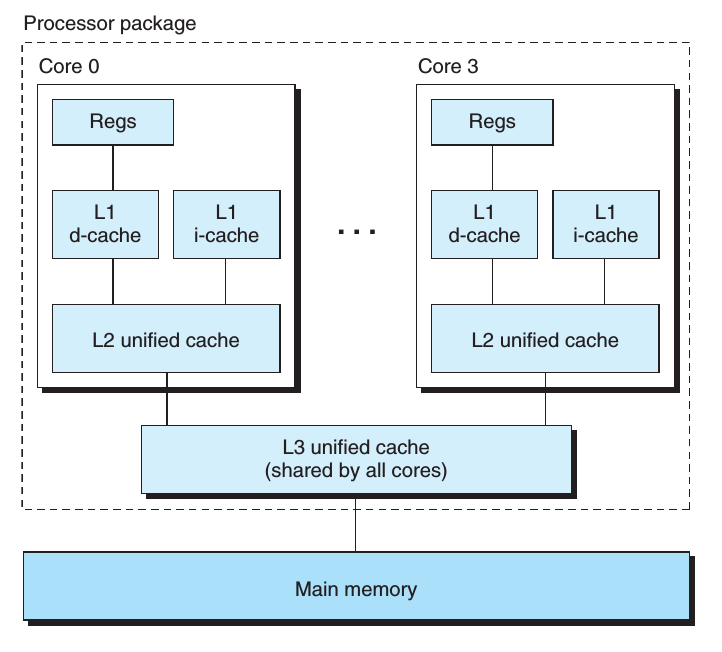
对称多处理器是最主要的多核处理器架构。在这种架构中所有的CPU共享一条系统总线(BUS)来连接主存。而每一个核又有自己的一级缓存,相对于BUS对称分布[2],如下图:

这种架构在并发程序设计中,大致会引来两个问题,一个是内存可见性,一个是Cache一致性流量。内存可见性属于并发安全的问题,Cache一致性流量引起的是性能上的问题。
内存可见性:内存可见性在单处理器或单线程情况下是不会发生的。在一个单线程环境中,一个变量选写入值,然后在没有干涉的情况下读取这个变量,得到的值应该是修改过的值。但是在读和写不在同一个线程中的时候,情况却是不可以预料的。Core1和Core2可能会同时把主存中某个位置的值Load到自己的一级缓存中,而Core1修改了自己一级缓存中的值后,却不更新主存中的值,这样对于Core2来讲,永远看不到Core1对值的修改。为了保证数据的一致性,使用了MISE一致性协议,但是该协议存在一定的问题,比如通知另一个CPU某个值失效,会导致当前CPU处于空闲状态,所以引入了存储缓存,并且姜秀改的操作交给存储缓存来做,完成之后在将其写入缓存当中,同时为存储缓存可以及时的得到另一个CPU的回应,引入了失效队列,将另一个CPU中值的状态的修改推迟执行,但是这样两种方式由引入了可见性问题,同时由于编译具有一定的优化功能,可能导致程序的执行与我们编写程序时期望的有一定的差距,这就是重排序问题;volatile和memory解决软件层面的可见性和重排序问题;内存屏障(读屏障、写屏障、读写屏障)可以硬件层面的可见性和重排序问题。
Cache一致性问题:指的是在SMP结构中,Core1和Core2同时下载了主存中的值到自己的一级缓存中,Core1修改了值后,会通过总线让Core2中的值失效,Core2发现自己存的值失效后,会再通过总线从主存中得到新值。总线的通信能力是固定的,通过总线使各CPU的一级缓存值数据同步的流量过大,那么总线就会成瓶颈。这种影响属于性能上的影响,减小同步竞争就能减少一致性流量。
五、参考文章
https://blog.csdn.net/zolalad/article/details/28393209?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
https://blog.csdn.net/stpeace/article/details/81608524?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1.control&spm=1001.2101.3001.4242
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15201044.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号