TCP 协议如何解决粘包、半包问题
一、TCP 协议是流式协议
很多读者从接触网络知识以来,应该听说过这句话:TCP 协议是流式协议。那么这句话到底是什么意思呢?所谓流式协议,即协议的内容是像流水一样的字节流,内容与内容之间没有明确的分界标志,需要我们人为地去给这些协议划分边界。
举个例子,A 与 B 进行 TCP 通信,A 先后给 B 发送了一个 100 字节和 200 字节的数据包,那么 B 是如何收到呢?B 可能先收到 100 字节,再收到 200 字节;也可能先收到 50 字节,再收到 250 字节;或者先收到 100 字节,再收到 100 字节,再收到 200 字节;或者先收到 20 字节,再收到 20 字节,再收到 60 字节,再收到 100 字节,再收到 50 字节,再收到 50 字节……
不知道读者看出规律没有?规律就是 A 一共给 B 发送了 300 字节,B 可能以一次或者多次任意形式的总数为 300 字节收到。假设 A 给 B 发送的 100 字节和 200 字节分别都是一个数据包,对于发送端 A 来说,这个是可以区分的,但是对于 B 来说,如果不人为规定多长为一个数据包,B 每次是不知道应该把收到的数据中多少字节作为一个有效的数据包的。而规定每次把多少数据当成一个包就是协议格式规范的内容之一。
经常会有新手写出类似下面这样的代码:
发送端:

接收端:

为了专注问题本身的讨论,我这里省略掉了建立连接和部分错误处理的逻辑。上述代码中发送端给接收端发送了一串字符”the quick brown fox jumps over a lazy dog.“,接收端收到后将其打印出来。
类似这样的代码在本机一般会工作的很好,接收端也如期打印出来预料的字符串,但是一放到局域网或者公网环境就出问题了,即接收端可能打印出来字符串并不完整;如果发送端连续多次发送字符串,接收端会打印出来的字符串不完整或出现乱码。不完整的原因很好理解,即对端某次收到的数据小于完整字符串的长度,recvBuf 数组开始被清空成 0,收到部分字符串后,该字符串的末尾仍然是 0,printf 函数寻找以 0 为结束标志的字符结束输出;乱码的原因是如果某次收入的数据不仅包含一个完整的字符串,还包含下一个字符串部分内容,那么 recvBuf 数组将会被填满,printf 函数输出时仍然会寻找以 0 为结束标志的字符结束输出,这样读取的内存就越界了,一直找到为止,而越界后的内存可能是一些不可读字符,显示出来后就乱码了。
我举这个例子希望你明白 能对TCP 协议是流式协议有一个直观的认识。正因为如此,所以我们需要人为地在发送端和接收端规定每一次的字节流边界,以便接收端知道从什么位置取出多少字节来当成一个数据包去解析,这就是我们设计网络通信协议格式的要做的工作之一。
二、如何解决粘包问题
2.1 简介
网络通信程序实际开发中,或者技术面试时,面试官通常会问的比较多的一个问题是:网络通信时,如何解决粘包?
有的面试官可能会这么问:网络通信时,如何解决粘包、丢包或者包乱序问题?这个问题其实是面试官在考察面试者的网络基础知识,如果是 TCP 协议,在大多数场景下,是不存在丢包和包乱序问题的,TCP 通信是可靠通信方式,TCP 协议栈通过序列号和包重传确认机制保证数据包的有序和一定被正确发到目的地;如果是 UDP 协议,如果不能接受少量丢包,那就要自己在 UDP 的基础上实现类似 TCP 这种有序和可靠传输机制了(例如 RTP协议、RUDP 协议)。所以,问题拆解后,只剩下如何解决粘包的问题。
2.2 什么是TCP粘包问题
TCP粘包就是指发送方发送的若干包数据到达接收方时粘成了一包,从接收缓冲区来看,后一包数据的头紧接着前一包数据的尾,出现粘包的原因是多方面的,可能是来自发送方,也可能是来自接收方。
2.3 造成TCP粘包的原因
2.3.1 发送方原因
TCP默认使用Nagle算法(主要作用:减少网络中报文段的数量),而Nagle算法主要做两件事:
-
- 1、只有上一个分组得到确认,才会发送下一个分组
- 2、收集多个小分组,在一个确认到来时一起发送
Nagle算法造成了发送方可能会出现粘包问题.
2.3.2 接收方原因
TCP接收到数据包时,并不会马上交到应用层进行处理,或者说应用层并不会立即处理。实际上,TCP将接收到的数据包保存在接收缓存里,然后应用程序主动从缓存读取收到的分组。这样一来,如果TCP接收数据包到缓存的速度大于应用程序从缓存中读取数据包的速度,多个包就会被缓存,应用程序就有可能读取到多个首尾相接粘到一起的包。
2.4 什么是TCP半包
接收端收到的数据只是一个包的部分,这种情况一般也叫半包。
2.5 如何解决粘包和半包
无论是半包还是粘包问题,其根源是上文介绍中 TCP 协议是流式数据格式。解决问题的思路还是想办法从收到的数据中把包与包的边界给区分出来。那么如何区分呢?目前主要有三种方法:
2.5.1 固定包长的数据包
顾名思义,即每个协议包的长度都是固定的。举个例子,例如我们可以规定每个协议包的大小是 64 个字节,每次收满 64 个字节,就取出来解析(如果不够,就先存起来)。
这种通信协议的格式简单但灵活性差。如果包内容不足指定的字节数,剩余的空间需要填充特殊的信息,如 \0(如果不填充特殊内容,如何区分包里面的正常内容与填充信息呢?);如果包内容超过指定字节数,又得分包分片,需要增加额外处理逻辑——在发送端进行分包分片,在接收端重新组装包片(分包和分片内容在接下来会详细介绍)。
2.5.2 以指定字符(串)为包的结束标志
这种协议包比较常见,即字节流中遇到特殊的符号值时就认为到一个包的末尾了。例如,我们熟悉的 FTP协议,发邮件的 SMTP 协议,一个命令或者一段数据后面加上"\r\n"(即所谓的 CRLF)表示一个包的结束。对端收到后,每遇到一个”\r\n“就把之前的数据当做一个数据包。
这种协议一般用于一些包含各种命令控制的应用中,其不足之处就是如果协议数据包内容部分需要使用包结束标志字符,就需要对这些字符做转码或者转义操作,以免被接收方错误地当成包结束标志而误解析。
2.5.3 包头 + 包体格式
这种格式的包一般分为两部分,即包头和包体,包头是固定大小的,且包头中必须含有一个字段来说明接下来的包体有多大。
1 struct msg_header
2 {
3 int32_t bodySize;
4 int32_t cmd;
5 };
这就是一个典型的包头格式,bodySize 指定了这个包的包体是多大。由于包头大小是固定的(这里是 size(int32_t) + sizeof(int32_t) = 8 字节),对端先收取包头大小字节数目(当然,如果不够还是先缓存起来,直到收够为止),然后解析包头,根据包头中指定的包体大小来收取包体,等包体收够了,就组装成一个完整的包来处理。在有些实现中,包头中的 bodySize可能被另外一个叫 packageSize 的字段代替,这个字段的含义是整个包的大小,这个时候,我们只要用 packageSize 减去包头大小(这里是 sizeof(msg_header))就能算出包体的大小,原理同上。
在使用大多数网络库时,通常你需要根据协议格式自己给数据包分界和解析,一般的网络库不提供这种功能是出于需要支持不同的协议,由于协议的不确定性,因此没法预先提供具体解包代码。当然,这不是绝对的,也有一些网络库提供了这种功能。在 Java Netty 网络框架中,提供了FixedLengthFrameDecoder 类去处理长度是定长的协议包,提供了 DelimiterBasedFrameDecoder 类去处理按特殊字符作为结束符的协议包,提供 ByteToMessageDecoder 去处理自定义格式的协议包(可用来处理包头 + 包体 这种格式的数据包),然而在继承 ByteToMessageDecoder 子类中你需要根据你的协议具体格式重写 decode() 方法来对数据包解包。
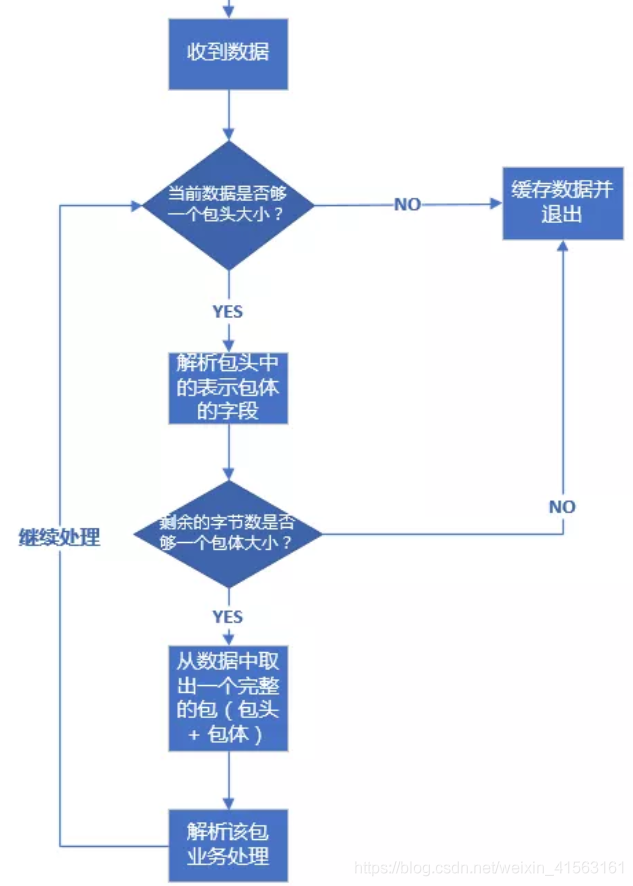
2.5.4 包头 + 包体格式方案解包处理流程
在理解了前面介绍的数据包的三种格式后,我们来介绍一下针对上述三种格式的数据包技术上应该如何处理。其处理流程都是一样的,这里我们以包头 + 包体 这种格式的数据包来说明。处理流程如下:
三、UDP会不会产生粘包问题
TCP为了保证可靠传输并减少额外的开销(每次发包都要验证),采用了基于流的传输,基于字节流的传输不认为消息是一条一条的,是无保护消息边界的(保护消息边界:指传输协议把数据当做一条独立的消息在网上传输,接收端一次只能接受一条独立的消息)。
UDP则是面向消息传输的,是有保护消息边界的,接收方一次只接受一条独立的信息,而且UDP发送方不会使用块的合并优化算法,这样,实际上目前认为,是由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。所以UDP不会出现粘包问题,所以不存在粘包问题。
举个例子:有三个数据包,大小分别为2k、4k、6k,如果采用UDP发送的话,不管接受方的接收缓存有多大,我们必须要进行至少三次以上的发送才能把数据包发送完,但是使用TCP协议发送的话,我们只需要接受方的接收缓存有12k的大小,就可以一次把这3个数据包全部发送完毕。
四、转载于
https://blog.csdn.net/weixin_41563161/article/details/105164346
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15154433.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号