Proactor模式&Reactor模式详解
一、简介
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种:
(1)同步阻塞IO(BlockingIO):即传统的IO模型。
(2)同步非阻塞IO(Non-blockingIO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。注意这里所说的NIO并非Java的NIO(NewIO)库。
(3)IO多路复用(IOMultiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
(4)异步IO(AsynchronousIO):即经典的Proactor设计模式,也称为异步非阻塞IO。
同步和异步的概念描述的是用户线程与内核的交互方式:同步是指用户线程发起IO请求后需要等待或者轮询内核IO操作完成后才能继续执行;而异步是指用户线程发起IO请求后仍继续执行,当内核IO操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞和非阻塞的概念描述的是用户线程调用内核IO操作的方式:阻塞是指IO操作需要彻底完成后才返回到用户空间;而非阻塞是指IO操作被调用后立即返回给用户一个状态值,无需等到IO操作彻底完成。
另外,RichardStevens在《Unix网络编程》卷1中提到的基于信号驱动的IO(SignalDrivenIO)模型,由于该模型并不常用,本文不作涉及。接下来,我们详细分析四种常见的IO模型的实现原理。为了方便描述,我们统一使用IO的读操作作为示例。
二、同步阻塞IO
同步阻塞IO模型是最简单的IO模型,用户线程在内核进行IO操作时被阻塞。

如图1所示,用户线程通过系统调用read发起IO读操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接收的数据拷贝到用户空间,完成read操作。
用户线程使用同步阻塞IO模型的伪代码描述为:
1 {
2 read(socket, buffer);
3 process(buffer);
4 }
即用户需要等待read将socket中的数据读取到buffer后,才继续处理接收的数据。整个IO请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
三、同步非阻塞IO
同步非阻塞IO是在同步阻塞IO的基础上,将socket设置为NONBLOCK。这样做用户线程可以在发起IO请求后可以立即返回。
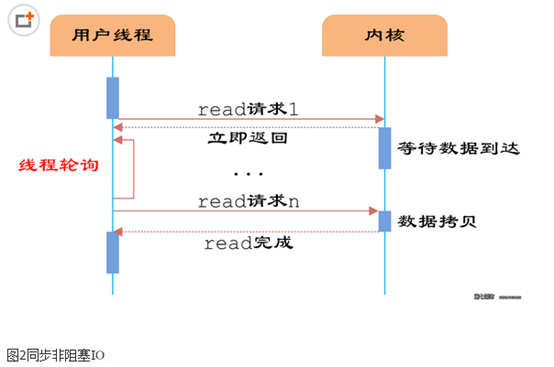
如图2所示,由于socket是非阻塞的方式,因此用户线程发起IO请求时立即返回。但并未读取到任何数据,用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
用户线程使用同步非阻塞IO模型的伪代码描述为:
1 {
2 while(read(socket, buffer) != SUCCESS);
3 process(buffer);
4 }
即用户需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
四、IO多路复用
IO多路复用模型是建立在内核提供的多路分离函数select、poll以及epoll基础之上的,使用这些函数可以避免同步非阻塞IO模型中轮询等待的问题,因为用户线程将这个轮询的过程将给内核来执行,而自己则表现为阻塞态。
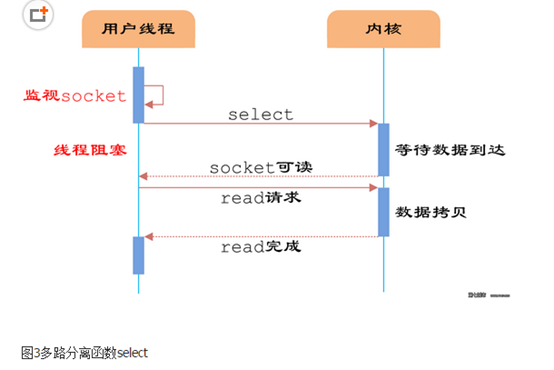
如图3所示,用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
用户线程使用select函数的伪代码描述为:
1 {
2 select(socket);
3 while(1)
4 {
5 sockets = select();
6 for(socket in sockets) {
7 if(can_read(socket)) {
8 read(socket, buffer);
9 process(buffer);
10 }
11 }
12 }
13 }
其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦socket可读,便调用read函数将socket中的数据读取出来。
然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
IO多路复用模型使用了Reactor设计模式实现了这一机制。
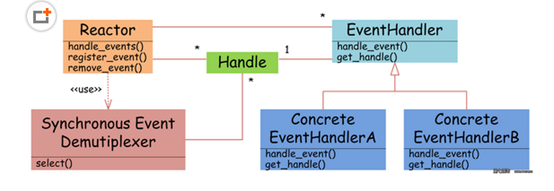
图4Reactor设计模式
如图4所示,EventHandler抽象类表示IO事件处理器,它拥有IO文件句柄Handle(通过get_handle获取),以及对Handle的操作handle_event(读/写等)。继承于EventHandler的子类可以对事件处理器的行为进行定制。Reactor类用于管理EventHandler(注册、删除等),并使用handle_events实现事件循环,不断调用同步事件多路分离器(一般是内核)的多路分离函数select,只要某个文件句柄被激活(可读/写等),select就返回(阻塞),handle_events就会调用与文件句柄关联的事件处理器的handle_event进行相关操作。
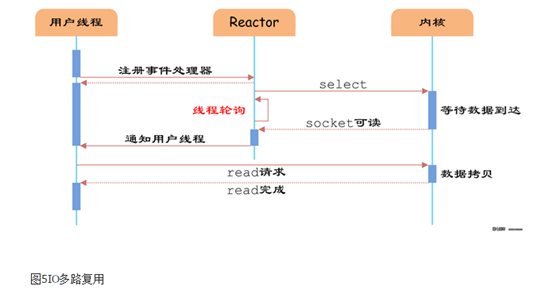
如图5所示,通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程(相当于工作线程)一定不会被阻塞。
用户线程使用IO多路复用模型的伪代码描述为:
1 voidUserEventHandler::handle_event(){
2 if(can_read(socket)){
3 read(socket,buffer);
4 process(buffer);
5 }
6 }
7 {
8 Reactor.register(newUserEventHandler(socket));
9 }
用户需要重写EventHandler的handle_event函数进行读取数据、处理数据的工作,用户线程只需要将自己的EventHandler注册到Reactor即可。Reactor中handle_events事件循环的伪代码大致如下。
1 Reactor::handle_events(){
2 while(1){
3 sockets=select();
4 for(socketinsockets){
5 get_event_handler(socket).handle_event();
6 }
7 }
8 }
事件循环不断地调用select获取被激活的socket,然后根据获取socket对应的EventHandler,执行器handle_event函数即可。IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因为它使用了会阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO,而非真正的异步IO。
五、异步IO
“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。
异步IO模型使用了Proactor设计模式实现了这一机制。
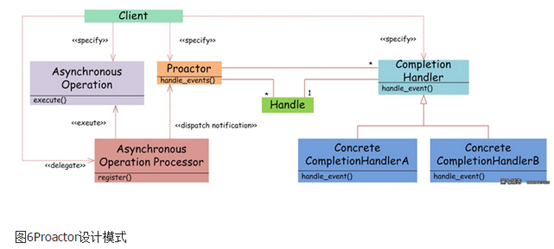
如图6,Proactor模式和Reactor模式在结构上比较相似,不过在用户(Client)使用方式上差别较大。Reactor模式中,用户线程通过向Reactor对象注册感兴趣的事件监听,然后事件触发时调用事件处理函数。而Proactor模式中,用户线程将AsynchronousOperation(读/写等)、Proactor以及操作完成时的CompletionHandler注册到AsynchronousOperationProcessor。AsynchronousOperationProcessor使用Facade模式提供了一组异步操作API(读/写等)供用户使用,当用户线程调用异步API后,便继续执行自己的任务。AsynchronousOperationProcessor会开启独立的内核线程执行异步操作,实现真正的异步。当异步IO操作完成时,AsynchronousOperationProcessor将用户线程与AsynchronousOperation一起注册的Proactor和CompletionHandler取出,然后将CompletionHandler与IO操作的结果数据一起转发给Proactor,Proactor负责回调每一个异步操作的事件完成处理函数handle_event。虽然Proactor模式中每个异步操作都可以绑定一个Proactor对象,但是一般在操作系统中,Proactor被实现为Singleton模式,以便于集中化分发操作完成事件。
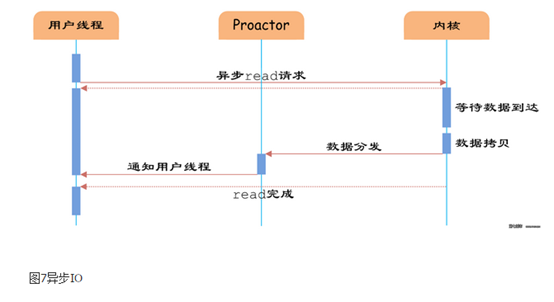
如图7所示,异步IO模型中,用户线程直接使用内核提供的异步IOAPI发起read请求,且发起后立即返回,继续执行用户线程代码。不过此时用户线程已经将调用的AsynchronousOperation和CompletionHandler注册到内核,然后操作系统开启独立的内核线程去处理IO操作。当read请求的数据到达时,由内核负责读取socket中的数据,并写入用户指定的缓冲区中。最后内核将read的数据和用户线程注册的CompletionHandler分发给内部Proactor,Proactor将IO完成的信息通知给用户线程(一般通过调用用户线程注册的完成事件处理函数),完成异步IO。
用户线程使用异步IO模型的伪代码描述为:
1 voidUserCompletionHandler::handle_event(buffer){
2 process(buffer);
3 }
4 {
5 aio_read(socket,newUserCompletionHandler);
6 }
用户需要重写CompletionHandler的handle_event函数进行处理数据的工作,参数buffer表示Proactor已经准备好的数据,用户线程直接调用内核提供的异步IOAPI,并将重写的CompletionHandler注册即可。
相比于IO多路复用模型,异步IO并不十分常用,不少高性能并发服务程序使用IO多路复用模型+多线程任务处理的架构基本可以满足需求。况且目前操作系统对异步IO的支持并非特别完善,更多的是采用IO多路复用模型模拟异步IO的方式(IO事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区中)。Java7之后已经支持了异步IO,感兴趣的读者可以尝试使用。
六、reactor总结
6.1 背景
如果要让服务器服务多个客户端,那么最直接的方式就是为每一条连接创建线程。
其实创建进程也是可以的,原理是一样的,进程和线程的区别在于线程比较轻量级些,线程的创建和线程间切换的成本要小些,为了描述简述,后面都以线程为例。
处理完业务逻辑后,随着连接关闭后线程也同样要销毁了,但是这样不停地创建和销毁线程,不仅会带来性能开销,也会造成浪费资源,而且如果要连接几万条连接,创建几万个线程去应对也是不现实的。
要这么解决这个问题呢?我们可以使用「资源复用」的方式。
也就是不用再为每个连接创建线程,而是创建一个「线程池」,将连接分配给线程,然后一个线程可以处理多个连接的业务。
不过,这样又引来一个新的问题,线程怎样才能高效地处理多个连接的业务?
当一个连接对应一个线程时,线程一般采用「read -> 业务处理 -> send」的处理流程,如果当前连接没有数据可读,那么线程会阻塞在 read 操作上( socket 默认情况是阻塞 I/O),不过这种阻塞方式并不影响其他线程。
但是引入了线程池,那么一个线程要处理多个连接的业务,线程在处理某个连接的 read 操作时,如果遇到没有数据可读,就会发生阻塞,那么线程就没办法继续处理其他连接的业务。
要解决这一个问题,最简单的方式就是将 socket 改成非阻塞,然后线程不断地轮询调用 read 操作来判断是否有数据,这种方式虽然该能够解决阻塞的问题,但是解决的方式比较粗暴,因为轮询是要消耗 CPU 的,而且随着一个线程处理的连接越多,轮询的效率就会越低。
上面的问题在于,线程并不知道当前连接是否有数据可读,从而需要每次通过 read 去试探。
那有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用。
6.2 IO多路复用

我们熟悉的 select/poll/epoll 就是内核提供给用户态的多路复用系统调用,线程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?
在获取事件时,先把我们要关心的连接传给内核,再由内核检测:
-
-
如果没有事件发生,线程只需阻塞在这个系统调用,而无需像前面的线程池方案那样轮训调用 read 操作来判断是否有数据。
-
如果有事件发生,内核会返回产生了事件的连接,线程就会从阻塞状态返回,然后在用户态中再处理这些连接对应的业务即可。
-
当下开源软件能做到网络高性能的原因就是 I/O 多路复用吗?
是的,基本是基于 I/O 多路复用,用过 I/O 多路复用接口写网络程序的同学,肯定知道是面向过程的方式写代码的,这样的开发的效率不高。
于是,大佬们基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。大佬们还为这种模式取了个让人第一时间难以理解的名字:Reactor 模式。
6.3 简介
Reactor 翻译过来的意思是「反应堆」,可能大家会联想到物理学里的核反应堆,实际上并不是的这个意思。
这里的反应指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。
事实上,Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
-
Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
-
处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor 模式是灵活多变的,可以应对不同的业务场景,灵活在于:
-
Reactor 的数量可以只有一个,也可以有多个;
-
处理资源池可以是单个进程 / 线程,也可以是多个进程 /线程;
将上面的两个因素排列组设一下,理论上就可以有 4 种方案选择:
-
单 Reactor 单进程 / 线程;
-
单 Reactor 多进程 / 线程;
-
多 Reactor 单进程 / 线程;
-
多 Reactor 多进程 / 线程;
其中,「多 Reactor 单进程 / 线程」实现方案相比「单 Reactor 单进程 / 线程」方案,不仅复杂而且也没有性能优势,因此实际中并没有应用。
方案具体使用进程还是线程,要看使用的编程语言以及平台有关:
-
Java 语言一般使用线程,比如 Netty;
-
C 语言使用进程和线程都可以,例如 Nginx 使用的是进程,Memcache 使用的是线程。
接下来,分别介绍这三个经典的 Reactor 方案。
6.4 单 Reactor 单进程 / 线程
6.4.1 流程图
一般来说,C 语言实现的是「单 Reactor 单进程」的方案,因为 C 语编写完的程序,运行后就是一个独立的进程,不需要在进程中再创建线程。
而 Java 语言实现的是「单 Reactor 单线程」的方案,因为 Java 程序是跑在 Java 虚拟机这个进程上面的,虚拟机中有很多线程,我们写的 Java 程序只是其中的一个线程而已。
我们来看看「单 Reactor 单进程」的方案示意图:
6.4.2 流程图分析
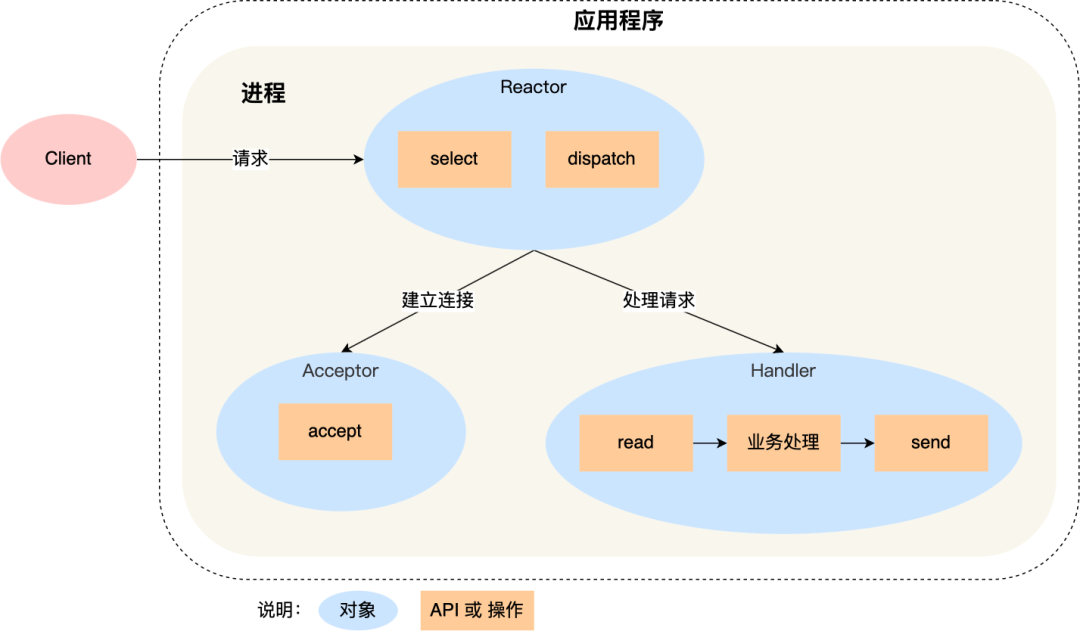
可以看到进程里有 Reactor、Acceptor、Handler 这三个对象:
-
Reactor 对象的作用是监听和分发事件;
-
Acceptor 对象的作用是获取连接;
-
Handler 对象的作用是处理业务;
对象里的 select、accept、read、send 是系统调用函数,dispatch 和 「业务处理」是需要完成的操作,其中 dispatch 是分发事件操作。
接下来,介绍下「单 Reactor 单进程」这个方案:
-
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
-
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
-
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
-
Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
单 Reactor 单进程的方案因为全部工作都在同一个进程内完成,所以实现起来比较简单,不需要考虑进程间通信,也不用担心多进程竞争。
6.4.3 缺点
但是,这种方案存在 2 个缺点:
-
第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
-
第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
6.4.4 应用场景和实例
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
Redis 是由 C 语言实现的,它采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
Redis将数据存放在内存当中,这也就意味着,Redis在操作数据时,不需要进行磁盘I/O。磁盘I/O是一个比较耗时的操作,所以对于需要进行磁盘I/O的程序,我们可以使用多线程,在某个线程进行I/O时,CPU切换到当前程序的其他线程执行,以此减少CPU的等待时间。而Redis直接操作内存中的数据,所以使用多线程并不能有效提升效率,相反,使用多线程反倒会因为需要进行线程的切换而降低效率。
除此之外,使用多线程的话,多个线程间进行同步,保证线程的安全,也是需要开销的。尤其是Redis的数据结构都是一些实现较为简单的集合结构,若使用多线程,将会频繁地发生线程冲突,线程的竞争频率较高,反倒会拖慢Redis的响应速度。
综上所述,Redis为了保持简单和高效,自然而然地就使用了单线程。
6.5 单 Reactor 单进程 / 线程
6.5.1 流程图
如果要克服「单 Reactor 单线程 / 进程」方案的缺点,那么就需要引入多线程 / 多进程,这样就产生了单 Reactor 多线程 / 多进程的方案。
闻其名不如看其图,先来看看「单 Reactor 多线程」方案的示意图如下:

6.5.2 流程图分析
详细说一下这个方案:
-
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
-
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
-
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
-
Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
-
子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
6.5.3 优点和缺点
6.5.3.1 优点
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。
6.5.3.2 缺点
- 资源共享导致的竞争
例如,子线程完成业务处理后,要把结果传递给主线程的 Reactor 进行发送,这里涉及共享数据的竞争。
要避免多线程由于竞争共享资源而导致数据错乱的问题,就需要在操作共享资源前加上互斥锁,以保证任意时间里只有一个线程在操作共享资源,待该线程操作完释放互斥锁后,其他线程才有机会操作共享数据。
- 单 Reactor 多进程的通信(资源共享)
聊完单 Reactor 多线程的方案,接着来看看单 Reactor 多进程的方案。
事实上,单 Reactor 多进程相比单 Reactor 多线程实现起来很麻烦,主要因为要考虑子进程 <-> 父进程的双向通信,并且父进程还得知道子进程要将数据发送给哪个客户端。
而多线程间可以共享数据,虽然要额外考虑并发问题,但是这远比进程间通信的复杂度低得多,因此实际应用中也看不到单 Reactor 多进程的模式。
- 单 Reactor 的压力
另外,「单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
6.6 多 Reactor 多进程 / 线程
6.6.1 流程图
要解决「单 Reactor」的问题,就是将「单 Reactor」实现成「多 Reactor」,这样就产生了第 多 Reactor 多进程 / 线程的方案。
老规矩,闻其名不如看其图。多 Reactor 多进程 / 线程方案的示意图如下(以线程为例):
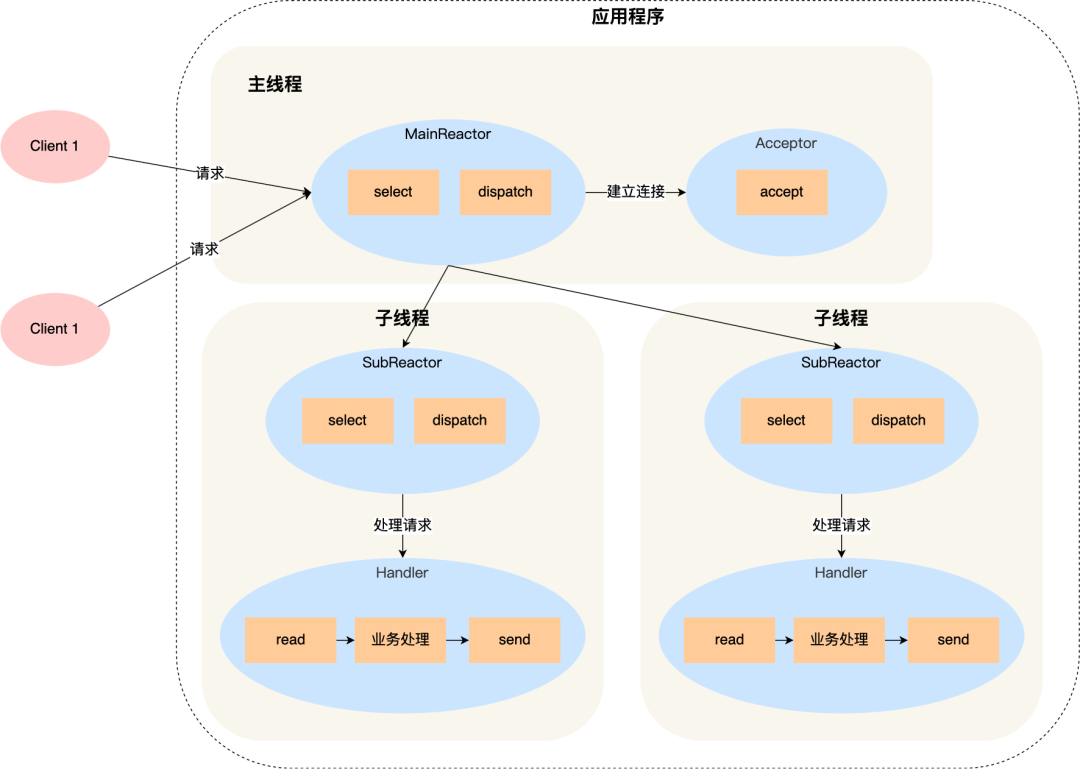
6.6.2 流程图分析
方案详细说明如下:
-
主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
-
子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
-
如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
-
Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
-
主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
-
主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
6.6.3 应用场景和实例
大名鼎鼎的两个开源软件 Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案。
采用了「多 Reactor 多进程」方案的开源软件是 Nginx,不过方案与标准的多 Reactor 多进程有些差异。
具体差异表现在主进程中仅仅用来初始化 socket,并没有创建 mainReactor 来 accept 连接,而是由子进程的 Reactor 来 accept 连接,通过锁来控制一次只有一个子进程进行 accept(防止出现惊群现象),子进程 accept 新连接后就放到自己的 Reactor 进行处理,不会再分配给其他子进程。
七、Proactor总结
7.1 背景
前面提到的 Reactor 是非阻塞同步网络模式,而 Proactor 是异步网络模式。
7.1.1 阻塞 I/O分析
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:
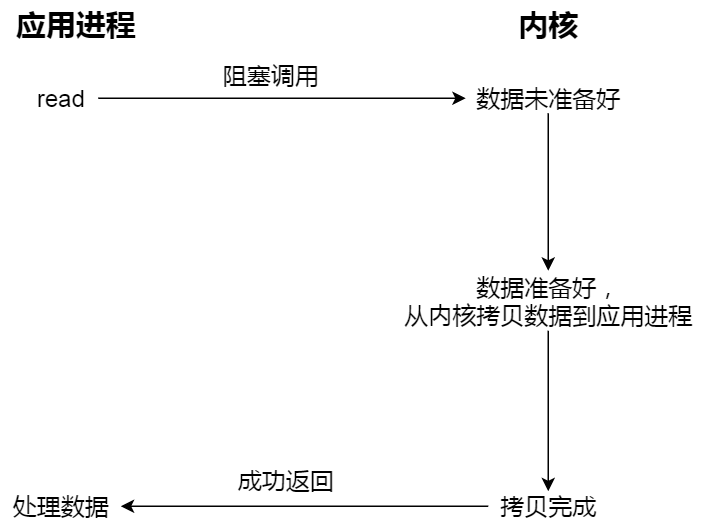
7.1.2 阻塞 I/O分析
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
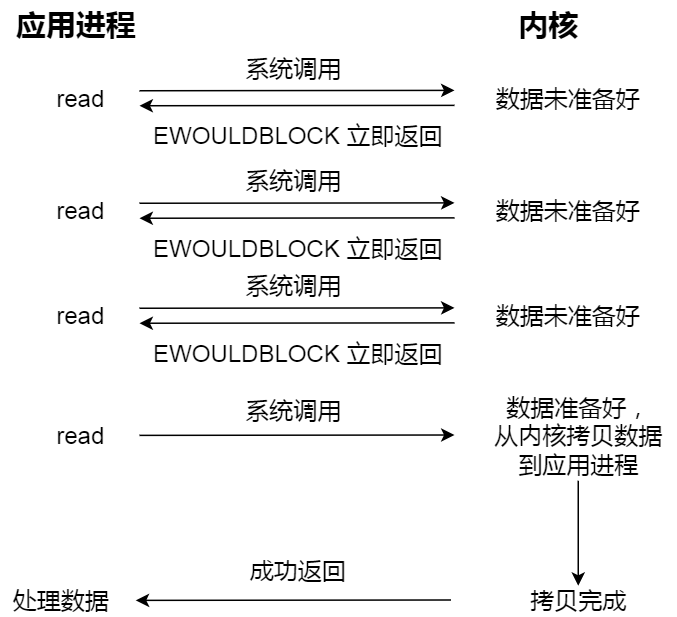
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
7.1.3 同步和异步分析
举个例子,如果 socket 设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
因此,无论 read 和 send 是阻塞 I/O,还是非阻塞 I/O 都是同步调用。因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
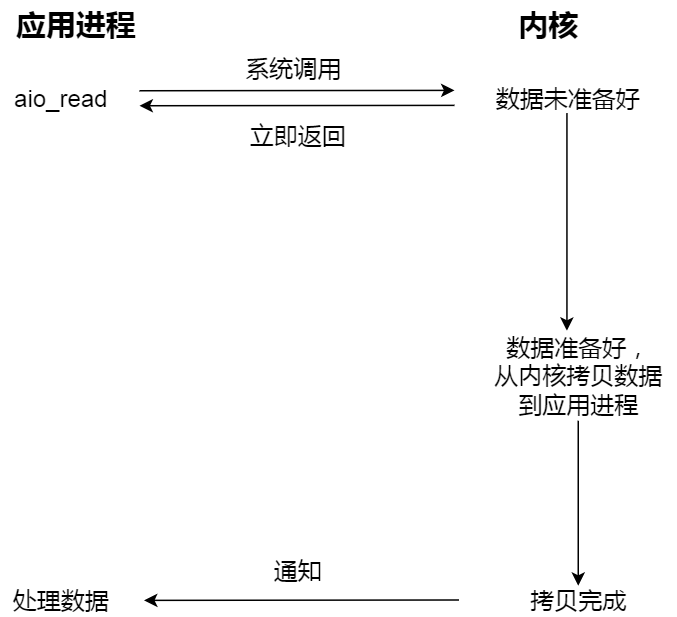
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
举个你去饭堂吃饭的例子,你好比应用程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
很明显,异步 I/O 比同步 I/O 性能更好,因为异步 I/O 在「内核数据准备好」和「数据从内核空间拷贝到用户空间」这两个过程都不用等待。
7.2 Proactor
7.2.1 Proactor和Reactor对比
Proactor 正是采用了异步 I/O 技术,所以被称为异步网络模型。现在我们再来理解 Reactor 和 Proactor 的区别,就比较清晰了。
-
-
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。需要注意的是,这里所属的非阻塞是指使用的socket是非阻塞的,但是用户进程依然是阻塞的,与前面的分析并不冲突,在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
-
Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
-
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
举个实际生活中的例子,Reactor 模式就是快递员在楼下,给你打电话告诉你快递到你家小区了,你需要自己下楼来拿快递。而在 Proactor 模式下,快递员直接将快递送到你家门口,然后通知你。
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
7.2.2 Proactor 模式的示意图

7.2.3 Proactor 模式的示意图分析
介绍一下 Proactor 模式的工作流程:
- Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过Asynchronous Operation Processor 注册到内核;
- Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
- Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
- Handler 完成业务处理;
7.3 Proactor 模式的问题
可惜的是,在 Linux 下的异步 I/O 是不完善的,aio系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案,linux也有内核级别的异步IO操作函数libaio,但是存在着一定的缺陷,所有的文件打开的时候必须包含书O_DIRECT标志,并非所有的文件系统都支持该类接口,如果不支持,IO操作就会变成阻塞的,当然,如果你不添加O_DIRECT标志,它锁使用的IO操作也是阻塞的。
而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 IOCP,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。
7.4 小结
常见的 Reactor 实现方案有三种。
第一种方案单 Reactor 单进程 / 线程,不用考虑进程间通信以及数据同步的问题,因此实现起来比较简单,这种方案的缺陷在于无法充分利用多核 CPU,而且处理业务逻辑的时间不能太长,否则会延迟响应,所以不适用于计算机密集型的场景,适用于业务处理快速的场景,比如 Redis 采用的是单 Reactor 单进程的方案。
第二种方案单 Reactor 多线程,通过多线程的方式解决了方案一的缺陷,但它离高并发还差一点距离,差在只有一个 Reactor 对象来承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
第三种方案多 Reactor 多进程 / 线程,通过多个 Reactor 来解决了方案二的缺陷,主 Reactor 只负责监听事件,响应事件的工作交给了从 Reactor,Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案,Nginx 则采用了类似于 「多 Reactor 多进程」的方案。
Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。
因此,真正的大杀器还是 Proactor,它是采用异步 I/O 实现的异步网络模型,感知的是已完成的读写事件,而不需要像 Reactor 感知到事件后,还需要调用 read 来从内核中获取数据。
不过,无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件,这个完成指的是数据的读取已经完成,实际上单Reactor多线程就是一种模拟的Proactor。
八、参考文章
https://mp.weixin.qq.com/s/iHAMwuWk1XZUnM66FUIY_w
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15127013.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号