Memcached
一、为什么使用缓存
如图1,为了快速应对早期的业务快速发展,我们架设一个超级简单的Web服务,只有一台应用服务器和DB,这种架构简单,便于快速开发和部署。但随着应用服务器的QPS不断增长,水涨船高,DB的QPS也逐渐提升,对DB的响应时间也有很高要求,单DB已无法快速满足业务发展。这时候可以考虑对DB进行分库分表,或者读写分离等方式以满足业务的发展。但是这些方式仍然有很多问题:
- 性能提升有限,很难达到数量级上的提升,至于原因,我将再写一篇文章论述。如果业务发展迅速,访问量将会指数上升,仅仅依赖DB对于响应时间的降低帮助不大。
- 成本高昂,为了应对N倍访问量,需要增加N倍DB服务器,成本难以接受。
-
DB为了数据高可靠,牺牲性能,具体表现为数据是存储到硬盘中,而不是内存,这样即使DB重启保证数据不会丢失。所以访问DB常常要从硬盘读取数据,从图2可以看出硬盘的读取时间远远大于内存的。
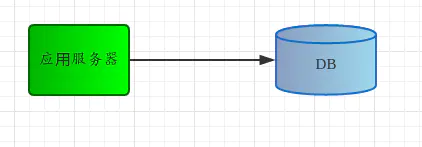
图1 最简单的Web架构
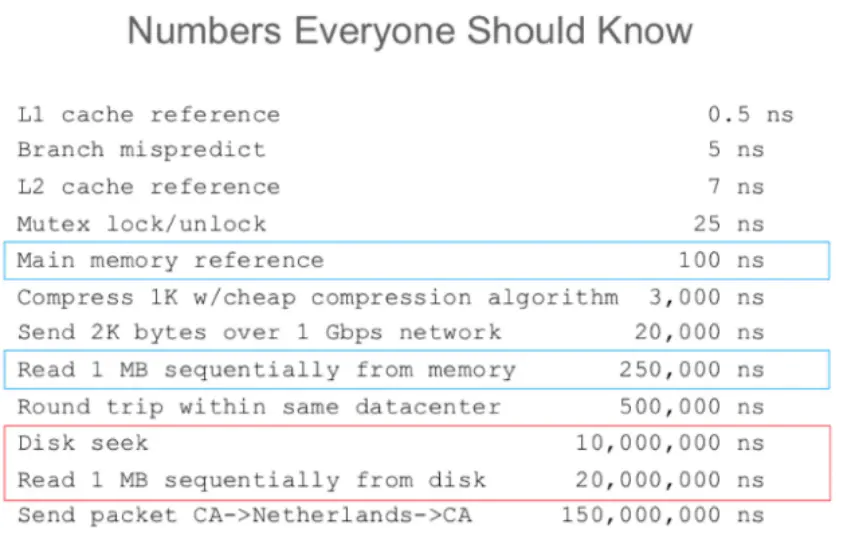
图2 服务器不同级别的访问时间
在大部分业务场景下,数据的读取符合二八原则,即80%的访问量是落到20%的热点数据上,假设我们把这20%热点数据通过内存保存起来,在访问这20%数据时先访问保存的内存地方,这就是缓存。这将极大提升数据读取速度,最终降低请求的响应时间,提高QPS。为了解决上面提出的问题,引入缓存组件,将热点数据缓存到内存中,架构图如图3所示。应用服务器读取数据的顺序为:
- 第一步,从缓存读取数据,如果有数据,直接返回数据;
- 第二步,从DB读取数据,保存到缓存,返回数据。
因此,Web架构引入缓存后:
- 提升数据读取速度,降低请求响应时间,承受更多的请求量;
- 提升系统扩展能力,缓存的内存空间不足,可以横向扩展缓存组件,提升系统承载能力;
-
降低存储成本,Cache+DB承受更多请求量,大大减少原有需要承受这么多请求量的DB服务器。

图3 引入缓存的简单Web架构
二. 缓存分类
选择缓存作为Web架构的数据读取组件后,下一步根据业务场景选择具体的缓存组件,从缓存数据分布的特点对比表如下。
- 本地缓存如果使用在数据变化率高的场景,即无明显高频次的数据读取,缓存数据使用内存越多,挪用Web应用的内存资源就越多,反而降低应用的性能;
- 伸缩性差表现在无法横向扩展本地缓存,并且如果要清除缓存内容,只能逐台服务器清除,达不到分布式缓存的一次性清除缓存的效果。

从数据存储方式看,对比表如下。
- 内存模式要考虑重启机器内存数据丢失,运维复杂度也很高,但是相对于磁盘持久化模式而言,少了维护数据持久化到硬盘的功能,所以运维复杂度相对较低。

三、Memcached特性
Memcached作为一款经典的缓存组件,具备极高的读取性能,下面将从四个特性分析Memcached的高性能。
- 协议简单
- Memcached支持文本和二进制协议;
- 文本协议调试简单,内容可视化;
- 二进制性能高效,且相对文本协议安全性高。
- 基于libevent的事件处理
- 使用IO多路复用的IO模型,Linux系统下使用epoll处理数据读写,具备极高的IO性能。
- 内置内存存储方式
- 所有数据存放在内存,相对于Linux提供的malloc/free产生的内存碎片,Memcached独特的内存存储方式可以避免内存碎片,提高内存利用率和性能。
- 因为数据存储在内存中,所以重启Memcached和操作系统,数据将全部丢失。
- Memcached互不通信的分布式
- Memcached实际上不是一个真正的分布式服务器,集群的各个Memcached服务器不互相通信以共享数据,分布式特性通过客户端实现。实际上这也避免分布式集群特有的问题:脑裂。
Memcached协议和基于libevent的事件处理都不是Memcached特有的特性,所以本文重点分享Memcached内置内存存储方式和不互相通信的分布式的特性。
四、Slab Allocation
传统的内存分配是通过malloc/free实现,易产生内存碎片,加重操作系统内存管理器的负担。Memcached使用Slab Allocation机制高效管理内存,Slab Allocation机制按照一个特定的增长比例,将分配的内存分割成特定长度的块,完全解决内存碎片问题。
Slab Allocation将内存分割成不同Slab Class,把相同尺寸的块(Chunk)组成组(Slab),如图4所示。Slab Allocation重复使用已分配的内存块,覆盖原有内存块的数据。
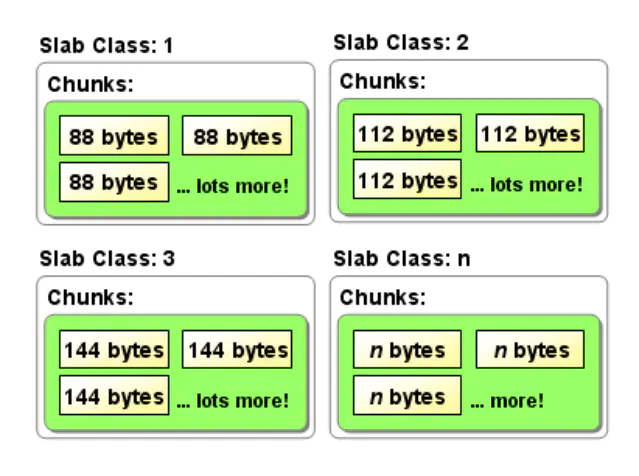
图4 Slab Class
首先介绍Slab Allocation的概念:
- Page:操作系统的内存页,分配给Slab的内存空间,默认1MB;
- Chunk:用于缓存记录的内存空间,不同Slab的Chunk大小通过一个特定增长比例逐渐增大;
- Slab:特定大小的Chunk的组,同一个Page分割成相同大小的Chunk,组成一个Slab。
Memcached根据数据大小选择最合适的Slab,如图5所示,100 bytes items选择112 bytes的Slab Chunk存储数据,内存空间利用率最高,其中items包含缓存数据的key/value等,具体请查看拙作[Memcached] Slab Allocation的MC项占用空间分析及实践。
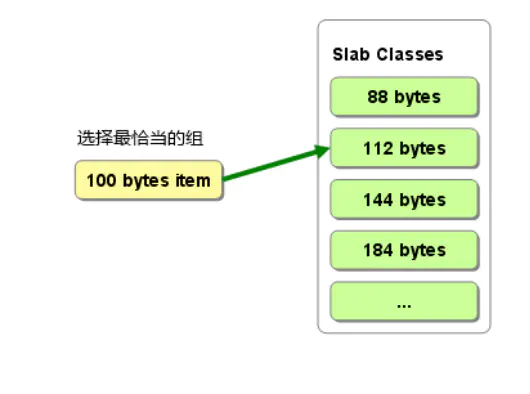
图5 数据选择最合适的Slab
1 (88+112)/2/112=89% 112 bytes的Chunk存放的期望大小是(88+112)/2,所以期望内存利用率是89%,其他同理。
2 (112+144)/2/144=89%
3 (144+184)/2/184=89%
4 ...
如下,根据不同Growth Factor推出期望内存利用率,当真实内存利用率达到期望内存利用率,警惕Memcached踢出数据,例子[Memcached] 为什么MC达到90%的内存利用率时开始踢出数据?
1 Growth Factor=2 : (n+2*n)/2/2n=75%
2 Growth Factor=1.25 : (n+1.25*n)/2/1.25n=90%
3 Growth Factor=gf : (n+gf*n)/2/(gf*n)=(1+gf)/2gf


图7 Growth Factor=1.25的Slab Alloaction
五、Memcached删除机制
- 数据不会真正从Memcached消失
- Memcached不会主动释放已分配的内存,记录超时后,客户端get该记录,Memcached不会返回该记录,并标志该记录过期失效,此时内存空间可重复使用。
- Lazy Expiration
- Memcached内部不会监视记录是否过期,而是客户端get时查看记录的时间戳,检查记录是否过期,如果过期,标志为过期,下次存放新记录优先使用过期记录占用的内存,这种技术就是Lazy Expiration,Memcached不会在过期监控上耗费CPU资源。
- LRU: Least Recently Used
- 从缓存中有效删除数据原理。Memcached优先使用记录已超时和未使用的内存空间,但是在追加新记录时如果没有记录已超时和未使用的内存空间,此时使用Least Recently Used(LRU)机制分配空间。顾名思义,就是删除”最近最少使用“的记录的机制。当Memcached内存空间不足(无法从Slab获取Chunk)时,就删除”最近最少使用“的记录,将其内存空间分配给新记录存放。从缓存使用角度,该模型非常理想。如果想关闭LRU机制,启动Memcached指定-M参数即可。
- Slab 钙化
- 请参考拙作[Memcached] Slab钙化问题
六、Memcached保存记录过程
图8为Memcached保存item流程图,具体步骤为:
- 第一步,从LRU队列寻找过期item,这里的LRU队列是相同Slab一个队列,而不是全局统一,过期item标记方法通过Lazy Expiration实现,如果有过期的item,使用新item替换过期item,结束;
- 第二步,如果没有过期item,查看是否有合适空闲的Chunk,如果有,保存新item到空闲Chunk,结束;
- 第三步,如果没有合适空闲的Chunk,尝试初始化一个新同等Chunk size的Slab,检查内存是否足够,如果够,分配内存创建Slab和Chunk,并使用Chunk存放新item,结束;
- 第四步,如果内存不够,从LRU队列淘汰最近最少使用的item,然后用这个Chunk存放新item,结束。注意这一步将导致非过期LRU数据丢失。

图8 Memcached保存记录过程
七、Memcached内存储存学习启示
- 尽量避免缓存大对象,大对象降低内存利用率和命中率
- 缓存/节点失效后大量请求涌向数据库,容易造成雪崩
- 利用组件在预警时间之后失效时间之间访问缓存,主动刷新缓存
- 关键业务数据不要放MC,LRU机制导致缓存数据删除,影响业务
八、Memcached不互相通信的分布式特征
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能,各个memcached不会互相通信以共享信息,由客户端的实现访问Memcached集群。如图9,应用程序通过MC客户端程序库访问MC集群,MC客户端程序库根据Hash算法从服务器列表选择一台MC服务器存放数据,各个MC之间不共享数据,也就没有脑裂问题。

九、一致性Hash算法
MC客户端程序库根据普通的Hash取余算法选择MC服务器存放数据,如果移除或者新增MC服务器,MC客户端程序库要根据服务器列表总数重新取余,就会选择一台其他的MC服务器存储数据,而该台服务器没有缓存上一台服务器的数据,所以导致大量数据发起大量请求访问DB获取数据,容易造成雪崩问题。
为了解决Hash取余算法的固有缺点,MC引入一致性Hash算法,如果图10所示,首先求出MC服务器(节点)的哈希值,将其分配到0~2^32的环上。然后用同样的方法求出存放数据的哈希值,映射到环上,并从数据映射的位置开始顺时针查找,将数据存放到最近的一个MC节点。如果超过2^32仍然找不到服务器,就会保存到第一台MC节点上。获取数据的查找方式也是如此。


图11 一致性Hash:添加服务器
图12的哈希表或许更加直观,md5根据key值摘要一个128bit的哈希值(校验和),一般表示为32位的16进制数,我们取哈希值的第一位范围将key映射到不同节点,如图12左侧表格所示。当新增一个节点5,把原本映射到节点4的一半数据映射到节点5,其他三个节点不受影响。但是引出数据在MC节点上分布不均匀的问题,原本左侧表格每个节点映射的数据量一样,但是右侧表格的节点4/5只有其他三个节点的一半数据量,导致节点4/5的带宽和内存使用率一直不饱满。

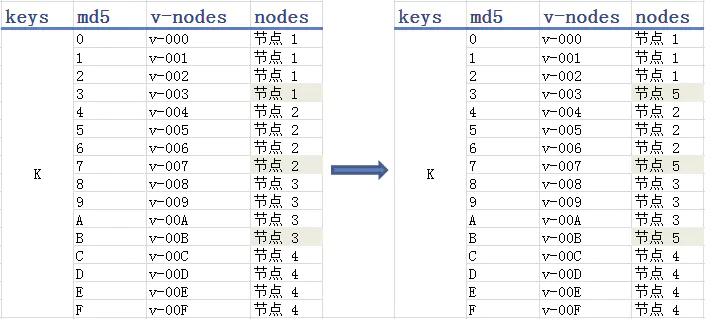
图13 一致性Hash:引入虚拟节点
一致性Hash算法启示
- 副本存储到多个节点,避免单点故障或者数据失效大量请求涌向DB
- 节点故障后,有快速预热新节点应急手段,或者使用冷节点备份
十、Memcached一些疑难问题
1. 为什么不能用缓存保存session?
2. 为什么同一个MC的数据,有的缓存(值较大的旧数据)要2天才被置换出,有的缓存(值较小的新数据)几分钟就被置换出?
值较大的数据占用Slab Class的大Chunk size,值较小的数据占用Slab Class的小Chunk size,根据Slab钙化问题,当值较小的数据占用Slab Class空间不够用时,并且没有多余的内存和过期的数据,不会挪用值较大的数据占用Slab Class空间,只会复用原有值较小的数据占用Slab Class空间,根据LRU算法置换出同一种Slab的Chunk数据。
3. Cache失效后的拥堵问题
通常我们会为两种数据做Cache,一种是热数据,也就是说短时间内有很多人访问的数据;另一种是高成本的数据,也就说查询很耗时的数据。当这些数据过期的瞬间,如果大量请求同时到达,那么它们会一起请求后端重建Cache,造成拥堵问题。
一般有如下几种解决思路可供选择:
- 首先,通过定时任务主动更新Cache;
其次,我们可以加分布式锁,保证只有一个请求访问数据库更新缓存。
4. Multiget的无底洞问题
出于效率的考虑,很多Memcached应用都以Multiget操作为主,随着访问量的增加,系统负载捉襟见肘,遇到此类问题,直觉通常都是增加服务器来提升系统性能,但是在实际操作中却发现问题并不简单,新加的服务器好像被扔到了无底洞里一样毫无效果。Multiget根据key请求多台服务器,但这并不是问题的症结,真正的原因在于客户端在请求多台服务器时是并行的还是串行的!问题是很多客户端,在处理Multiget多服务器请求时,使用的是串行的方式!也就是说,先请求一台服务器,然后等待响应结果,接着请求另一台,结果导致客户端操作时间累加,请求堆积,性能下降。
5. 缓存命中率下降,但是内存的利用率很高时,我们需要如何进行处理?
内存空间不足,导致缓存失效移除,命中率下降,既然内存利用率高,扩容MC服务器
6. 缓存命中率下降,内存的利用率也在下降时,我们需要如何进行处理?
跟问题2类似,也是Slab钙化问题。空间利用率高的Slab Class不会使用空间利用率低的其他的Slab Class,导致空间利用率高的Slab Class不断因为LRU踢出数据,总体而言,缓存命中率下降,内存的利用率也会下降。
Slab钙化降低内存使用率,如果发生Slab钙化,有三种解决方案:
- 重启Memcached实例,简单粗暴,启动后重新分配Slab class,但是如果是单点可能造成大量请求访问数据库,出现雪崩现象,冲跨数据库。
- 随机过期:过期淘汰策略也支持淘汰其他slab class的数据,twitter工程师采用随机选择一个Slab,释放该Slab的所有缓存数据,然后重新建立一个合适的Slab。
- 通过slab_reassign、slab_authmove。
7. 通常情况下,缓存的粒度越小,命中率会越高。
举个实际的例子说明:当缓存单个对象的时候(例如:单个用户信息),只有当该对象对应的数据发生变化时,我们才需要更新缓存或者移除缓存。而当缓存一个集合的时候(例如:所有用户数据),其中任何一个对象对应的数据发生变化时,都需要更新或移除缓存。
由于序列化和反序列化需要一定的资源开销,当处于高并发高负载的情况下,对大对象数据的频繁读取有可能会使得服务器的CPU崩溃。
8. 缓存被“击穿”问题
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑另外一个问题:缓存被“击穿”的问题。
- 概念:缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 如何解决:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。类似下面的代码:
1 static Lock reenLock = new ReentrantLock(); 2 3 public List<String> getData04() throws InterruptedException { 4 List<String> result = new ArrayList<String>(); 5 // 从缓存读取数据 6 result = getDataFromCache(); 7 if (result.isEmpty()) { 8 if (reenLock.tryLock()) { 9 try { 10 System.out.println("我拿到锁了,从DB获取数据库后写入缓存"); 11 // 从数据库查询数据 12 result = getDataFromDB(); 13 // 将查询到的数据写入缓存 14 setDataToCache(result); 15 } finally { 16 reenLock.unlock();// 释放锁 17 } 18 19 } else { 20 result = getDataFromCache();// 先查一下缓存 21 if (result.isEmpty()) { 22 System.out.println("我没拿到锁,缓存也没数据,先小憩一下"); 23 Thread.sleep(100);// 小憩一会儿 24 return getData04();// 重试 25 } 26 } 27 } 28 return result; 29 }还可以使用分级缓存;采用 L1 (一级缓存)和 L2(二级缓存) 缓存方式,L1 缓存失效时间短,L2 缓存失效时间长。 请求优先从 L1 缓存获取数据,如果 L1缓存未命中则加锁,只有 1 个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到 L1 缓存和 L2 缓存中,而其他线程依旧从 L2 缓存获取数据并返回。这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更 新时,只能淘汰 L1 缓存,不能同时将 L1 和 L2 中的缓存同时淘汰。L2 缓存中 可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案 可能会造成额外的缓存空间浪费。
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15072746.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号