libco学习三
Libco 协程的生命周期
创建协程(Creating coroutines)
前文已提到,libco 中创建协程是 co_create() 函数。函数声明如下:
1 int co_create( stCoRoutine_t **co,const stCoRoutineAttr_t *attr,void *(*routine)(void*),void *arg );
同 pthread_create 一样,该函数有四个参数:
1、co: stCoRoutine_t** 类型的指针。输出参数,co_create 内部会为新协程分配⼀个 “协程控制块”,*co 将指向这个分配的协程控制块,传出参数。
2、attr: stCoRoutineAttr_t* 类型的指针。输⼊参数,用于指定要创建协程的属性,可 为 NULL。实际上仅有两个属性:栈⼤小、指向共享栈的指针(使用共享栈模式)。
3、routine: void* (*)(void *) 类型的函数指针,指向协程的任务函数,即启动这个协 程后要完成什么样的任务。routine 类型为函数指针。
4、arg: void* 类型指针,传递给任务函数的参数,类似于 pthread 传递给线程的参数。 调用 co_create 将协程创建出来后,这时候它还没有启动,也即是说我们传递的 routine 函数还没有被调用。实质上,这个函数内部仅仅是分配并初始化 stCoRoutine_t 结构体、设置任务函数指针、分配一段“栈”内存,以及分配和初始化 coctx_t。为什么 这里的“栈”要加个引号呢?因为这里的栈内存,无论是使用预先分配的共享栈,还是 co_create 内部单独分配的栈,其实都是调用 malloc 从进程的堆内存分配出来的。对于协程而言,这就是“栈”,而对于底层的进程(线程)来说这只不过是普通的堆内存而已。
stCoRoutineAttr_t结构
1 struct stCoRoutineAttr_t
2 {
3 int stack_size; //栈大小
4 stShareStack_t* share_stack; //共享栈
5 stCoRoutineAttr_t() //类似于构造函数
6 {
7 stack_size = 128 * 1024;
8 share_stack = NULL;
9 }
10 }__attribute__ ((packed));
co_create 函数源码
1 int co_create( stCoRoutine_t **ppco,const stCoRoutineAttr_t *attr,pfn_co_routine_t pfn,void *arg )
2 {
3 if( !co_get_curr_thread_env() )//判断当前进程(线程)的 stCoRoutineEnv_t 结构也就是环境变量是否已分配
4 {
5 co_init_curr_thread_env();//如果未分配则分配一个
6 }
7 //创建协程控制块
8 stCoRoutine_t *co = co_create_env( co_get_curr_thread_env(), attr, pfn,arg );
9 *ppco = co;
10 return 0;
11 }
启动协程(Resume a coroutine)
在调用 co_create 创建协程返回成功后,便可以调用 co_resume 函数将它启动了。该函数声明如下:
1 void co_resume( stCoRoutine_t *co );
它的意义很明了,即启动 co 指针指向的协程。值得注意的是,为什么这个函数不叫 co_start 而是 co_resume 呢?前文已提到,libco 的协程是非对称协程,协程在让出 CPU 后要恢复执行的时候,还是要再次调用一下 co_resume 这个函数的去“启动”协程运行的。从语义上来讲,co_start 只有一次,而 co_resume 可以是暂停之后恢复启动,可以多次调用,就这么个区别。实际上,看早期关于协程的文献,讲到非对称协程,一般 也都用“resume”与“yield”这两个术语。协程要获得 CPU 执行权用“resume”,而让出 CPU 执行权用“yield”,这是两个是两个不同的(不对称的)过程,因此这种机制才被称为非对称协程(asymmetric coroutines)。
所以讲到 resume 一个协程,我们一定得注意,这可能是第一次启动该协程,也可以是要准备重新运行挂起的协程。我们可以认为在 libco 里面协程只有两种状态,即 running 和 pending。当创建一个协程并调用 resume 之后便进入了 running 状态,之后协程可能通过 yield 让出 CPU,这就进入了 pending 状态。不断在这两个状态间循环往复, 直到协程退出(执行的任务函数 routine 返回),如图2所示(TBD 修改状态机)。
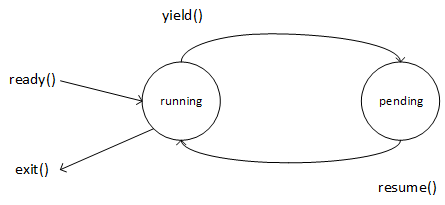
非对称协程状态转换图
需要指出的是,不同于 go 语言,这里 co_resume() 启动一个协程的含义,不是“创建一个并发任务”。进入 co_resume() 函数后发生协程的上下文切换,协程的任务函数是立即就会被执行的,而且这个执行过程不是并发的(Concurrent)。为什么不是并发的 呢?因为 co_resume() 函数内部会调用 coctx_swap() 将当前协程挂起,然后就开始执行目标协程的代码了(具体过程见下文协程切换那一篇的分析)。本质上这个过程是串行的,在一个操作系统线程(进程)上发生的,甚至可以说在一颗 CPU 核上发生的(假 定没有发生 CPU migration)。让我们站到 Knuth 的角度,将 coroutine 当做一种特殊的 subroutine 来看,问题会显得更清楚:A 协程调用 co_resume(B) 启动了 B 协程,本质上是一种特殊的过程调用关系,A 调用 B 进入了 B 过程内部,这很显然是一种串行执行的关系。那么,既然 co_resume() 调用后进入了被调协程执行控制流,那么 co_resume() 函数本身何时返回?这就要等被调协程主动让出 CPU 了,也就是被调用协程执行yield()函数。
co_resume() 函数代码实现
1 void co_resume( stCoRoutine_t *co )
2 {
3 stCoRoutineEnv_t *env = co->env;
4 //当前协程控制块指针,
5 stCoRoutine_t *lpCurrRoutine = env->pCallStack[ env->iCallStackSize - 1 ];
6 if( !co->cStart )//当且仅当协程是第一次启动时才会执行到。
7 {
8 //当协程第一次启动的时候,它的上下文并没有被设置,初始化当前协程的上下文
9 coctx_make( &co->ctx,(coctx_pfn_t)CoRoutineFunc,co,0 );
10 //协程上下文是否被初始化,0:位初始化,1:初始化
11 co->cStart = 1;
12 }
13 //保存调用关系,将该协程压入pCallStack数组,并增加iCallStackSize
14 env->pCallStack[ env->iCallStackSize++ ] = co;
15 /**
16 * 实现协程的切换,实际上协程的切换就是协程的上下文的切换
17 * lpCurrRoutine:当前运行协程的协程控制块
18 * co:将要运行的协程的协程控制块
19 */
20 co_swap( lpCurrRoutine, co );
21 }
第 5、6 行 的 if 条件分支,当且仅当协程是第一次启动时才会执行到。首次启动协程过程有点特殊,需要调用 coctx_make() 为新协程准备 context(为了让 co_swap() 内能跳转到新启动协程的任务函数,),并将 cStart 标志变量置 1。第 4~7 行是首次启动协程才执行的特殊逻辑,那么 co_resume() 仅有 4 行代码而已。第 3 行取当前协程控制块指针,第 8 行将待启动的协程 co 压入 pCallStack 栈,然后第 9 行就调用 co_swap() 切换到 co 指向的新协程上去执 行了。co_swap() 不会就此返回,而是要这次 resume 的 co 协程主动 yield 让出 CPU 时才会返回到 co_resume() 中来。
值得指出的是,这里讲 co_swap() 不会就此返回,不是说这个函数就阻塞在这里等待 co 这个协程yield 让出 CPU。实际上,后面我们将会看到,co_swap() 内部已经切换 了 CPU 执行上下文,奔着 co 协程的代码路径去执行了。整个过程不是并发的,而是串行的,这一点我们已经反复强调过了。
协程的挂起(Yield to another coroutine)
在非对称协程理论,yield 与 resume 是个相对的操作。A 协程 resume 启动了 B 协程,那么只有当 B 协程执行 yield 操作时才会返回到 A 协程。在上面剖析协程启动 函数 co_resume() 时,也提到了该函数内部 co_swap() 会执行被调协程的代码。只有被调协程 yield 让出 CPU,调用者协程的 co_swap() 函数才能返回到原点,即返回到原来 co_resume() 内的位置。 在前文解释 stCoRoutineEnv_t 结构 pCallStack 这个“调用栈”的时候,我们已经简要地提到了 yield 操作的内部逻辑。在被调协程要让出 CPU 时,会将它的 stCoRoutine_t 从 pCallStack 弹出,“栈指针”iCallStackSize 减 1,然后 co_swap() 切换 CPU 上下文到原来 被挂起的调用者协程恢复执行。这里“被挂起的调用者协程”(该携程还在栈中,栈是一种先进后出的数据结构,这里实际上使用的数组),即是调用者 co_resume() 中切换 CPU 上下文被挂起的那个协程。下面我们来看一下 co_yield_env() 函数代码:
void co_yield_env( stCoRoutineEnv_t *env )
{
//获取调用的当前协程的协程的协程控制块
stCoRoutine_t *last = env->pCallStack[ env->iCallStackSize - 2 ];
//获取当前协程(也就是被调用协程)的协程控制块
stCoRoutine_t *curr = env->pCallStack[ env->iCallStackSize - 1 ];
//栈大小减少1
env->iCallStackSize--;
//切换到使用co_resume的协程,“被挂起的调用者协程”,即是调用者 co_resume()中切换 CPU 上下文被挂起的那个协程。
co_swap( curr, last);
}
co_yield_env() 函数仅有 4 行代码,事实上这个还可以写得更简洁些。注意到这个函数为什么叫 co_yield_env 而不是 co_yield 呢?这个也很简单。我们知道 co_resume 是有明确目的对象的,而且可以通过 resume 将 CPU 交给任意协程。但 yield 则不一样,你只能 yield 给当前协程的调用者。而当前协程的调用者,即最初 resume 当前协程的协程,是保存在 stCoRoutineEnv_t 的 pCallStack 中的。因此你只能 yield 给“env”,yield 给调用者协程;而不能随意 yield 给任意协程,CPU 不是你想让给谁就能让给谁的。
1 void co_yield_ct()
2 {
3 co_yield_env( co_get_curr_thread_env() );
4 }
5 void co_yield( stCoRoutine_t *co )
6 {
7 co_yield_env( co->env );
8 }
1 //获取协程运行的协程环境
2 stCoRoutineEnv_t *co_get_curr_thread_env()
3 {
4 //是一个全局性的变量,用来保存运行协程的协程环境
5 //static __thread stCoRoutineEnv_t* gCoEnvPerThread = NULL;
6 return gCoEnvPerThread;
7 }
事实上,libco 提供了一个 co_yield(stCoRoutine_t*) 的函数。看起来你似乎可以将 CPU 让给任意协程。实际上并非如此,我们知道,同一个线程上所有协程是共享一个 stCoRoutineEnv_t 结构的,因此任意 协程的 co->env 指向的结构都相同。如果你调用 co_yield(co),就以为将 CPU 让给 co 协程了,那就错了。最终通过 co_yield_env() 还是会将 CPU 让给原来启动当前协程的调用者。可能有的读者会有疑问,同一个线程上所有协程共享 stCoRoutineEnv_t,那么我 co_yield() 给其他线程上的协程呢?对不起,如果你这么做,那么你的程序就挂了。libco 的协程是不支持线程间迁移(migration)的,如果你试图这么做,程序一定会挂掉。这 个 co_yield() 其实容易让人产生误解的。
再补充说明一下,协程库内虽然提供了 co_yield(stCoRoutine_t*) 函数,但是没有任何地方有调用过该函数(包括样例代码)。使用的较多的是另外一个函数—— co_yield_ct(),其实本质上作用都是一样的。
协程的切换(Context switch)
前面讨论的 co_yield_env() 与 co_resume(),是两个完全相反的过程,但他们的核心任务却是一样的——切换 CPU 执行上下文,即完成协程的切换。在 co_resume() 中,这个切换是从当前协程切换到被调协程;而在 co_yield_env() 中,则是从当前协程切换到调用者协程。最终的上下文切换,都发生在 co_swap() 函数内。 严格来讲这里不属于协程生命周期一部分,而只是两个协程开始执行与让出 CPU 时的一个临界点。既然是切换,那就涉及到两个协程。为了表述方便,我们把当前准备让出 CPU 的协程叫做 current 协程,把即将调入执行的叫做 pending 协程。
coctx_swap.S 汇编代码
1 .globl coctx_swap
2 #if !defined( __APPLE__ )
3 .type coctx_swap, @function
4 #endif
5 coctx_swap:
6
7 #if defined(__i386__)
8 movl 4(%esp), %eax
9 movl %esp, 28(%eax) //ESP 专门用作堆栈指针,被形象地称为栈顶指针,堆栈的顶部是地址小的区域,压入堆栈的数据越多,ESP也就越来越小。在32位平台上,ESP每次减少4字节。
10 movl %ebp, 24(%eax) //基址指针
11 movl %esi, 20(%eax) //源索引寄存器
12 movl %edi, 16(%eax) //目标索引寄存器
13 movl %edx, 12(%eax) //总是被用来放整数除法产生的余数。
14 movl %ecx, 8(%eax) //计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
15 movl %ebx, 4(%eax) //基地址"(base)寄存器, 在内存寻址时存放基地址。
16
17
18 movl 8(%esp), %eax
19 movl 4(%eax), %ebx
20 movl 8(%eax), %ecx
21 movl 12(%eax), %edx
22 movl 16(%eax), %edi
23 movl 20(%eax), %esi
24 movl 24(%eax), %ebp
25 movl 28(%eax), %esp
26
27 ret
28
29 #elif defined(__x86_64__)
这里截取的是coctx_swap.S 文件中针对 x86 体系结构的一段代码,x64 下的原理跟这是一样的,代码也在这同一个文件中。从宏观角度看,这里定义了一个名为 coctx_swap 的函数,而且是 C 风格的函数(因为要被 C++ 代码调用)。从调用方看,我们可以将它当做一个普通的 C 函数,函数原型如下:
1 extern "C" {
2 extern void coctx_swap(coctx_t*, coctx_t*) asm("coctx_swap");
3 };
coctx_swap 接受两个参数,无返回值。其中,第一个参数 curr 为当前协程的 coctx_t 结构指针,其实是个输出参数,函数调用过程中会将当前协程的 context (执行上下文)保存在这个参数指向的内存里;第二个参数 pending,即待切入的协程的 coctx_t 指针,是个输入参数, coctx_swap 从这里取上次保存的 context,恢复各寄存器的值。前面我们讲过 coctx_t 结构,就是用于保存各寄存器值(context)的。这个函数奇特之处,在于调用之前还处 第一个协程的环境,该函数返回后,则当前运行的协程就已经完全是第二个协程了。这 跟 Linux 内核调度器的 switch_to 功能是非常相似的,只不过内核里线程的切换比这还要复杂得多。正所谓“杨百万进去,杨白劳出来”,当然,这里也可能是“杨白劳进去, 杨百万出来”。 言归正题,这个函数既然是要直接操作寄存器,那当然非汇编不可了。汇编语言都快忘光了?那也不要紧,这里用到的都是常用的指令。值得一提的是,绝大多数学校汇编教程使用的都是 Intel 的语法格式,而这里用到的是 AT&T 格式。这里我们只需知道两者的主要差别,在于操作数的顺序是反过来的,就足够了。在 AT&T 汇编指令里,如果指令有两个操作数,那么第一个是源操作数,第二个即为目的操作数。
movl汇编指令
1 MOV指令的基本格式:
2 movx source, destination
3
4 source 和 destinatino 的值可以是内存地址,存储在内存中的数据值,指令语句中定义的数据值,或者是寄存器。
5
6 注意:GNU汇编器使用 AT&T 样式的语法,所以其中的源和目的操作数和 Intel 文档中给出的顺序是相反的。
7
8 GNU汇编器为 mov 指令添加了一个维度,在其中必须声明要传送的数据元素的长度。
9 通过吧一个附加字符添加到 MOV 助记符来声明这个长度。
10 因此,指令就变成了如下:
11 movx
12 其中 x 可以是下面的字符:
13 1,l用于32位的长字值
14 2,w用于16位的字值
15 3,b用于8位的字节值
16
17 实例:
18
19 movl %eax, %ebx #把32位的EAX寄存器值传送给32为的EBX寄存器值
20
21 movw %ax, %bx #把32位的EAX寄存器值传送给32为的EBX寄存器值
22
23 movb %al, %lx #把32位的EAX寄存器值传送给32为的EBX寄存器值
leal汇编指令
1 leal指令用于加载有效地址(loadeffective address)。
2
3 leal指令的目的操作数必须是寄存器。实际上leal指令有时用于与加载地址无关的场景。
4
5 示例:
6
7 leal 6(%eax), %edx //把eax的值+6放入edx中。
8
9 leal (%eax, %ecx), %edx //把eax+ecx的值装入edx中。
10
11 leal (%eax, %ecx, 4), %edx //把eax + 4*ecx的值装入edx中。
12
13 leal 7(%eax, %eax, 8), %edx //把9*eax +7的值装入edx中。
14
15 leal 0xA(,%eax,4), %edx //把4*eax + 10的值装入edx中。
16
17 leal 9(%eax, %ecx, 2), %edx //把eax + 2*ecx+ 9的值装入
此外,我们前面提到,这是个 C 风格的函数。什么意思呢?在 x86 平台下,多数 C 编译器会使用一种固定的方法来处理函数的参数与返回值。函数的参数使用栈传递, 且约定了参数顺序,如图3所示。在调用函数之前,编译器会将函数参数以反向顺序压栈,如图3中函数有三个参数,那么参数 3 首先 push 进栈,随后是参数 2,最后参数 1。 准备好参数后,调用 CALL 指令时 CPU 自动将 IP 寄存器(函数返回地址)push 进栈, 因此在进入被调函数之后,便形成了如图3的栈格局。函数调用结束前,则使用 EAX 寄存器传递返回值(如果 32 位够用的话),64 位则使用 EDX:EAX,如果是浮点值则使用 FPU ST(0) 寄存器传递。
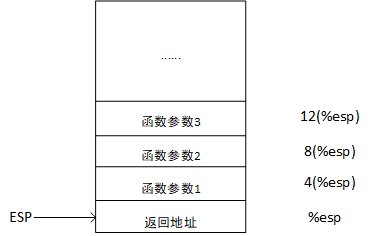
C 语言函数传递参数示意图
协程上下文
1 struct coctx_t
2 {
3 #if defined(__i386__)
4 void *regs[ 8 ];//用来保存协程切换时当前协程的各个寄存器的值
5 #else
6 void *regs[ 14 ];
7 #endif
8 size_t ss_size;
9 char *ss_sp;
10
11 };
接着,继续分析co_swap函数,它有两个参数,那么进入函数体后,第8行用 4(%esp) 便可以取到第一个参数(当前协程 context 指针),可以认为是将当前的栈顶地址保存下来(实际保存的地址比栈顶还要⾼ 4 字节,为了⽅便我们就称之为栈顶)。为什么要保存栈指针呢,因为紧接着就要 进⾏栈切换了。第9行开始就是将当前协程使用的寄存器的值全部保存在regs[ 8 ]数组中。从第18行开始就是将pending 协程的上下文恢复到寄存器中,继续上次伪完成的工作。
协程的退出
这里讲的退出,有别于协程的挂起,是指协程的任务函数执行结束后发生的过程。 更简单的说,就是协程任务函数内执行了 return 语句,结束了它的生命周期。这在某些场景是有用的。同协程挂起一样,协程退出时也应将 CPU 控制权交给它的调用者,这也是调用 co_yield_env() 函数来完成的。这个机制很简单,限于篇幅,具体代码就不贴出来了。 值得注意的是,我们调用 co_create()、co_resume() 启动协程执行一次性任务,当任务结束后要记得调用 co_free() 或 co_release() 销毁这个临时性的协程,否则将引起内存泄漏。
总结:
1、协程的创建
1.co_create函数、协程控制块(传出参数)、协程属性(栈大小,默认128K、指向共享栈的指针,不使用共享栈该指为NULL)、任务函数、任务函数的传入参数
2.无论是使用预先分配的共享栈,还是 co_create 内部单独分配的栈,其实都是调用 malloc 从进程的堆内存分配出来的。对于协程而言,这就是“栈”,而对于底层的进程(线程)来说这只不过是普通的堆内存而已。
3.第一个协程
libco 的第一个协程,即执行 main 函数的协程,是一个特殊的协程。这个协程又可以称作主协程,它负责协调其他协程的调度执行(后文我们会看到,还有网络 I/O 以及定时事件的驱动),它自己则永远不会 yield,不会主动让出 CPU。不让出(yield)CPU,不等于说它一直霸占着 CPU。我们知道 CPU 执行权有两种转移途径,一是通过 yield 让给 调用者,其二则是 resume 启动其他协程运行。主协程是跟 stCoRoutineEnv_t 一起创建的。主协程也无需调用 resume 来启动,它就是程序本身,就是 main 函数。主协程是一个特殊的存在,可以认为它只是一个结构体而已。在程序首次调用 co_create() 时,此函数内部会判断当前进程(线程)的 stCoRoutineEnv_t 结构是否已分配,如果未分配则分配一个,同时分配 一个 stCoRoutine_t 结构,并将 pCallStack[0] 指向主协程。此后如果用 co_resume() 启动协程,又会将 resume 的协程压入 pCallStack 栈。
4.协程运行的环境,也是在程序首次调用 co_create() 时,此函数内部会判断当前进程(线程)的 stCoRoutineEnv_t 结构是否已分配,如果未分配则分配一个,也就是环境变量与第一个协程(也就是主协程)一起创建。
2、协程的启动
libco库提供的是非对称协程,创建协程和启动协程是两个分开的独立的步骤,与go语言有所不同,使用的函数是co_resume() 函数,在该函数中会发生协程的切换,协程上下文的创建(如果该协程是第一次被进入运行状态),会导致pCallStack 的入栈操作。
3、协程的挂起
使用的函数是co_yield_env() 函数,所有该库提供的挂起函数如co_yield_ct和co_yield_ct底层都是使用co_yield_env实现的,实际上就是pCallStack 的出栈操作;co_resume 是有明确目的对象的,而且可以通过 resume 将 CPU 交给任意协程。但 yield 则不一样,你只能 yield 给当前协程的调用者;此外,libco 的协程是不支持线程间迁移(migration)的,如果你试图这么做,程序一定会挂掉。
4、协程的切换
使用的函数是co_swap,两个传入参数,第一个参数是当前协程的coctx_t变量,第二个参数是即将运行的协程的coctx_t变量;大致实现的操作就是将当前协程的上下文(也就是各个寄存器值)保存到coctx_t变量,然后将即将运行的协程的上下文(上次切换出保存的各个寄存器的值)恢复到各个寄存器。
5、协程的退出
如果某些协程只是完成一些零时性的任务,完成相应的任务后就会调用return结束生命周期,并返回调用者那里,这些协程就称为零时协程,当其生命周期结束时,需要调用 co_free() 或 co_release() 销毁这个临时性的协程,否则将引起内存泄漏。
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15028188.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号