Redis RDB 持久化详解
一、引言
1.1 持久化简介
Redis 是一种内存数据库,将数据保存在内存中,读写效率要比传统的将数据保存在磁盘上的数据库要快很多。但是一旦进程退出,Redis 的数据就会丢失。
为了解决这个问题,Redis 提供了 RDB 和 AOF 两种持久化方案,将内存中的数据保存到磁盘中,避免数据丢失。
antirez 在《Redis 持久化解密》一文中说,一般来说有三种常见的策略来进行持久化操作,防止数据损坏:
-
方法1 是数据库不关心发生故障,在数据文件损坏后通过数据备份或者快照来进行恢复。Redis 的 RDB 持久化就是这种方式。
-
方法2 是数据库使用操作日志,每次操作时记录操作行为,以便在故障后通过日志恢复到一致性的状态。因为操作日志是顺序追加的方式写的,所以不会出现操作日志也无法恢复的情况。类似于 Mysql 的 redo 和 undo 日志。
-
方法3 是数据库不进行老数据的修改,只是以追加方式去完成写操作,这样数据本身就是一份日志,这样就永远不会出现数据无法恢复的情况了。CouchDB就是此做法的优秀范例。
RDB 就是第一种方法,它就是把当前 Redis 进程的数据生成时间点快照( point-in-time snapshot ) 保存到存储设备的过程。
2.2 RDB优点和缺点
2.2.1 优点
- (1)只有一个文件(dump.rdb),持久化方便
- (2)容灾性好,一个文件可以安全保存到磁盘
- (3)性能最大化:fork子进程来完成写操作,主进程继续处理命令,所以是IO最大化。(主进程不涉及IO处理,子进程单独处理持久化,保证了Redis的高性能)
- (4)数据集较大时,启动效率更高(相比于AOF)
2.2.2 缺点
- 数据安全性低:隔一段时间进行持久化的机制,如果发生故障容易导致数据丢失
- 适用于数据要求不严谨的情况下
二、RDB 的使用
RDB 触发机制分为使用指令手动触发和 redis.conf 配置自动触发。
2.1 使用指令手动触发
手动触发 Redis 进行 RDB 持久化的指令的为:
-
save ,该指令会阻塞当前 Redis 服务器,执行 save 指令期间,Redis 不能处理其他命令,直到 RDB 过程完成为止。
-
bgsave,执行该命令时,Redis 会在后台异步执行快照操作,此时 Redis 仍然可以相应客户端请求。具体操作是 Redis 进程执行
fork操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。Redis 只会在fork期间发生阻塞,但是一般时间都很短。但是如果 Redis 数据量特别大,fork时间就会变长,而且占用内存会加倍,这一点需要特别注意。
2.2 自动触发
自动触发 RDB 的默认配置如下所示:
1 save 900 1 # 表示900 秒内如果至少有 1 个 key 的值变化,则触发RDB
2 save 300 10 # 表示300 秒内如果至少有 10 个 key 的值变化,则触发RDB
3 save 60 10000 # 表示60 秒内如果至少有 10000 个 key 的值变化,则触发RDB
如果不需要 Redis 进行持久化,那么可以注释掉所有的 save 行来停用保存功能,也可以直接一个空字符串来停用持久化:save ""。
Redis 服务器周期操作函数 serverCron 默认每个 100 毫秒就会执行一次,该函数用于正在运行的服务器进行维护,它的一项工作就是检查 save 选项所设置的条件是否有一项被满足,如果满足的话,就执行 bgsave 指令。
三、RDB 整体流程
3.1 简介
了解了 RDB 的基础使用后,我们要继续深入对 RDB持久化的学习。在此之前,我们可以先思考一下如何实现一个持久化机制,毕竟这是很多中间件所需的一个模块。
首先,持久化保存的文件内容结构必须是紧凑的,特别对于数据库来说,需要持久化的数据量十分大,需要保证持久化文件不至于占用太多存储。其次,进行持久化时,中间件应该还可以快速地响应用户请求,持久化的操作应该尽量少影响中间件的其他功能。最后,毕竟持久化会消耗性能,如何在性能和数据安全性之间做出平衡,如何灵活配置触发持久化操作。
接下来我们将带着这些问题,到源码中寻求答案。
3.2 持久化流程
本文中的源码来自 Redis 5.0.2,RDB持久化过程的相关源码都在 rdb.c 文件中。其中大概的流程如下图所示。
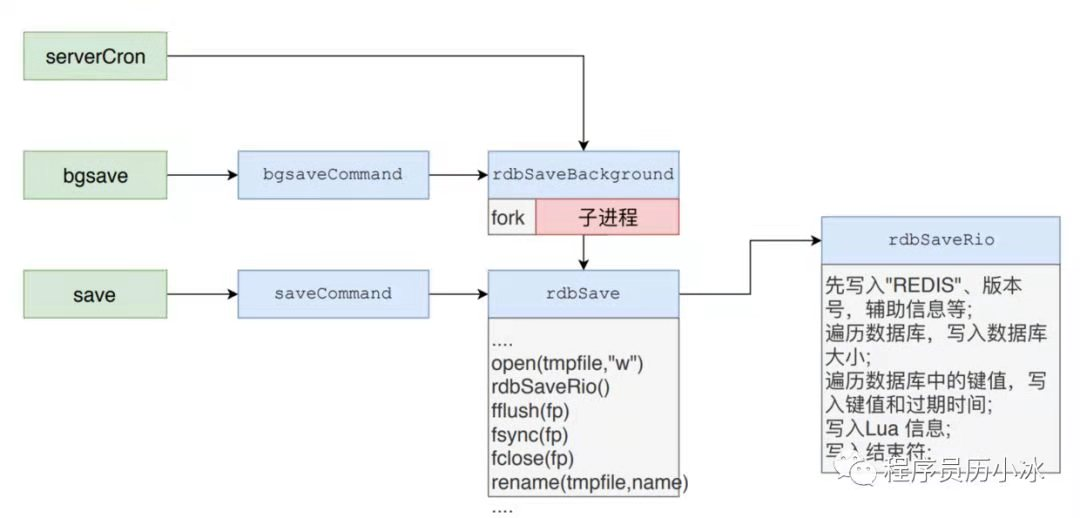
上图表明了三种触发 RDB 持久化的手段之间的整体关系。通过 serverCron 自动触发的 RDB 相当于直接调用了 bgsave 指令的流程进行处理。而 bgsave 的处理流程启动子进程后,调用了 save 指令的处理流程。
3.3 触发RDB的方式
1、serverCron(自动)
2、bgsave(手动)
3、save(手动)
四、自动触发 RDB 持久化
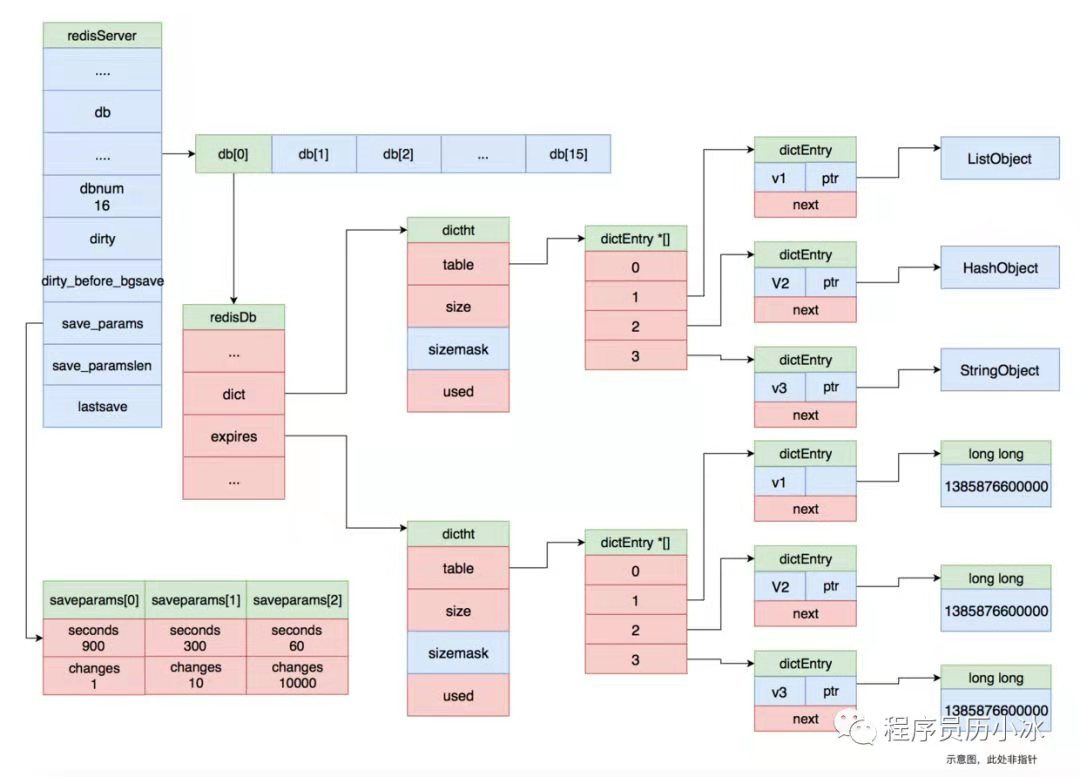
如上图所示,redisServer结构体的 save_params指向拥有三个值的数组,该数组的值与 redis.conf 文件中 save 配置项一一对应。分别是 save9001、 save30010 和 save6010000。dirty 记录着有多少键值发生变化, lastsave记录着上次 RDB 持久化的时间。
而 serverCron 函数就是遍历该数组的值,检查当前 Redis 状态是否符合触发 RDB 持久化的条件,比如说距离上次 RDB 持久化过去了 900 秒并且有至少一条数据发生变更。如果符合触发 RDB 持久化的条件, serverCron会调用 rdbSaveBackground函数,也就是 bgsave 指令会触发的函数。
1 int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
2 ···
3 /* Check if a background saving or AOF rewrite in progress terminated. */
4 /* 判断后台是否正在进行 rdb 或者 aof 操作 */
5 if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
6 ldbPendingChildren())
7 {
8 int statloc;
9 pid_t pid;
10
11 if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
12 int exitcode = WEXITSTATUS(statloc);
13 int bysignal = 0;
14
15 if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
16
17 if (pid == -1) {
18 serverLog(LL_WARNING,"wait3() returned an error: %s. "
19 "rdb_child_pid = %d, aof_child_pid = %d",
20 strerror(errno),
21 (int) server.rdb_child_pid,
22 (int) server.aof_child_pid);
23 } else if (pid == server.rdb_child_pid) {
24 backgroundSaveDoneHandler(exitcode,bysignal);
25 if (!bysignal && exitcode == 0) receiveChildInfo();
26 } else if (pid == server.aof_child_pid) {
27 backgroundRewriteDoneHandler(exitcode,bysignal);
28 if (!bysignal && exitcode == 0) receiveChildInfo();
29 } else {
30 if (!ldbRemoveChild(pid)) {
31 serverLog(LL_WARNING,
32 "Warning, detected child with unmatched pid: %ld",
33 (long)pid);
34 }
35 }
36 updateDictResizePolicy();
37 closeChildInfoPipe();
38 }
39 } else {
40 // 到这儿就能确定 当前木有进行 rdb 或者 aof 操作
41 // 遍历每一个 rdb 保存条件
42 /* If there is not a background saving/rewrite in progress check if
43 * we have to save/rewrite now. */
44 for (j = 0; j < server.saveparamslen; j++) {
45 struct saveparam *sp = server.saveparams+j;
46
47 /**
48 * Save if we reached the given amount of changes,
49 * the given amount of seconds, and if the latest bgsave was
50 * successful or if, in case of an error, at least
51 * CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed.
52 * 如果数据保存记录 大于规定的修改次数 且距离 上一次保存的时间大于规定时间或者上次BGSAVE命令执行成功,
53 * 才执行 BGSAVE 操作
54 */
55 if (server.dirty >= sp->changes &&
56 server.unixtime-server.lastsave > sp->seconds &&
57 (server.unixtime-server.lastbgsave_try >
58 CONFIG_BGSAVE_RETRY_DELAY ||
59 server.lastbgsave_status == C_OK))
60 {
61 //记录日志
62 serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
63 sp->changes, (int)sp->seconds);
64 rdbSaveInfo rsi, *rsiptr;
65 rsiptr = rdbPopulateSaveInfo(&rsi);
66 // 异步保存操作
67 rdbSaveBackground(server.rdb_filename,rsiptr);
68 break;
69 }
70 }
71 ···
72 server.cronloops++;
73 return 1000/server.hz;
74 }
五、子进程后台执行 RDB 持久化
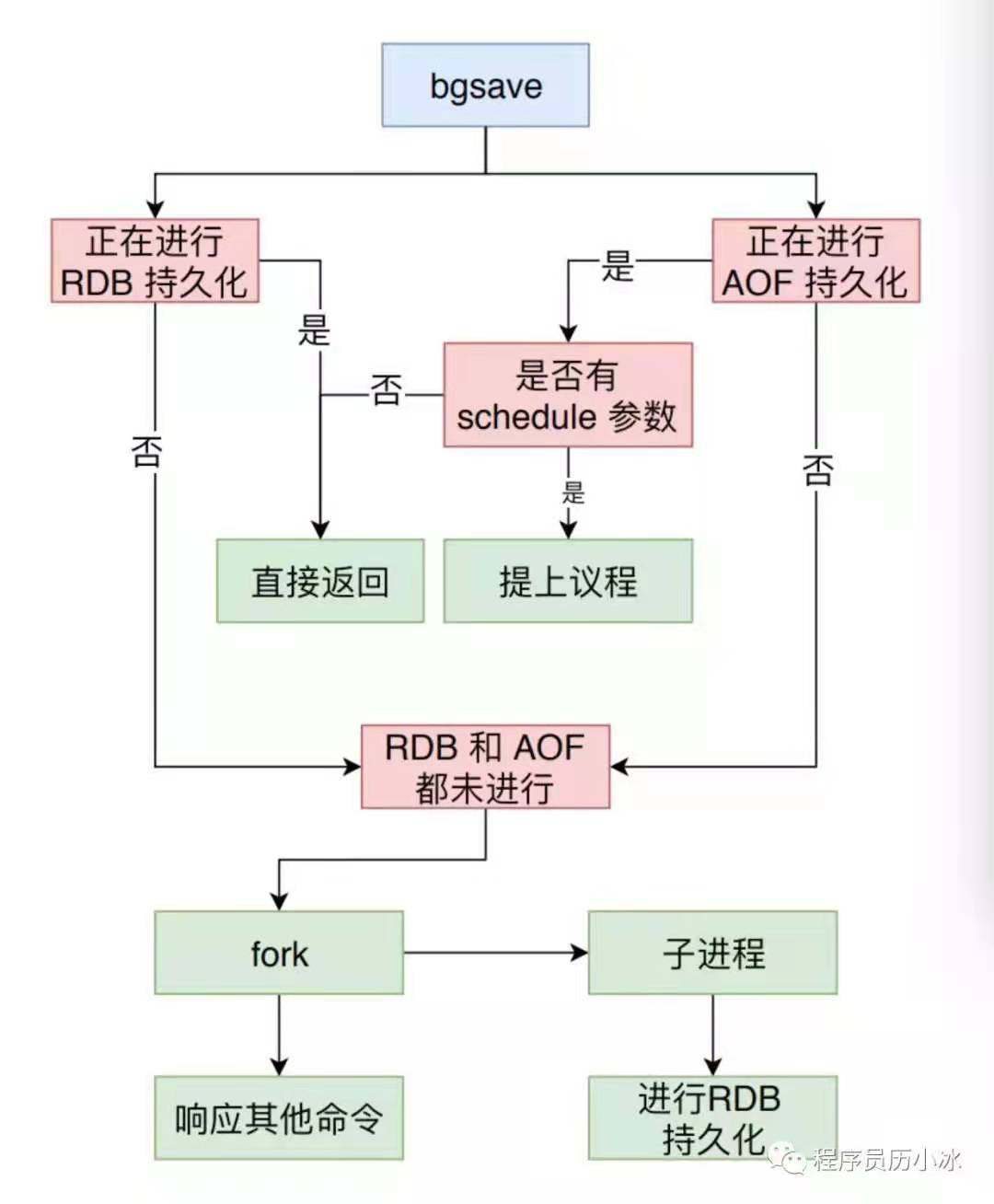
执行 bgsave 指令时,Redis 会先触发bgsaveCommand进行当前状态检查,然后才会调用rdbSaveBackground,其中的逻辑如下图所示。
5.1 rdbSaveBackground函数分析
rdbSaveBackground 函数中最主要的工作就是调用 fork 命令生成子流程,然后在子流程中执行 rdbSave函数,也就是 save 指令最终会触发的函数。
1 int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
2 pid_t childpid;
3 long long start;
4
5
6 // 检查后台是否正在执行 aof 或者 rdb 操作
7 if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
8
9 // 拿出 数据保存记录,保存为 上次记录
10 server.dirty_before_bgsave = server.dirty;
11 // bgsave 时间
12 server.lastbgsave_try = time(NULL);
13 openChildInfoPipe();
14
15 start = ustime();
16 // fork 子进程
17 if ((childpid = fork()) == 0) {
18 int retval;
19
20 /* Child */
21 /* 关闭子进程继承的 socket 监听 */
22 closeListeningSockets(0);
23 // 子进程 title 修改
24 redisSetProcTitle("redis-rdb-bgsave");
25 // 执行rdb 写入操作
26 retval = rdbSave(filename,rsi);
27 // 执行完毕以后
28 if (retval == C_OK) {
29 size_t private_dirty = zmalloc_get_private_dirty(-1);
30
31 if (private_dirty) {
32 serverLog(LL_NOTICE,
33 "RDB: %zu MB of memory used by copy-on-write",
34 private_dirty/(1024*1024));
35 }
36
37 server.child_info_data.cow_size = private_dirty;
38 sendChildInfo(CHILD_INFO_TYPE_RDB);
39 }
40 // 退出子进程
41 exitFromChild((retval == C_OK) ? 0 : 1);
42 } else {
43 /* Parent */
44 /* 父进程,进行fork时间的统计和信息记录,比如说rdb_save_time_start、rdb_child_pid、和rdb_child_type */
45 server.stat_fork_time = ustime()-start;
46 server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
47 latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
48 if (childpid == -1) {
49 closeChildInfoPipe();
50 server.lastbgsave_status = C_ERR;
51 serverLog(LL_WARNING,"Can't save in background: fork: %s",
52 strerror(errno));
53 return C_ERR;
54 }
55 serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);
56 // rdb 保存开始时间 bgsave 子进程
57 server.rdb_save_time_start = time(NULL);
58 server.rdb_child_pid = childpid;
59 server.rdb_child_type = RDB_CHILD_TYPE_DISK;
60 updateDictResizePolicy();
61 return C_OK;
62 }
63 return C_OK; /* unreached */
64 }
5.2 为什么 Redis 使用子进程而不是线程来进行后台 RDB 持久化呢?
主要是出于Redis性能的考虑,我们知道Redis对客户端响应请求的工作模型是单进程和单线程的,如果在主进程内启动一个线程,这样会造成对数据的竞争条件。所以为了避免使用锁降低性能,Redis选择启动新的子进程,独立拥有一份父进程的内存拷贝,以此为基础执行RDB持久化。
但是需要注意的是,fork 会消耗一定时间,并且父子进程所占据的内存是相同的,当 Redis 键值较大时,fork 的时间会很长,这段时间内 Redis 是无法响应其他命令的。除此之外,Redis 占据的内存空间会翻倍。
六、生成 RDB 文件,并且持久化到硬盘
6.1 rdbSave函数
6.1.2 流程
Redis 的 rdbSave 函数是真正进行 RDB 持久化的函数,它的大致流程如下:
-
首先打开一个临时文件,
-
调用
rdbSaveRio函数,将当前 Redis 的内存信息写入到这个临时文件中, -
接着调用
fflush、fsync和fclose接口将文件写入磁盘中, -
使用
rename将临时文件改名为正式的 RDB 文件, -
最后记录
dirty和lastsave等状态信息。这些状态信息在serverCron时会使用到。
6.1.2 源码分析
1 /**
2 * Save the DB on disk. Return C_ERR on error, C_OK on success.
3 * 生成 RDB 文件,并且持久化到硬盘
4 */
5 int rdbSave(char *filename, rdbSaveInfo *rsi) {
6 char tmpfile[256];
7 // 当前工作目录
8 char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
9 FILE *fp;
10 rio rdb;
11 int error = 0;
12
13 /* 生成tmpfile文件名 temp-[pid].rdb */
14 snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
15 /* 打开文件 */
16 fp = fopen(tmpfile,"w");
17 if (!fp) {
18 char *cwdp = getcwd(cwd,MAXPATHLEN);
19 serverLog(LL_WARNING,
20 "Failed opening the RDB file %s (in server root dir %s) "
21 "for saving: %s",
22 filename,
23 cwdp ? cwdp : "unknown",
24 strerror(errno));
25 return C_ERR;
26 }
27
28 /* 初始化rio结构 */
29 rioInitWithFile(&rdb,fp);
30
31 if (server.rdb_save_incremental_fsync)
32 rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
33
34 if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) {
35 errno = error;
36 goto werr;
37 }
38
39 /* Make sure data will not remain on the OS's output buffers */
40 if (fflush(fp) == EOF) goto werr;
41 if (fsync(fileno(fp)) == -1) goto werr;
42 if (fclose(fp) == EOF) goto werr;
43
44 /* Use RENAME to make sure the DB file is changed atomically only
45 * if the generate DB file is ok. */
46 /* 重新命名 rdb 文件,把之前临时的名称修改为正式的 rdb 文件名称 */
47 if (rename(tmpfile,filename) == -1) {
48 // 异常处理
49 char *cwdp = getcwd(cwd,MAXPATHLEN);
50 serverLog(LL_WARNING,
51 "Error moving temp DB file %s on the final "
52 "destination %s (in server root dir %s): %s",
53 tmpfile,
54 filename,
55 cwdp ? cwdp : "unknown",
56 strerror(errno));
57 unlink(tmpfile);
58 return C_ERR;
59 }
60
61 // 写入完成,打印日志
62 serverLog(LL_NOTICE,"DB saved on disk");
63 // 清理数据保存记录
64 server.dirty = 0;
65 // 最后一次完成 SAVE 命令的时间
66 server.lastsave = time(NULL);
67 // 最后一次 bgsave 的状态置位 成功
68 server.lastbgsave_status = C_OK;
69 return C_OK;
70
71 werr:
72 serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
73 fclose(fp);
74 unlink(tmpfile);
75 return C_ERR;
76 }
这里要简单说一下 fflush和 fsync的区别。它们俩都是用于刷缓存,但是所属的层次不同。fflush函数用于 FILE* 指针上,将缓存数据从应用层缓存刷新到内核中,而 fsync 函数则更加底层,作用于文件描述符,用于将内核缓存刷新到物理设备上。
七、内存数据到 RDB 文件
7.1 文件格式
rdbSaveRio 会将 Redis 内存中的数据以相对紧凑的格式写入到文件中,其文件格式的示意图如下所示。

7.2 rdbSaveRio函数流程
rdbSaveRio函数的写入大致流程如下:
-
先写入 REDIS 魔法值,然后是 RDB 文件的版本( rdb_version ),额外辅助信息 ( aux )。辅助信息中包含了 Redis 的版本,内存占用和复制库( repl-id )和偏移量( repl-offset )等。
-
然后
rdbSaveRio会遍历当前 Redis 的所有数据库,将数据库的信息依次写入。先写入RDB_OPCODE_SELECTDB识别码和数据库编号,接着写入RDB_OPCODE_RESIZEDB识别码和数据库键值数量和待失效键值数量,最后会遍历所有的键值,依次写入。 -
在写入键值时,当该键值有失效时间时,会先写入
RDB_OPCODE_EXPIRETIME_MS识别码和失效时间,然后写入键值类型的识别码,最后再写入键和值。 -
写完数据库信息后,还会把 Lua 相关的信息写入,最后再写入
RDB_OPCODE_EOF结束符识别码和校验值。
7.3 rdbSaveRio函数源码分析
7.3.1 rdbSaveRio函数
1 /* Produces a dump of the database in RDB format sending it to the specified
2 * Redis I/O channel. On success C_OK is returned, otherwise C_ERR
3 * is returned and part of the output, or all the output, can be
4 * missing because of I/O errors.
5 *
6 * When the function returns C_ERR and if 'error' is not NULL, the
7 * integer pointed by 'error' is set to the value of errno just after the I/O
8 * error. */
9 int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) {
10 dictIterator *di = NULL;
11 dictEntry *de;
12 char magic[10];
13 int j;
14 uint64_t cksum;
15 size_t processed = 0;
16
17 if (server.rdb_checksum)
18 rdb->update_cksum = rioGenericUpdateChecksum;
19 snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
20 /* 1 写入 magic字符'REDIS' 和 RDB 版本 */
21 if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
22 /**
23 * 2 写入辅助信息 REDIS版本,服务器操作系统位数,当前时间,
24 * 复制信息比如repl-stream-db,repl-id和repl-offset等等数据
25 */
26 if (rdbSaveInfoAuxFields(rdb,flags,rsi) == -1) goto werr;
27
28 /* 3 遍历每一个数据库,逐个数据库数据保存 */
29 for (j = 0; j < server.dbnum; j++) {
30 /* 获取数据库指针地址和数据库字典 */
31 redisDb *db = server.db+j;
32 dict *d = db->dict;
33 if (dictSize(d) == 0) continue;
34 di = dictGetSafeIterator(d);
35
36 /* Write the SELECT DB opcode */
37 /* 3.1 写入数据库部分的开始标识 */
38 if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;
39 /* 3.2 写入当前数据库号 */
40 if (rdbSaveLen(rdb,j) == -1) goto werr;
41
42 /* Write the RESIZE DB opcode. We trim the size to UINT32_MAX, which
43 * is currently the largest type we are able to represent in RDB sizes.
44 * However this does not limit the actual size of the DB to load since
45 * these sizes are just hints to resize the hash tables. */
46 uint64_t db_size, expires_size;
47 /* 获取数据库字典大小和过期键字典大小,此处代码逻辑有简化 */
48 db_size = dictSize(db->dict);
49 expires_size = dictSize(db->expires);
50 /* 3.3 写入当前待写入数据的类型,此处为 RDB_OPCODE_RESIZEDB,表示数据库大小 */
51 if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;
52 /* 3.4 写入获取数据库字典大小和过期键字典大小 */
53 if (rdbSaveLen(rdb,db_size) == -1) goto werr;
54 if (rdbSaveLen(rdb,expires_size) == -1) goto werr;
55
56 /* Iterate this DB writing every entry */
57 /* 4 遍历当前数据库的键值对 */
58 while((de = dictNext(di)) != NULL) {
59 sds keystr = dictGetKey(de);
60 robj key, *o = dictGetVal(de);
61 long long expire;
62
63 /* 初始化 key,因为操作的是 key 字符串对象,而不是直接操作 键的字符串内容 */
64 initStaticStringObject(key,keystr);
65 /* 获取键的过期数据 */
66 expire = getExpire(db,&key);
67 /* 4.1 保存键值对数据 */
68 if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;
69
70 /* When this RDB is produced as part of an AOF rewrite, move
71 * accumulated diff from parent to child while rewriting in
72 * order to have a smaller final write. */
73 if (flags & RDB_SAVE_AOF_PREAMBLE &&
74 rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES)
75 {
76 processed = rdb->processed_bytes;
77 aofReadDiffFromParent();
78 }
79 }
80 dictReleaseIterator(di);
81 di = NULL; /* So that we don't release it again on error. */
82 }
83
84 /* If we are storing the replication information on disk, persist
85 * the script cache as well: on successful PSYNC after a restart, we need
86 * to be able to process any EVALSHA inside the replication backlog the
87 * master will send us. */
88 /* 5 保存 Lua 脚本*/
89 if (rsi && dictSize(server.lua_scripts)) {
90 di = dictGetIterator(server.lua_scripts);
91 while((de = dictNext(di)) != NULL) {
92 robj *body = dictGetVal(de);
93 if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1)
94 goto werr;
95 }
96 dictReleaseIterator(di);
97 di = NULL; /* So that we don't release it again on error. */
98 }
99
100 /* EOF opcode */
101 /* 6 写入结束符 */
102 if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
103
104 /* CRC64 checksum. It will be zero if checksum computation is disabled, the
105 * loading code skips the check in this case. */
106 /* 7 写入CRC64校验和 */
107 cksum = rdb->cksum;
108 memrev64ifbe(&cksum);
109 if (rioWrite(rdb,&cksum,8) == 0) goto werr;
110 return C_OK;
111
112 werr:
113 if (error) *error = errno;
114 if (di) dictReleaseIterator(di);
115 return C_ERR;
116 }
7.3.2 rdbSaveKeyValuePair函数
rdbSaveRio在写键值时,会调用 rdbSaveKeyValuePair 函数。该函数会依次写入键值的过期时间,键的类型,键和值。
1 /**
2 * Save a key-value pair, with expire time, type, key, value.
3 * On error -1 is returned.
4 * On success if the key was actually saved 1 is returned, otherwise 0
5 * is returned (the key was already expired).
6 * 该函数会依次写入键值的过期时间,键的类型,键和值。
7 */
8 int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) {
9 int savelru = server.maxmemory_policy & MAXMEMORY_FLAG_LRU;
10 int savelfu = server.maxmemory_policy & MAXMEMORY_FLAG_LFU;
11
12 /* Save the expire time */
13 /* 如果有过期信息 */
14 if (expiretime != -1) {
15 /* 保存过期信息标识 */
16 if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1;
17 /* 保存过期具体数据内容 */
18 if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1;
19 }
20
21 /* Save the LRU info. */
22 if (savelru) {
23 uint64_t idletime = estimateObjectIdleTime(val);
24 idletime /= 1000; /* Using seconds is enough and requires less space.*/
25 if (rdbSaveType(rdb,RDB_OPCODE_IDLE) == -1) return -1;
26 if (rdbSaveLen(rdb,idletime) == -1) return -1;
27 }
28
29 /* Save the LFU info. */
30 if (savelfu) {
31 uint8_t buf[1];
32 buf[0] = LFUDecrAndReturn(val);
33 /* We can encode this in exactly two bytes: the opcode and an 8
34 * bit counter, since the frequency is logarithmic with a 0-255 range.
35 * Note that we do not store the halving time because to reset it
36 * a single time when loading does not affect the frequency much. */
37 if (rdbSaveType(rdb,RDB_OPCODE_FREQ) == -1) return -1;
38 if (rdbWriteRaw(rdb,buf,1) == -1) return -1;
39 }
40
41 /* Save type, key, value */
42 /* 保存键值对 类型的标识 */
43 if (rdbSaveObjectType(rdb,val) == -1) return -1;
44 /* 保存键值对 键的内容 */
45 if (rdbSaveStringObject(rdb,key) == -1) return -1;
46 /* 保存键值对 值的内容 */
47 if (rdbSaveObject(rdb,val) == -1) return -1;
48 return 1;
49 }
7.3.3 键值的类型和格式
根据键的不同类型写入不同格式,各种键值的类型和格式如下所示。
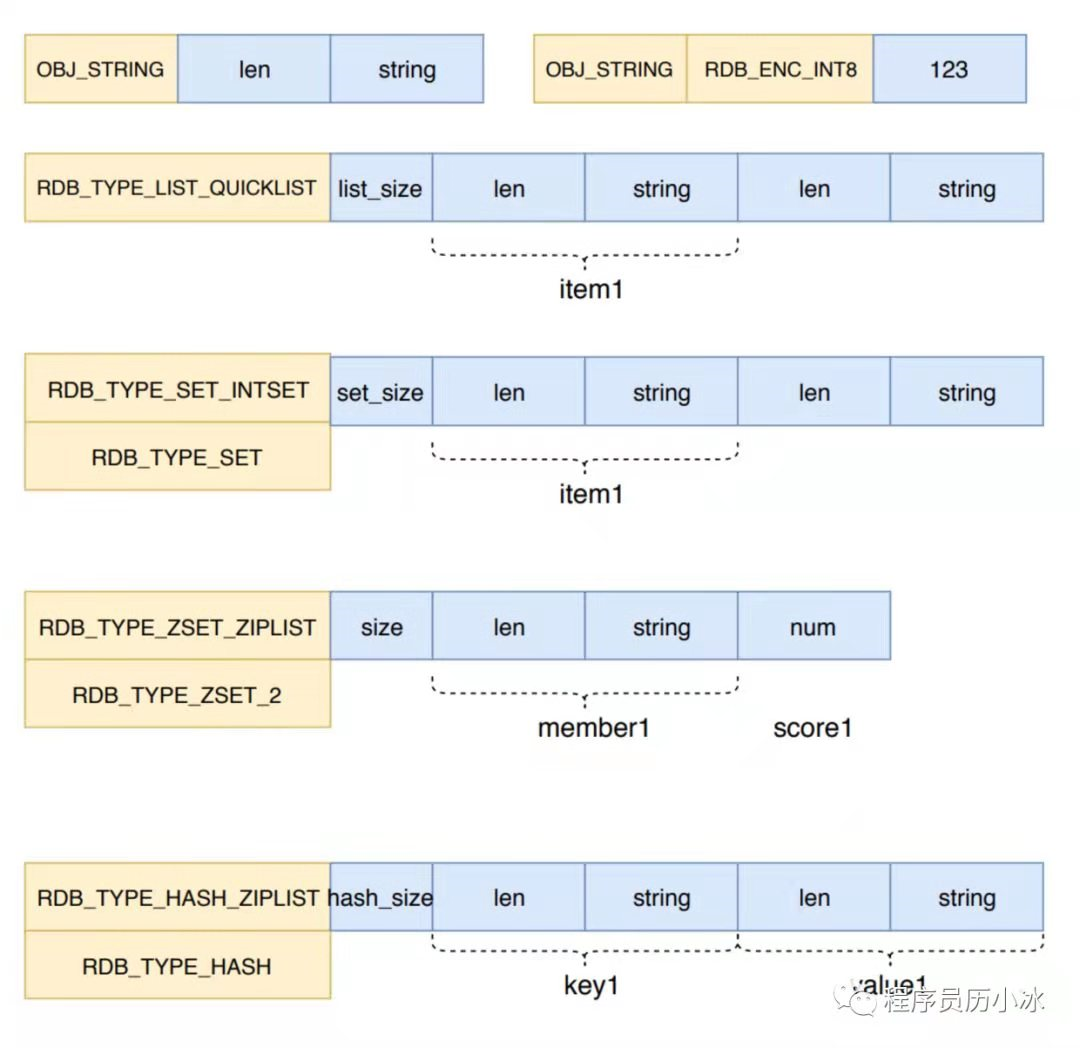
Redis 有庞大的对象和数据结构体系,它使用六种底层数据结构构建了包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象的对象系统。
7.3.4 集合对象的持久化
不同的数据结构进行 RDB 持久化的格式都不同。我们今天只看一下集合对象是如何持久化的。


1 /** 2 * Save a Redis object. 3 * Returns -1 on error, number of bytes written on success. 4 * 保存Redis对象 5 */ 6 ssize_t rdbSaveObject(rio *rdb, robj *o) { 7 ssize_t n = 0, nwritten = 0; 8 9 if (o->type == OBJ_STRING) { 10 /* Save a string value */ 11 if ((n = rdbSaveStringObject(rdb,o)) == -1) return -1; 12 nwritten += n; 13 } else if (o->type == OBJ_LIST) { 14 /* Save a list value */ 15 if (o->encoding == OBJ_ENCODING_QUICKLIST) { 16 quicklist *ql = o->ptr; 17 quicklistNode *node = ql->head; 18 19 if ((n = rdbSaveLen(rdb,ql->len)) == -1) return -1; 20 nwritten += n; 21 22 while(node) { 23 if (quicklistNodeIsCompressed(node)) { 24 void *data; 25 size_t compress_len = quicklistGetLzf(node, &data); 26 if ((n = rdbSaveLzfBlob(rdb,data,compress_len,node->sz)) == -1) return -1; 27 nwritten += n; 28 } else { 29 if ((n = rdbSaveRawString(rdb,node->zl,node->sz)) == -1) return -1; 30 nwritten += n; 31 } 32 node = node->next; 33 } 34 } else { 35 serverPanic("Unknown list encoding"); 36 } 37 } else if (o->type == OBJ_SET) { 38 /* Save a set value */ 39 if (o->encoding == OBJ_ENCODING_HT) { 40 dict *set = o->ptr; 41 // 集合迭代器 42 dictIterator *di = dictGetIterator(set); 43 dictEntry *de; 44 45 // 写入集合长度 46 if ((n = rdbSaveLen(rdb,dictSize(set))) == -1) { 47 dictReleaseIterator(di); 48 return -1; 49 } 50 nwritten += n; 51 52 // 遍历集合元素 53 while((de = dictNext(di)) != NULL) { 54 sds ele = dictGetKey(de); 55 // 以字符串的形式写入,因为是SET 所以只写入 Key 即可 56 if ((n = rdbSaveRawString(rdb,(unsigned char*)ele,sdslen(ele))) 57 == -1) 58 { 59 dictReleaseIterator(di); 60 return -1; 61 } 62 nwritten += n; 63 } 64 dictReleaseIterator(di); 65 } else if (o->encoding == OBJ_ENCODING_INTSET) { 66 size_t l = intsetBlobLen((intset*)o->ptr); 67 68 if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; 69 nwritten += n; 70 } else { 71 serverPanic("Unknown set encoding"); 72 } 73 } else if (o->type == OBJ_ZSET) { 74 /* Save a sorted set value */ 75 if (o->encoding == OBJ_ENCODING_ZIPLIST) { 76 size_t l = ziplistBlobLen((unsigned char*)o->ptr); 77 78 if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; 79 nwritten += n; 80 } else if (o->encoding == OBJ_ENCODING_SKIPLIST) { 81 zset *zs = o->ptr; 82 zskiplist *zsl = zs->zsl; 83 84 if ((n = rdbSaveLen(rdb,zsl->length)) == -1) return -1; 85 nwritten += n; 86 87 /* We save the skiplist elements from the greatest to the smallest 88 * (that's trivial since the elements are already ordered in the 89 * skiplist): this improves the load process, since the next loaded 90 * element will always be the smaller, so adding to the skiplist 91 * will always immediately stop at the head, making the insertion 92 * O(1) instead of O(log(N)). */ 93 zskiplistNode *zn = zsl->tail; 94 while (zn != NULL) { 95 if ((n = rdbSaveRawString(rdb, 96 (unsigned char*)zn->ele,sdslen(zn->ele))) == -1) 97 { 98 return -1; 99 } 100 nwritten += n; 101 if ((n = rdbSaveBinaryDoubleValue(rdb,zn->score)) == -1) 102 return -1; 103 nwritten += n; 104 zn = zn->backward; 105 } 106 } else { 107 serverPanic("Unknown sorted set encoding"); 108 } 109 } else if (o->type == OBJ_HASH) { 110 /* Save a hash value */ 111 if (o->encoding == OBJ_ENCODING_ZIPLIST) { 112 size_t l = ziplistBlobLen((unsigned char*)o->ptr); 113 114 if ((n = rdbSaveRawString(rdb,o->ptr,l)) == -1) return -1; 115 nwritten += n; 116 117 } else if (o->encoding == OBJ_ENCODING_HT) { 118 dictIterator *di = dictGetIterator(o->ptr); 119 dictEntry *de; 120 121 if ((n = rdbSaveLen(rdb,dictSize((dict*)o->ptr))) == -1) { 122 dictReleaseIterator(di); 123 return -1; 124 } 125 nwritten += n; 126 127 while((de = dictNext(di)) != NULL) { 128 sds field = dictGetKey(de); 129 sds value = dictGetVal(de); 130 131 if ((n = rdbSaveRawString(rdb,(unsigned char*)field, 132 sdslen(field))) == -1) 133 { 134 dictReleaseIterator(di); 135 return -1; 136 } 137 nwritten += n; 138 if ((n = rdbSaveRawString(rdb,(unsigned char*)value, 139 sdslen(value))) == -1) 140 { 141 dictReleaseIterator(di); 142 return -1; 143 } 144 nwritten += n; 145 } 146 dictReleaseIterator(di); 147 } else { 148 serverPanic("Unknown hash encoding"); 149 } 150 } else if (o->type == OBJ_STREAM) { 151 /* Store how many listpacks we have inside the radix tree. */ 152 stream *s = o->ptr; 153 rax *rax = s->rax; 154 if ((n = rdbSaveLen(rdb,raxSize(rax))) == -1) return -1; 155 nwritten += n; 156 157 /* Serialize all the listpacks inside the radix tree as they are, 158 * when loading back, we'll use the first entry of each listpack 159 * to insert it back into the radix tree. */ 160 raxIterator ri; 161 raxStart(&ri,rax); 162 raxSeek(&ri,"^",NULL,0); 163 while (raxNext(&ri)) { 164 unsigned char *lp = ri.data; 165 size_t lp_bytes = lpBytes(lp); 166 if ((n = rdbSaveRawString(rdb,ri.key,ri.key_len)) == -1) return -1; 167 nwritten += n; 168 if ((n = rdbSaveRawString(rdb,lp,lp_bytes)) == -1) return -1; 169 nwritten += n; 170 } 171 raxStop(&ri); 172 173 /* Save the number of elements inside the stream. We cannot obtain 174 * this easily later, since our macro nodes should be checked for 175 * number of items: not a great CPU / space tradeoff. */ 176 if ((n = rdbSaveLen(rdb,s->length)) == -1) return -1; 177 nwritten += n; 178 /* Save the last entry ID. */ 179 if ((n = rdbSaveLen(rdb,s->last_id.ms)) == -1) return -1; 180 nwritten += n; 181 if ((n = rdbSaveLen(rdb,s->last_id.seq)) == -1) return -1; 182 nwritten += n; 183 184 /* The consumer groups and their clients are part of the stream 185 * type, so serialize every consumer group. */ 186 187 /* Save the number of groups. */ 188 size_t num_cgroups = s->cgroups ? raxSize(s->cgroups) : 0; 189 if ((n = rdbSaveLen(rdb,num_cgroups)) == -1) return -1; 190 nwritten += n; 191 192 if (num_cgroups) { 193 /* Serialize each consumer group. */ 194 raxStart(&ri,s->cgroups); 195 raxSeek(&ri,"^",NULL,0); 196 while(raxNext(&ri)) { 197 streamCG *cg = ri.data; 198 199 /* Save the group name. */ 200 if ((n = rdbSaveRawString(rdb,ri.key,ri.key_len)) == -1) 201 return -1; 202 nwritten += n; 203 204 /* Last ID. */ 205 if ((n = rdbSaveLen(rdb,cg->last_id.ms)) == -1) return -1; 206 nwritten += n; 207 if ((n = rdbSaveLen(rdb,cg->last_id.seq)) == -1) return -1; 208 nwritten += n; 209 210 /* Save the global PEL. */ 211 if ((n = rdbSaveStreamPEL(rdb,cg->pel,1)) == -1) return -1; 212 nwritten += n; 213 214 /* Save the consumers of this group. */ 215 if ((n = rdbSaveStreamConsumers(rdb,cg)) == -1) return -1; 216 nwritten += n; 217 } 218 raxStop(&ri); 219 } 220 } else if (o->type == OBJ_MODULE) { 221 /* Save a module-specific value. */ 222 RedisModuleIO io; 223 moduleValue *mv = o->ptr; 224 moduleType *mt = mv->type; 225 moduleInitIOContext(io,mt,rdb); 226 227 /* Write the "module" identifier as prefix, so that we'll be able 228 * to call the right module during loading. */ 229 int retval = rdbSaveLen(rdb,mt->id); 230 if (retval == -1) return -1; 231 io.bytes += retval; 232 233 /* Then write the module-specific representation + EOF marker. */ 234 mt->rdb_save(&io,mv->value); 235 retval = rdbSaveLen(rdb,RDB_MODULE_OPCODE_EOF); 236 if (retval == -1) return -1; 237 io.bytes += retval; 238 239 if (io.ctx) { 240 moduleFreeContext(io.ctx); 241 zfree(io.ctx); 242 } 243 return io.error ? -1 : (ssize_t)io.bytes; 244 } else { 245 serverPanic("Unknown object type"); 246 } 247 return nwritten; 248 }
转载文章
https://mp.weixin.qq.com/s/NpUV-7bvXTD3iu0_2aRssQ
本文来自博客园,作者:Mr-xxx,转载请注明原文链接:https://www.cnblogs.com/MrLiuZF/p/15005675.html

