sql server I/O硬盘交互
一. 概述
sql server作为关系型数据库,需要进行数据存储, 那在运行中就会不断的与硬盘进行读写交互。如果读写不能正确快速的完成,就会出现性能问题以及数据库损坏问题。下面讲讲引起I/O的产生,以及分析优化。
二.sql server 主要磁盘读写的行为
2.1 从数据文件(.mdf)里, 读入新数据页到内存。前页讲述内存时我们知道,如果想要的数据不在内存中时,就会从硬盘的数据文件里以页面为最小单位,读取到内存中,还包括预读的数据。 当内存中存在,就不会去磁盘读取数据。足够的内存可以最小化磁盘I/O,因为磁盘的速度远慢于内存。
2.2 预写日志系统(WAL),向日志文件(.ldf)写入增删改的日志记录。 用来维护数据事务的ACID。
2.3 Checkpoint 检查点发生时,将脏页数据写入到数据文件 ,在sp_configure的recovery interval 控制着sql server多长时间进行一次Checkpoint, 如果经常做Checkpoint,那每次产生的硬盘写就不会太多,对硬盘冲击不会太大。如果隔长时间一次Checkpoint,不做Checkpoint时性能可能会比较快,但累积了大量的修改,可能要产生大量的写,这时性能会受影响。在绝大多数据情况下,默认设置是比较好的,没必要去修改。
2.4 内存不足时,Lazy Write发生,会将缓冲区中修改过的数据页面同步到硬盘的数据文件中。由于内存的空间不足触发了Lazy Write, 主动将内存中很久没有使用过的数据页和执行计划清空。Lazy Write一般不被经常调用。
2.5 CheckDB, 索引维护,全文索引,统计信息,备份数据,高可用同步日志等。
三. 磁盘读写的相关分析
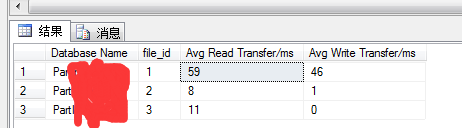
3.1 sys.dm_io_virtual_file_stats 获取数据文件和日志文件的I/O 统计信息。该函数从sql server 2008开始,替换动态管理视图fn_virtualfilestats函数。 哪些文件经常要做读num_of_reads,哪些经常要做写num_of_writes,哪些读写经常要等待io_stall_*。为了获取有意义的数据,需要在短时间内对这些数据进行快照,然后将它们同基线数据相比较。
SELECT DB_NAME(database_id) AS 'Database Name', file_id, io_stall_read_ms / num_of_reads AS 'Avg Read Transfer/ms', io_stall_write_ms / num_of_writes AS 'Avg Write Transfer/ms' FROM sys.dm_io_virtual_file_stats(null, null) WHERE num_of_reads > 0 AND num_of_writes > 0
io_stall_read_ms:用户等待文件,发出读取所用的总时间(毫秒)。
io_stall_write: 用户等待在该文件中完成写入所用的总时间毫秒。
3.2 windows 性能计数器: Avg. Disk Sec/Read 这个计数器是指每秒从磁盘读取数据的平均值
< 10 ms - 非常好
10 ~ 20 ms 之间- 还可以
20 ~50 ms 之间- 慢,需要关注
> 50 ms –严重的 I/O 瓶颈
3.4 I/O 物理内存读取次数最多的前50条
SELECT TOP 50 qs.total_physical_reads,qs.execution_count, qs.total_physical_reads/qs.execution_count AS [avg I/O], qs. creation_time, qs.max_elapsed_time, qs.min_elapsed_time, SUBSTRING(qt.text,qs.statement_start_offset/2, (CASE WHEN qs.statement_end_offset=-1 THEN LEN(CONVERT(NVARCHAR(max),qt.text))*2 ELSE qs.statement_end_offset END -qs.statement_start_offset)/2) AS query_text, qt.dbid,dbname=DB_NAME(qt.dbid), qt.objectid, qs.sql_handle, qs.plan_handle from sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt ORDER BY qs.total_physical_reads DESC
3.5 使用sp_spaceused查看表的磁盘空间
exec sp_spaceused 'table_xx'
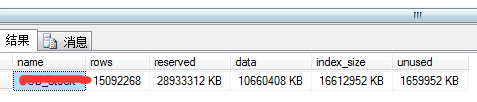
reserved:保留的空间总量
data:数据使用的空间总量
index_size:索引使用空间
Unused: 未用的空间量
3.6 监测I/0运行状态 STATISTICS IO ON;
四 磁盘读写瓶颈的症状
4.1 errorlog里报告错误 833
4.2 sys.dm_os_wait_stats 视图里有大量等待状态PAGEIOLATCH_* 或 WriteLog。当数据在缓冲区里没有找到,连接的等待状态就是PAGEIOLACTH_EX(写) PAGEIOLATCH_SH(读),然后发起异步操作,将页面读入缓冲区中。像 waiting_tasks_count和wait_time_ms比较高的时候,经常要等待I/O,除在反映在数据文件上以外,还有writelog的日志文件上。想要获得有意义数据,需要做基线数据,查看感兴趣的时间间隔。
select wait_type, waiting_tasks_count, wait_time_ms , max_wait_time_ms, signal_wait_time_ms from sys.dm_os_wait_stats where wait_type like 'PAGEIOLATCH%' order by wait_type
wait_type:等待类型
waiting_tasks_count:该等待类型的等待数
wait_time_ms:该等待类型的总等待时间(包括一个进程悬挂状态(Suspend)和可运行状态(Runnable)花费的总时间)
max_wait_time_ms:该等待类型的最长等待时间
signal_wait_time_ms:正在等待的线程从收到信号通知到其开始运行之间的时差(一个进程可运行状态Runnable花费的总时间)
i/o等待时间==wait_time_ms - signal_wait_time_ms
五 优化磁盘I/O
5.1 数据文件里页面碎片整理。 当表发生增删改操作时索引都会产生碎片(索引叶级的页拆分),碎片是指索引上的页不再具有物理连续性时,就会产生碎片。比如你查询10条数据,碎片少时,可能只扫描2个页,但碎片多时可能要扫描更多页(后面讲索引时在细说)。
5.2 表格上的索引。比如:建议每个表都包含聚集索引,这是因为数据存储分为堆和B-Tree, 按B-Tree空间占用率更高。 充分使用索引减少对I/0的需求。
5.3 数据文件,日志文件,TempDB文件建议存放不同物理磁盘,日志文件放写入速度比较快的磁盘上,例如 RAID 10的分区
5.4 文件空间管理,设置数据库增长时要按固定大小增长,而不能按比例,这样避免一次增长太多或太少所带来的不必要麻烦。建议对比较小的数据库设置一次增长50MB到100MB。下图显示如果按5%来增长近10G, 如果有一个应用程序在尝试插入一行,但是没有空间可用。那么数据库可能会开始增长一个近10G, 文件的增长可能会耗用太长的时间,以至于客户端程序插入查询失败。

5.5 避免自动收缩文件,如果设置了此功能,sql server会每隔半小时检查文件的使用,如果空闲空间>25%,会自动运行dbcc shrinkfile 动作。自动收缩线程的会话ID SPID总是6(以后可能有变) 如下显示自动收缩为False。

5.6 如果数据库的恢复模式是:完整。 就需要定期做日志备份,避免日志文件无限的增长,用于磁盘空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号