Elasticsearch 配置与测试分析器 (2)
一. 配置文本分析器(Configure text analysis)
默认情况下,Elasticsearch 使用standard分析器来进行文本分析,如果使用该分析器,则不用额外的配置。如果不满足,可以使用其它内置分析器,也可以创建自定义的分析器更好的控制,通常在生产实战中都是自定义分析器,方便更好扩展。
1.1.下面使用内置的whitespace分析器来看下效果(后续会介绍内置的各种分析器)
POST _analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
分析结果如下所示:
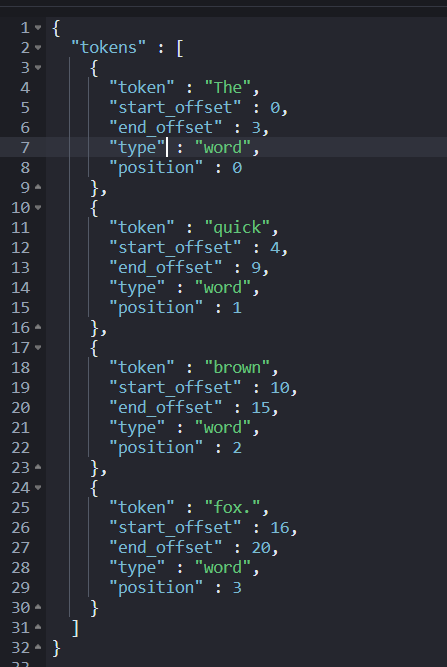
使用数组表示的分词结果:[ The, quick, brown, fox. ]
1.2 下面使用各项组合分析器
POST _analyze
{
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ], #lowercase:转小写, asciifolding:将包含非ASCII字符的文本转换为其ASCII等效表示
"text": "Is this déja vu?"
}
分析结果:[ is, this, deja,vu ]
1.3 下面自定义一个分析器,映射到索引中
PUT my-index-000001
{
"settings": {
"analysis": { #分析根节点
"analyzer": { #分析器
"std_folded": { #自定义一个分析器, 可以定义多个分析器
"type": "custom",
"tokenizer": "standard", #分词器
"filter": [ #token 过滤,一个token是指一个单词term
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std_folded" #指定自定义的分析器
}
}
}
}
二种方式测试分析器文本(常用第二种)
GET my-index-000001/_analyze
{
"analyzer": "std_folded", #指定分析器名
"text": "Is this déjà vu?"
}
GET my-index-000001/_analyze #分析my_text字段,默认分析器std_folded
{
"field": "my_text",
"text": "Is this déjà vu?"
}
分析结果与上面1.2结果一样
参考官方资料:配置文本分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号