Elasticsearch 认识分词(1)
一.概述
分词是构建倒排索引的重要一环。根据语言不同可以分为英文分词、中文分词等;根据分词实现的不同又分为标准分词器、空格分词器、停用词分词器等。在传统的分词器不能解决特定业务场景的问题时,往往需要自定义分词器。
1.1认识分词
对于分词操作来说,英语单词分词相对简单,因为单词之间都会以空格或者标点隔开,举例如下
A man can be destroyed,but not defeated. a /man/can/be/destroyed /but /not/defeated(正确)
而中文在单词、句子甚至段落之间没有空格, 分词比较复杂
内塔尼亚胡说的确实在理 内塔尼亚胡 /说 /的确 /实在 /理(错误) 内塔尼亚 /胡说 /的 /确实 /在理(错误) 内塔尼亚胡 /说的 /确实 /在理(正确)
1.2 什么时候需要分词
用户需要进行模糊搜索的场景,通过“搜索词”搜索出关联的文档数据,特别是在大数据量,要求搜索快速响应等情况下使用分词, 分词后存储为倒排索引结构的倒排文件, 通过倒排索引快速检索出相关文档。
1.3 分词发生的阶段
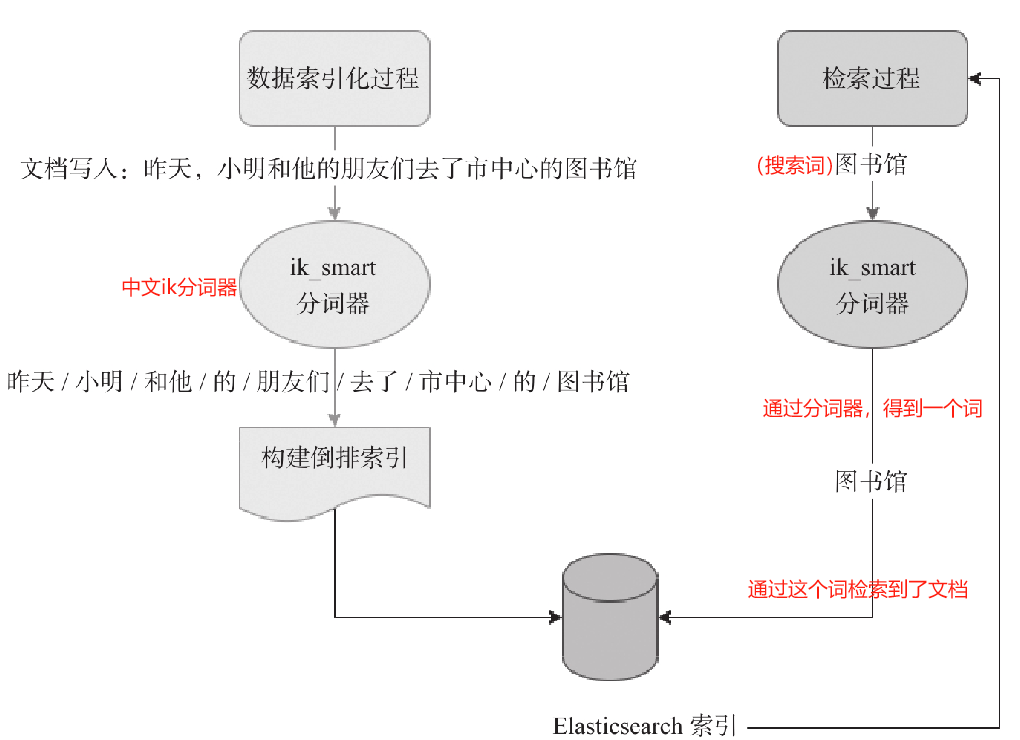
前提条件:只有文档中的text类型字段才会进行分词,es默认分词器是:standard分词器。
1)在写入数据时(数据索引化过程),使用分词器进行分词,将分词存储为倒排索引。
2)在搜索数据时(检索过程),通过“搜索词”进行分词找到相应文档。
1.4 分析器(analyzer)组成
文档在写入并转换为倒排索引前,通过es内置分析器(analyzer)或自定义分析器进行分析实现,analyzer由三个部分组成:
1)charactcr filter 字符过滤器。
2) tokenizer 分词器,将文本切分为单个单词 term。
3)token filter 令牌过滤器,分词后再过滤。
1个analyzer包括: 0或多个charactcr filter、1个tokenizer 、 0或多个token filter。
参考资料:一本书讲透Elasticsearch

 浙公网安备 33010602011771号
浙公网安备 33010602011771号