scrapyrt 部署到docker
一.背景
scrapyrt是实时抓取api框架,我们生产环境一直使用默认的python 3.6.8环境,来部署的scrapyrt。但由于自动化抓取playwright至少需要python 3.7以上,又因为阿里云centos 8默认的python 3.6.8升级后带来很多不便,现在需要将scrapyrt部署到docker中,在docker中scrapyrt基于python 3.8。
1.1 scrapyrt官方docker
scrapyrt官方也提供了docker部署,那是5年前的镜像,默认是基于python 2.7的,镜像地址: https://hub.docker.com/r/scrapinghub/scrapyrt/tags
官方介绍的安装命令如下:
docker pull scrapinghub/scrapyrt docker run -p 9080:9080 -tid -v /home/user/quotesbot:/scrapyrt/project scrapinghub/scrapyrt
1.2 自己构建镜像
去github上把scrapyrt源码最新的下载,地址:https://github.com/scrapinghub/scrapyrt
修改dockerfile文件,如下所示:
# To build: # > docker build -t scrapyrt . # # to start as daemon with port 9080 of api exposed as 9080 on host # and host's directory ${PROJECT_DIR} mounted as /scrapyrt/project # # > docker run -p 9080:9080 -tid -v ${PROJECT_DIR}:/scrapyrt/project scrapyrt #FROM python:3.10-slim-buster FROM python:3.8.16-slim-bullseye RUN mkdir -p /scrapyrt/src /scrapyrt/project RUN mkdir -p /var/log/scrapyrt RUN pip install --upgrade pip RUN sed -i s@http://deb.debian.org@http://mirrors.aliyun.com@g /etc/apt/sources.list RUN apt-get clean RUN apt-get update && apt-get install -y nodejs RUN pip install playwright==1.28.0 -i https://mirrors.aliyun.com/pypi/simple RUN playwright install --with-deps chromium ADD . /scrapyrt/src RUN pip install /scrapyrt/src -i https://mirrors.aliyun.com/pypi/simple COPY requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt -i https://mirrors.aliyun.com/pypi/simple WORKDIR /scrapyrt/project ENTRYPOINT ["scrapyrt", "-i", "0.0.0.0"] EXPOSE 9080
在requirements.txt中添加必需的包,我业务中需要的是如下:
Scrapy==2.5.1 elasticsearch==7.17.4 elasticsearch-dsl==7.4.0 PyExecJS==1.5.1 PyMySQL==1.0.2 requests==2.27.1 redis==4.3.4 gerapy-selenium==0.0.3 prometheus-client==0.14.1 pyOpenSSL==22.0.0
接着将源码在本机构建镜像或者上传到有docker环境的centos中构建镜像,如下代码,构建镜像名称为myscrapyrt
[root@dev-data-node001 scrapyrt-master]# pwd /root/scrapyrt-master [root@dev-data-node001 scrapyrt-master]# ls artwork Dockerfile docs LICENSE README.rst requirements-dev.txt requirements.txt scrapyrt setup.cfg setup.py tests [root@dev-data-node001 scrapyrt-master]# docker build -t hushaoren/myscrapyrt:1.4 .
接着查看所有镜像如下所示(会发现通过tag生成的镜像与原镜像ID是一样的) :
[root@dev-data-node001 scrapyrt-master]# docker images --all REPOSITORY TAG IMAGE ID CREATED SIZE hushaoren/myscrapyrt 1.4 0c23df3b64d8 2 minutes ago 1.23GB python 3.8.16-slim-bullseye 25238eab133c 2 weeks ago 124MB
接着使用登录到docker hub 上传镜像hushaoren/myscrapyrt, 如下所示:
[root@dev-data-node001 scrapyrt-master]# docker login Authenticating with existing credentials... WARNING! Your password will be stored unencrypted in /root/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded [root@dev-data-node001 scrapyrt-master]# docker push hushaoren/myscrapyrt
二. 部署scrapyrt项目
将realtime-python-crawler项目上传到开发环境centos的目录中 如下所示:
[root@dev-data-node001 realtime-python-crawler]# pwd /root/scrapyrt_project/realtime-python-crawler [root@dev-data-node001 realtime-python-crawler]# ls config.json logs main_redis.py realtime_python_crawler scrapy.cfg main.py __pycache__ requirements.txt scrapyrt_settings.py
下面是最重的命令,拉取镜像,创建容器并启动
docker pull hushaoren/myscrapyrt:1.4 docker run -p 9080:9080 -e TZ="Asia/Shanghai" -tid -v /root/scrapyrt_project/realtime-python-crawler:/scrapyrt/project -d hushaoren/myscrapyrt:1.4 -S scrapyrt_settings -i 0.0.0.0
对外端口号是9080
-v是将 宿主目录的realtime-python-crawler项目文件 映射到容器目录scrapyrt/project 下
-d 后台运行
-S是使用scrapyrt_settings.py文件(自己创建的扩展文件覆盖原有default_settings.py文件)
-e Tz="Asia/Shanghai" 修改容器的时间,与宿主保持一致
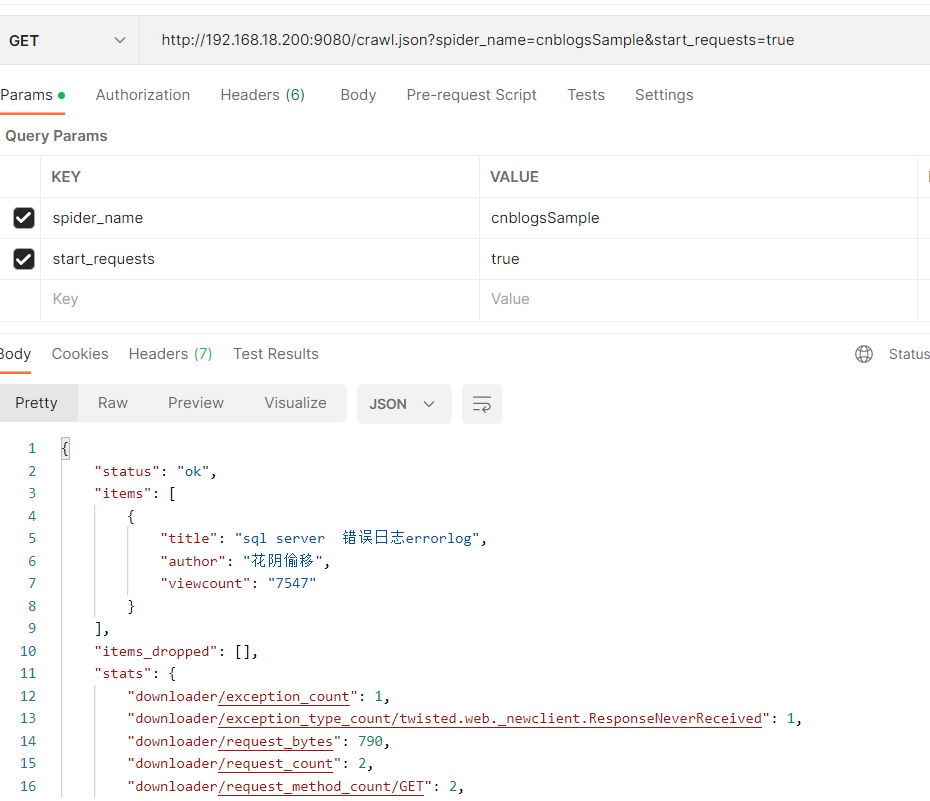
使用Postman 运行效果如下所示:
最后在docker中生成的日志文件也能在宿主目录/root/scrapyrt_project/realtime-python-crawler下同步,这样日志文件也可以通过filebeat来采集了。
迁移到docker后需要注意事项:
1) python程序中动态获取本机外网ip只会获取到127.0.0.1,修改方法把本机外网ip写入配置文件,通过配置文件来读取。
2) realtime-python-crawler项目添加新的pip包时,需要重新构建镜像,再按第二点流程执行(关键代码:RUN pip install -r /tmp/requirements.txt)。
如果觉得重新构建镜像麻烦,也可以在启动容器后,进入容器,手动pip安装需要的包(只要不删除容器,可以停止或启动,安装后包就是一直在该容器中),下面是列出已有的pip包(以及通过pip list 查看pip工具是否需要更新),如下所示
[root@iZwz97yqubb71vyxhuskfxZ realtime-python-crawler]# docker exec -it 1c1d1d7e9b26 /bin/bash root@1c1d1d7e9b26:/scrapyrt/project# pip list Package Version ------------------ --------- asq 1.3 async-generator 1.10 async-timeout 4.0.2 attrs 22.2.0 Automat 22.10.0 certifi 2022.12.7 cffi 1.15.1 charset-normalizer 2.0.12 constantly 15.1.0 cryptography 38.0.4 cssselect 1.2.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号