Scrapy 请求并发数设置
并发数可以在scrapy项目的settings.py文件中设置。
1.CONCURRENT_ITEMS
是指:最大并发项目数,默认100个。
2.CONCURRENT_REQUESTS
是指:下载器将执行的并发(即同时)请求的最大数量,默认16个。
3.CONCURRENT_REQUESTS_PER_DOMAIN
是指:任何单个域执行的并发(即同时)请求的最大数量,默认:8
4.CONCURRENT_REQUESTS_PER_IP
是指:任何单个IP执行的并发求的最大数量,而使用该设置,并发限制将适用于每个 IP,而不是每个域,默认0不启用,
如果非0,CONCURRENT_REQUESTS_PER_DOMAIN和DOWNLOAD_DELAY则忽略
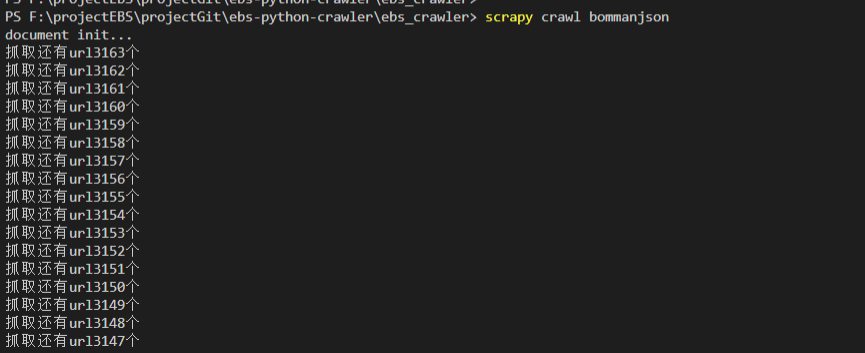
项目中默认配置的请求并发数是16个,下面代码和截图验证了此功能。
def start_requests(self): self.load_urlList() #self.urls是一个url列表 while len(self.urls)>0: url= self.urls.pop(0) print(url) print(f"抓取还有url{len(self.urls)}个") yield scrapy.Request(url=url, callback=self.parse,headers=self.headers)
scrapy crawl spidername 命令启动时,request请求了16个url,下图是一次并发多个抓取
settings.py全局配置如下所示:
# Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16
参考文档:https://docs.scrapy.org/en/latest/topics/settings.html#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号