RabbitMQ 学习系列9 进阶(延迟队列、优先级队列、持久化、生产者确认) 3
4.4 延迟队列
延迟队列存储的对象是对应的延迟消息, 所谓“延迟消息”是指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到消息进行消费。
延迟队列的使用场景有很多,比如:
(1) 在订单系统中,一个用户下单通常有30分钟的时间进行支付,如果30分钟之内没有支付成功,那么这个订单将进行异常处理,这时就可以使用延迟队列来处理这些订单了(理解:下订单30分钟后,消费者服务拿到队列消息进行异常处理(进入死信队列))。
(2) 用户希望通过手机远程遥控家里的智能设备在指定的时间进行工作,这时候就可以将用户指令发送到延迟队列,当指令设定的时间到了再将指令送到智能设备。
在AMQP协议中,或者rabbitmq本身没有直接支持延迟队列的功能,但是可以通过前面所介绍的dlx和ttl模拟出延迟队列的功能。
在上一章4.4图,这里再次贴出来,如下所示:
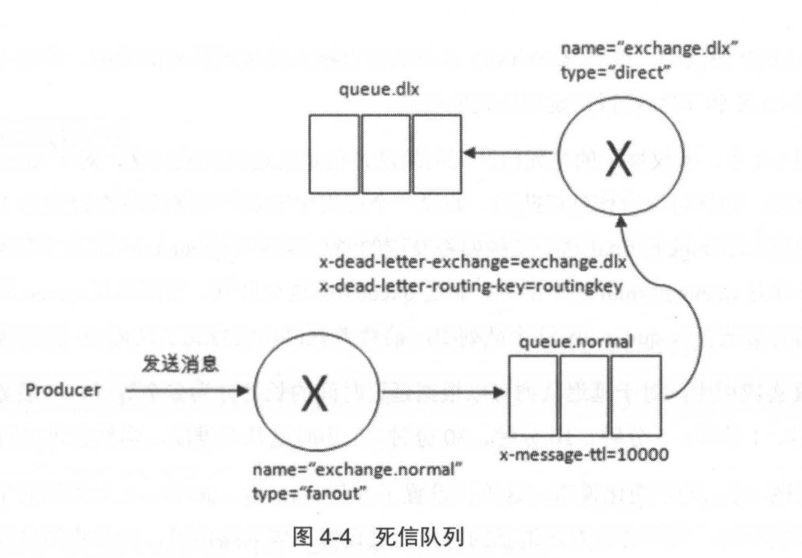
这个图不仅展示的是死信队列的用法,也是延迟队列的用法,对于queue.dlx这个死信队列来说,同样可以看作延迟队列。假设一个应用中需要将每条消息都设置为10秒的延迟,生产者通过exchange.norrmal这个交换器将发送的消息存储在queue.noraml这个队列中,消息者订阅的并非queue.noraml这个队列,而是queue.dlx这个队列,当消息从queue.noraml这个队列中过期之后被存入queue.dlx这个队列中,消费者就恰巧消费到了延迟10秒的这条消息。
在真实应用中,对于延迟队列可以根据延迟时间的长短分为多个等级,一般分为5秒,10秒,30秒,1分钟,5分钟,10分钟,30分钟,1小时这几个维度,当然也可以再细化一下。
下图4-5,为了简化说明,这里只设置了5秒,10秒,30秒,1分钟这四个等级。根据应用需求的不同,生产者在发送消息的时候通过设置不同的路由键,此时将消息发送到与交换器绑定的不同的队列中。这里队列分别设置了过期时间为5秒,10秒,30秒,1分钟,同时也分别配置了dlx和相应的死信队列。当相应的消息过期时,就会转存到相应的死信队列(即延迟队列)中,这样消费者根据业务自身的情况,分别选择不同延迟等级的延迟队列进行消费。

4.5 优先级队列
是指优先级高的消息具备优先被消费的特权,可以通过设置队列的x-max-priority参数来实现。如下所示:
//定列一个优先级队列 channel.QueueDeclare("queue.priority",true,false,false, new Dictionary<string, object>() { {"x-max-priority",10 } });
通过web管理页面可以看到 "pri" 的标识,如下所示:

上面的代码演示的是如何配置一个队列的最大优先级,为10。在此之后,需要在发送时在消息中设置消息当前的优先级,示例代码如下:
var pro = channel.CreateBasicProperties(); pro.Priority = 5; //发布消息 channel.BasicPublish(exchangeName, routeKey,true, pro, sendBytes);
上面的代码中设置消息的优先级为5,默认最低为0,最高为队列设置的最大优先级。优先级高的消息可以被优先消费,这个也是有前提的:如果在消费者的消费速度大于生产者的速度且broker中没有消息堆积的情况下,对发送的消息设置优先级也就没什么实际意义。
4.6 RPC实现
后续了解
4.7 持久化
rabbitmq的持久化分为三个部分:交换器的持久化、队列的持久化和消息的持久化。
交换器的持久化是通过在声明交换器时将durable参数置为true实现的。对一个长期使用的交换器来说,建议将其置为持久化.
队列的持久化是通过在声明队列时将durable参数置为true实现的。如果不设置持久化,那么rabbitmq服务重启之后,相关队列的元数据会丢失,此时数据也会丢失。队列没了,消息也就没了。
队列的持久化能保证其本身的元数据不会因异常情况而丢失,但并不能保证内部所存储的消息不会丢失,要确保消息不会丢失,需要将其设置为持久化。通过将消息的投递模式(deliverModel)设置为2即可实现消息的持久化。
设置了队列和消息的持久化,当rabbitmq服务重启之后,消息依旧存在,如果单单只设置队列持久化,重启之后消息会丢失;单单只设置消息的持久化,重启之后队列消失,继而消息也会丢失。单单设置消息的持久化而不设置队列的持久化显得毫无意义。
注意要点:
可以将所有的消息都设置为持久化,但是这样会严重影响rabbitmq的性能。写入磁盘的速度比写入内存的速度慢得不只一点点。对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。在选择是否要将消息持久化时,需要在可靠性和吞吐量之间做一个权衡。
将交换器、队列、消息都设置了持久化就能保证百分百不丢失吗?答案是否定的。
1.是从消费者来说,必须在客户端程序处理消息后,才能将auotAck参数设置为false。
2.持久后存入磁盘时,rabbitmq并不会为每条消息进行同步磁盘,如果仅保存在操作系统缓存之中而不是物理磁盘之中,在这短的时间内rabbitmq服务节点发生了down机或重启等异常情况,消息保存还没来得落盘,那么消息会丢失。解决方法(1)引入rabbitmq的镜像队列机制,相当于配置了副本,在生产环境中关键业务一般都会设置镜像队列(2)是发送端做确认机制来保证消息已经正确地发送并存储至rabbitmq中(channel.BasicPublish中设置)在下面4.8讲到。
4.8 生产者确认
当消息的生产者将消息发送出去之后,消息到底有没有正确到达服务器呢?如果不进行配置,默认情况下发送消息的操作是不会返回任何信息给生产者的。如果在消息到达服务器之前已经丢失,持久化操作也解决不了这个问题,因为消息根本没有到达服务器。
rabbitmq针对这个问题,提供了两种解决方式:
1.通过事务机制实现
2.通过发送确认(publisher confirm)机制实现
4.8.1 事务机制
rabbitmq客户端中与事务机制相关的方法有三个:channel.txSelect、channel.txCommit和channel.txRollback。

channel.txSelect用于将当前的信道设置成事务模式,channel.txCommit用于提交事务,channel.txRollback用于事务回滚。在通过channel.txSelect方法开启事务之后,便可以发布消息给rabbitmq了,如果事务提交成功,则消息一定到达了rabbitmq中,如果在事务提交执行之前由于rabbitmq异常崩溃或者其他原因抛出异常,这个时候我们便可以将其捕获,进而通过执行channel.txRollback实现事务回滚。注意这里的rabbitmq中的事务机制与大多数数据库中的事务概念并不相同,需要注意区分。
关键代码如下所示:
//开启事务 channel.TxSelect(); //发布消息 channel.BasicPublish(exchangeName, routeKey,true, null, sendBytes); //提交事务 channel.TxCommit();
步骤: 1客户端发送TxSelect 将信道置为事务模式;
2.Broker 回复TxSelect-OK,确认已将信道置为事务模式;
3.在发送完消息之后,客户端发送Tx.Commit提交事务;
4.Broker 回复TxCommit-OK,确认事务提交。
下面关键代码是回滚所示:
try { //开启事务 channel.TxSelect(); //发布消息 channel.BasicPublish(exchangeName, routeKey, true, null, sendBytes); //提交事务 channel.TxCommit(); } catch (Exception e) { channel.TxRollback(); }
如果要循环发送消息,如下所示:
//开启事务 channel.TxSelect(); for (int i = 0; i < 10; i++) { try { //发布消息 channel.BasicPublish(exchangeName, routeKey, true, null, sendBytes); //提交事务 channel.TxCommit(); } catch (Exception e) { channel.TxRollback(); } }
事务确实能够解决消息发送方和rabbitmq之间消息确认的问题,但使用事务机制会“吸干” rabbitmq的性能,下面提供一种更好的办法,即发送方确认机制。
4.8.2 发送方确认机制
前面介绍了Rabbitmq可能会遇到的一个问题,即消息发送方(生产者)并不知道消息是否真正到达了rabbbitmq,采用事务机制实现会严重降低消息的吞吐量,这里引入轻量级的方式----------发送方确认机制
如果消息和消息持久化的,那么确认消息会在消息写入磁盘之后发出。rabbitmq回传给生产者的确认消息中的deliveryTag包含了确认消息的序号。
生产者通过调用 channel.ConfirmSelect();方法将信道设置为confirm模式。
channel.ConfirmSelect(); //发布消息 channel.BasicPublish(exchangeName, "TopicExchangeKey.one", null, sendBytes); if (channel.WaitForConfirms()) { Console.WriteLine("消息已确认发送"); }
如果发送多条消息,只需要将BasicPublish和WaitForConfirms方法放在循环里面即可,不需要把ConfirmSelect放循环里面。
效率优化点: 1.批理confirm方法:每发送一批消息后,调用channel.WaitForConfirms方法,等待服务器的确认返回。但需要注意,超时情况下,客户端需要将这一批次的消息全部重发,这会带来明显的重复消息数量,并且当消息经常丢失时,批量confirm的性能应该是不升反降。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号