RabbitMQ 学习系列2 入门上(相关概念: 队列、交换机、路由键、消息生产和消费流程)
一.相关概念介绍
RabbitMQ整体上是一个生产者与消费者模型,主要负责接收,存储和转发消息。Rabbitmq好比邮局、邮箱和邮递员组成的一个系统,从计算机术语层面来说,rabbitmq模型更像一个交换机模型。

感悟:对于消费者来说,只需要操作队列,从队列中消费,不需要去创建队列,交换机,路由键等。 要创建应该是生产者或者是后台系统来配置,在实际生产环境中一般都是通过后台系统来配置,在业务代码端生产者和消费者都不需要创建。
1.1 生产者和消费者
Producer:生产者,投递消息的一方。消息一般可以包含2个部分:消息体和标签(label)。消息体也可以称之为payload,在实际应用中,消息体一般是一个带有业务逻辑结构的数据,比如一个josn字符串。消息的标签用来表述这条消息,比如一个交换器的名称和一个路由键。生产都把消息交由rabbitmq,rabbitmq之后会根据标签把消息发送给感兴趣的消费者(consumer)。
Consumer:消费者,接收消息一方。消费者连接到rabbitmq服务器,并订阅到队列上。当消费者消费一条消息时,只是消费的消息体(payload)。在消息路由的过程中,消息的标签会丢弃,存入到队列中的消息只有消息体,也就是不知道消息的生产者是谁,当然消息费都不需要知道。
Broker: 消息中间件的服务节点。一个rabbitmq Broker可以简单地看作一个rabbitmq 服务节点或者rabbitmq 服务实例。
下面展示了生产者将消息存入rabbitmq Broker,以及消费者从Broker中消费数据的整个流程:
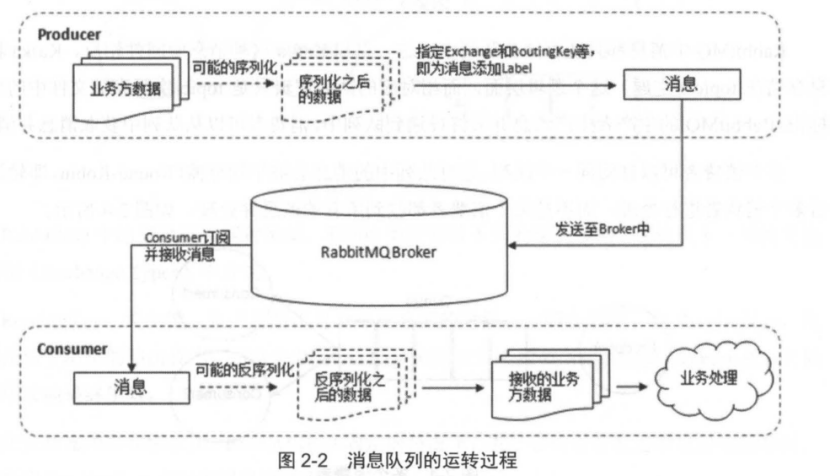
首先生产者将业务数据进行包装封装成消息,发送(AMQP 协议里这个动作对应的命令为Basic.Publish)到Broker中。消费者订阅并接收消息(AMQP协议里这个动作对应的命令为Basic.Consume或者Basic.Get),经过解包处理得到原始的数据。
1.2队列
Queue:队列,是rabbitmq的内部对象,用于存储消息. Rabbitmq中消息都只能存储在队列中,这一点和kafka这种消息中间件相反,kafka将消息存储在topic主题这个逻辑层面。
多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(round-robin 即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。
Rabbitmq不支持队列层面的广播消费,如果需要广播消费,需要在其上进行二次开发,处理逻辑会变得异常复杂,同进也不建议这么做。
1.3路由键
RoutingKey:路由键。 连接交换机和队列的“路由规则”
生产者将消息发给交换器的时候,一般会指定一个RoutingKey,用来指定这个消息的路由规则,而这个RoutingKey需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。
1.4绑定键
Binding:绑定。 rabbitmq中通过绑定将交换器与队列关联起来,在绑定的时候一般会指定一个绑定键(BindingKey),这样rabbitmq就知道如何正确地将消息路由到队列了。
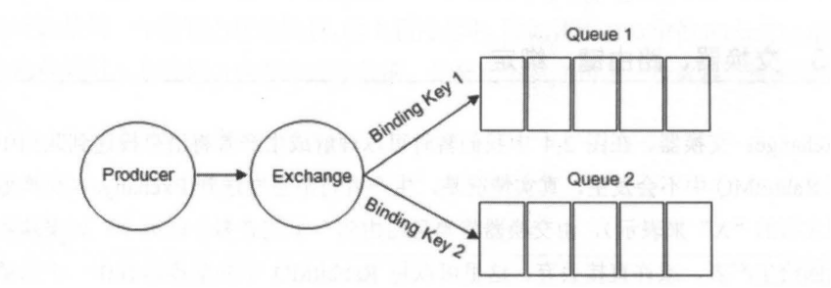
生产者将消息发送给交换器时,需要一个RoutingKey, 当BindingKey和RoutingKey相匹配时,消息会被路由到对应队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的BindingKey。
二. Exchange交换机
交换器是消息路由的中心,它不存储消息,只负责接收生产者的消息,并根据其类型和规则(绑定关系)将消息推送到相应的队列中。
大写X 来表示交换器,由交换器将消息路由到一个或者多个队列中,如果路由不到,或许会返回给生产者或者直接丢弃。
交换机类型有四种:fanout、direct、topic、headers,AMQP协议里还提到另外两种类型:system和自定义,这里不予描述。
2.1 direct(直连交换机)
--路由键与绑定键进行精确匹配,如果两者完全匹配,消息就会被路由到对应的队列。
--在RabbitMQ中,当声明一个队列时,如果没有指定交换机,会使用默认的直连交换机,队列名称作为路由键。
--直连交换机的设计是每个消息只路由到一个队列,通常我们使用一个路由键只绑定一个队列,这样消息就会只被投递到一个队列(即点对点模式)
--下面是生产端关键代码
//声明直连交换机 channel.ExchangeDeclare(exchange: exchangeName,type: ExchangeType.Direct, durable: true, autoDelete: false); //声明队列 channel.QueueDeclare(queue: queueName,durable: true,exclusive: false, autoDelete: false,arguments: null); //绑定队列,指定交换机,指定路由键 //例如:queueName="queue.log", 可以使用routingKey="error" 或 routingKey="debug"绑定到该队列名 channel.QueueBind(queue: queueName,exchange: exchangeName,routingKey: routingKey) //发送消息到直连交换机,并指定路由键 //当routingKey为error或者为debug时,消息发送到queue.log队列中 channel.BasicPublish(exchange: exchangeName,routingKey: routingKey,basicProperties: null,body: body);
2.2 topic(主题交换机)
--topic与direct类型的交换器相似,也是将消息路由到绑定键与路由键相匹配的队列中,是基于路由键和绑定键的模式匹配。
--路由键和绑定键之间需要做模糊匹配,两者并不是相同的。但是它约定了:
1)路由键为一个点号”.”分隔的字符串(被点号”.”分隔开的每一段独立的字符串称为一个单词)如 com.rabbitmq.client
2)绑定键和路由键一样也是点号”.”分隔的字符串
3)绑定键中可以存在两种特殊字符串”*”和”#”,用于做模糊匹配,其中”*”用于匹配一个单词,”#”用于匹配多规格单词(可以是零个)
--如下图是一个topic类型的交换机

1)当路由键为com.rabbitmq.client的消息会同时路由到Queue1和Queue2
2)当路由键为com.hidden.client的消息会路由到Queue2
3)当路由键为com.hidden.demo的消息会路由到Queue2
4)当路由键为java.rabbitmq.demo的消息会路由到Queue1
5)当路由键为java.util.concurrent的消息会被丢弃或者返回给生产者(需要设置mandatory参数),因为没有匹配任何路由键。
--下面是生产端关键代码
//声明主题交换机 channel.ExchangeDeclare(exchange:"topic_exchange_demo",type:ExchangeType.Topic,durable: true,autoDelete: false); //声明多个队列用于演示不同路由模式 var queues = new[] { "usa.orders.queue", // 美国订单队列 "europe.orders.queue", // 欧洲订单队列 "all.orders.queue", // 所有订单队列 }; foreach (var queue in queues){ channel.QueueDeclare( queue: queue,durable: true,exclusive: false,autoDelete: false,arguments: null ); } //绑定队列,指定交换机,指定路由键 //usa.orders.queue 只接收美国相关的订单 channel.QueueBind(queue: "usa.orders.queue",exchange: "topic_exchange_demo",routingKey: "orders.usa.*" ); //europe.orders.queue 只接收欧洲相关的订单 channel.QueueBind(queue: "europe.orders.queue",exchange: "topic_exchange_demo",routingKey: "orders.europe.*" ); //europe.orders.queue 接收所有地区订单 channel.QueueBind(queue: "all.orders.queue",exchange: "topic_exchange_demo",routingKey: "orders.*.*" );
//准备要发送的各种消息 var messages = new[] { // 订单相关消息 new { RoutingKey = "orders.usa.created", Message = "美国订单创建: 订单号 US-001" }, new { RoutingKey = "orders.usa.completed", Message = "美国订单完成: 订单号 US-001" }, new { RoutingKey = "orders.europe.created", Message = "欧洲订单创建: 订单号 EU-001" }, new { RoutingKey = "orders.europe.completed", Message = "欧洲订单完成: 订单号 EU-001" }, new { RoutingKey = "orders.asia.created", Message = "亚洲订单创建: 订单号 AS-001" }, }; //发送消息到 Topic 交换机 foreach (var msg in messages){ var body = Encoding.UTF8.GetBytes(msg.Message); // 发布消息到 Topic 交换机 channel.BasicPublish(exchange: "topic_exchange_demo", routingKey:msg.RoutingKey,basicProperties:null,body:body); }
--最后结论:all.orders.queue队列进入5条消息,usa.orders.queue和europe.orders.queue队列各进入2条消息。
--Routing Key与Binding Key只在直连和主题二种交换机下使用。
--Routing Key:生产者发送消息时指定的键,channel.BasicPublish 其中参数routingKey
--Binding Key:队列绑定到交换机时指定的键,channel.QueueBind 其中参数routingKey也叫bindingkey,RabbitMQ的客户端库在设计时,为了保持一致性,将这两个概念都命名为routingKey。这种设计可能是为了简化API,避免引入过多的术语。
--交换机总结:如果是直连交换机,通常一条消息只进入一个队列(设计目的:每个队列有唯一的绑定键,从而实现消息的点对点精确路由),路由键与绑定键的字符串值必须相等。
如果是主题交换机,一条消息会进入多个队列,路由键与绑定键之间通过模式匹配。
如果是扇出交换机,一条消息会进入交换机名绑定的所有队列。
2.3 fanout (扇出交换机)
路由规则:忽略路由键,将消息广播到所有绑定到该交换机的队列。每个队列都会收到消息的副本
--下面是生产端关键代码
//声明 Fanout 交换机 channel.ExchangeDeclare(exchange: "fanout_exchange_demo",type: ExchangeType.Fanout,durable: true,autoDelete: false,arguments: null); //声明多个队列用于演示广播效果 var queues = new[] { "email_service_queue", // 邮件服务队列 "sms_service_queue", // 短信服务队列 "audit_service_queue", // 审计服务队列 "analytics_service_queue", // 分析服务队列 "backup_service_queue" // 备份服务队列 }; foreach (var queue in queues) { channel.QueueDeclare(queue: queue,durable: true,exclusive: false,autoDelete: false,arguments: null); } //绑定所有队列到 Fanout 交换机,会忽略路由键,所以绑定时空字符串或任意值都可以 foreach (var queue in queues) { channel.QueueBind(queue:queue,exchange:"fanout_exchange_demo",routingKey: ""); } //准备要发送的消息 var messages = new[] { new { Message = "系统公告: 系统将于今晚 02:00-04:00 进行维护升级", Type = "系统维护通知" }, new { Message = "业务报告: 今日订单量突破 10,000 单,同比增长 25%", Type = "业务统计报告" }, new { Message = "安全提醒: 检测到异常登录尝试,请各部门加强安全监控", Type = "安全警报" }, new { Message = "促销活动: 双十一大促即将开始,请各服务做好准备", Type = "活动通知" } }; //发送消息到 Fanout 交换机 foreach (var msg in messages){ var body = Encoding.UTF8.GetBytes(msg.Message); // 发布消息到 Fanout 交换机 // 注意:路由键会被 Fanout 交换机忽略,可以传递空字符串或任意值 channel.BasicPublish(exchange: "fanout_exchange_demo", routingKey: "",basicProperties: null,body: body); }
--最后结论:每个队列都是进入4条消息,原因是对于Fanout交换机,当生产者发送一条消息时,该消息会被广播到所有绑定到该交换机的队列。因此,如果发送4条消息,那么每个绑定队列都会收到这4条消息。
2.4headers(头部交换机)
headers类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定队列和交换器时制定一组键值对,当发送消息到交换器时,rabbitmq会获取到该消息的headers(也是一个键值对的形式),对比其中的键值是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。Headers类型的交换器性能会很差,而且不实用,基本不会看到它的存在。
| 交换机类型 | 路由规则 | 使用场景 | 性能 |
| Direct |
路由:精确匹配 路由键 == 绑定键 |
点对点任务分发、按类别路由 | 非常高 |
| Topic | 路由:模式匹配 | 灵活的多维度消息路由 | 高(基于模式匹配,比直连/扇出稍慢) |
| Fanout | 忽略路由键 无意义的,通常为空"" |
发布/订阅、广播消息 | 非常高 |
| Headers | 忽略路由键,一组键值对的头信息 | 基于复杂应用属性的路由 | 低(需要检查消息头,性能最差) |
三. rabbitmq运转流程
生产者发送消息的过程:
1.生产者连接到 rabbitmq Broker,建立一个连接(Connection),开启一个信道(Channel)
2.生产者声明一个交换器,交设置相关属性,比如交换机类型,是否持久化等。
3.生产者声明一个队列,并设置相关属性,比如是否排他、是否持久化、是否自动删除等。
4.生产者通过路由键将交换器和队列绑定起来
5.生产都发送消息至RabbitMQ Broker,其中包含路由键、交换器等信息。
6.相应的交换器根据接收到的路由键查找相匹配的队列
7.如果找到,则将从生产者发送过来的消息存入相应的队列中.
8.如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
9.关闭信道
10.关闭连接
消费者接收消息的过程:
1.消费者连接到RabbitMQ Broker,建立一个连接(Connection),开启一个信道(Channel)
2.消费者向RabbitMQ Broker请求消费相应队列中的消息,可能会设置相应的回调函数,以及做一些准备工作.
3.等待RabbitMQ Broker回应并投递相应队列中的消息,消费者接收消息。
4.消费者确认(ack)接收到的消息。(如果不确认,还能再消费)
5.RabbitMQ从队列中删除相应已经被确认的消息
6.关闭信道。
7.关闭连接
这里又引入了两个新的概念,Connection和Channel。无论是生产者还是消费者,都需要和RabbitMQ Broker建立连接,这个连接就是一条TCP连接,也就是Connection。一但TCP连接建立起来,客户端紧接着可以创建一个AMQP信道(Channel),每个信道都会被指派一个唯一的ID。信道是建立在Connection之上的虚拟连接,RabbitMQ 处理的每条AMQP指令都是通过信道完成的。

我们完全可能直接使用Connection就能完成信息的工作,为什么还要引入信道,试想这样一个场景,一个应用程序中有很多个线程需要从RabbitMQ中消费消息或者生产消息,那么必然需要建立很多个Conection,也就是许多个TCP连接,然而对于操作系统而言,建立和销毁TCP连接是非常昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。RabbitMQ采用类似NIO(Non-blocking I/O 非阻塞I/O)的做法,选择TCP连接复用,不仅可以减少性能开销,同时也便于管理。
每个线程把持一个信道,所以信道复用了Connection的tcp连接。当每个信道流量不是很大时,复用单一的Connection可以在产生性能瓶颈的情况下有效地节省TCP连接资源,但是当信道本身的流量很大时,这时候复用一个Connection就会产生性能瓶颈,进而使整体的流量被限制了,此时就需要开廦多个Connection,将这些信道均摊到这些Connection中.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号