asp.net core系列 64 结合eShopOnWeb全面认识领域模型架构
一.项目分析
在上篇中介绍了什么是"干净架构",DDD符合了这种干净架构的特点,重点描述了DDD架构遵循的依赖倒置原则,使软件达到了低藕合。eShopOnWeb项目是学习DDD领域模型架构的一个很好案例,本篇继续分析该项目各层的职责功能,主要掌握ApplicationCore领域层内部的术语、成员职责。
1. web层介绍
eShopOnWeb项目与Equinox项目,双方在表现层方面对比,没有太大区别。都是遵循了DDD表现层的功能职责。有一点差异的是eShopOnWeb把表现层和应用服务层集中在了项目web层下,这并不影响DDD风格架构。
项目web表现层引用了ApplicationCore领域层和Infrastructure基础设施层,这种引用依赖是正常的。引用Infrastructure层是为了添加EF上下文以及Identity用户管理。 引用ApplicationCore层是为了应用程序服务 调用 领域服务处理领域业务。
在DDD架构下依赖关系重点强调的是领域层的独立,领域层是同心圆中最核心的层,所以在eShopOnWeb项目中,ApplicationCore层并没有依赖引用项目其它层。再回头看Equinox项目,领域层也不需要依赖引用项目其它层。
下面web混合了MVC和Razor,结构目录如下所示:

(1) Health checks
Health checks是ASP.NET Core的特性,用于可视化web应用程序的状态,以便开发人员可以确定应用程序是否健康。运行状况检查端点/health。
//添加服务 services.AddHealthChecks() .AddCheck<HomePageHealthCheck>("home_page_health_check") .AddCheck<ApiHealthCheck>("api_health_check"); //添加中间件 app.UseHealthChecks("/health");
下图检查了web首页和api接口的健康状态,如下图所示

(2) Extensions
向现有对象添加辅助方法。该Extensions文件夹有两个类,包含用于电子邮件发送和URL生成的扩展方法。
(3) 缓存
对于Web层获取数据库的数据,如果数据不会经常更改,可以使用缓存,避免每次请求页面时,都去读取数据库数据。这里用的是本机内存缓存。
//缓存接口类 private readonly IMemoryCache _cache; // 添加服务,缓存类实现 services.AddScoped<ICatalogViewModelService, CachedCatalogViewModelService>(); //添加服务,非缓存的实现 //services.AddScoped<ICatalogViewModelService, CatalogViewModelService>();
2. ApplicationCore层
ApplicationCore是领域层,是项目中最重要最复杂的一层。ApplicationCore层包含应用程序的业务逻辑,此业务逻辑包含在领域模型中。领域层知识在Equinox项目中并没有讲清楚,这里在重点解析领域层内部成员,并结合项目来说清楚。
下面讲解领域层内部的成员职责描述定义,参考了“Microsoft.NET企业级应用架构设计 第二版”。
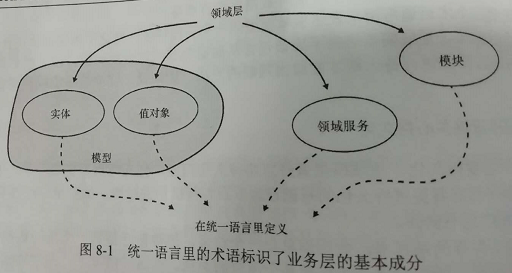
领域层内部包括:领域模型和领域服务二大块。涉及到的术语:
领域模型(模型)
1)模块
2)领域实体(也叫"实体")
3)值对象
4)聚合
领域服务(也叫"服务")
仓储
下面是领域层主要的成员:
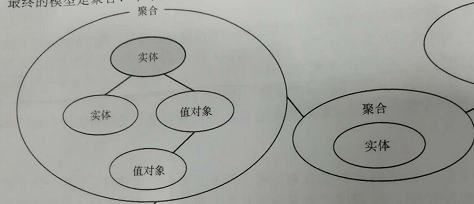
下面是聚合与领域模型的关系。最终领域模型包含了:聚合、单个实体、值对象的结合。
(1) 领域模型
领域模型是提供业务领域的概念视图,它由实体和值对象构成。在下图中Entities文件夹是领域模型,可以看到包含了聚合、实体、值对象。
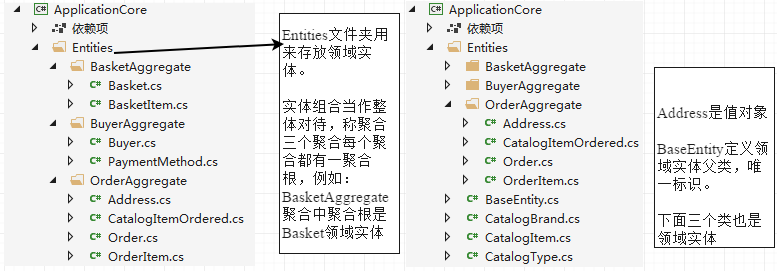
1.1 模块
模块是用来组织领域模型,在.net中领域模型通过命令空间组织,模块也就是命名空间,用来组织类库项目里的类。比如:
namespace Microsoft.eShopWeb.ApplicationCore.Entities.BasketAggregate namespace Microsoft.eShopWeb.ApplicationCore.Entities.BuyerAggregate
1.2 实体
实体通常由数据和行为构成。如果要在整个生命周期的上下文里唯一跟踪它,这个对象就需要一个身份标识(ID主键),并看成实体。 如下所示是一个实体:
/// <summary> /// 领域实体都有唯一标识,这里用ID做唯一标识 /// </summary> public class BaseEntity { public int Id { get; set; } } /// <summary> /// 领域实体,该实体行为由Basket聚合根来操作 /// </summary> public class BasketItem : BaseEntity { public decimal UnitPrice { get; set; } public int Quantity { get; set; } public int CatalogItemId { get; set; } }
1.3 值对象
值对象和实体都由.net 类构成。值对象是包含数据的类,没有行为,可能有方法本质上是辅助方法。值对象不需要身份标识,因为它们不会改变状态。如下所示是一个值对象
/// <summary> /// 订单地址 值对象是普通的DTO类,没有唯一标识。 /// </summary> public class Address // ValueObject { public String Street { get; private set; } public String City { get; private set; } public String State { get; private set; } public String Country { get; private set; } public String ZipCode { get; private set; } private Address() { } public Address(string street, string city, string state, string country, string zipcode) { Street = street; City = city; State = state; Country = country; ZipCode = zipcode; } }
1.4 聚合
在开发中单个实体总是互相引用,聚合的作用是把相关逻辑的实体组合当作一个整体对待。聚合是一致性(事务性)的边界,对领域模型进行分组和隔离。聚合是关联的对象(实体)群,放在一个聚合容器中,用于数据更改的目的。每个聚合通常被限制于2~3个对象。聚合根在整个领域模型都可见,而且可以直接引用。
/// <summary> /// 定义聚合根,严格来说这个接口不需要任务功能,它是一个普通标记接口 /// </summary> public interface IAggregateRoot { } /// <summary> /// 创建购物车聚合根,通常实现IAggregateRoot接口 /// 购物车聚合模型(包括Basket、BasketItem实体) /// </summary> public class Basket : BaseEntity, IAggregateRoot { public string BuyerId { get; set; } private readonly List<BasketItem> _items = new List<BasketItem>(); public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly(); //... }
在该项目中领域模型与“Microsoft.NET企业级应用架构设计第二版”书中描述的职责有不一样地方,来看一下:
(1) 领域服务有直接引用聚合中的实体(如:BasketItem)。书中描述是聚合中实体不能从聚合之处直接引用,应用把聚合看成一个整体。
(2) 领域实体几乎都是贫血模型。书中描述是领域实体应该包括行为和数据。
(2) 领域服务
领域服务类方法实现领域逻辑,不属于特定聚合中(聚合是属于领域模型的),很可能跨多个实体。当一块业务逻辑无法融入任何现有聚合,而聚合又无法通过重新设计适应操作时,就需要考虑使用领域服务。下图是领域服务文件夹:

/// <summary> /// 下面是创建订单服务,用到的实体包括了:Basket、BasketItem、OrderItem、Order跨越了多个聚合,该业务放在领域服务中完全正确。 /// </summary> /// <param name="basketId">购物车ID</param> /// <param name="shippingAddress">订单地址</param> /// <returns>回返回类型</returns> public async Task CreateOrderAsync(int basketId, Address shippingAddress) { var basket = await _basketRepository.GetByIdAsync(basketId); Guard.Against.NullBasket(basketId, basket); var items = new List<OrderItem>(); foreach (var item in basket.Items) { var catalogItem = await _itemRepository.GetByIdAsync(item.CatalogItemId); var itemOrdered = new CatalogItemOrdered(catalogItem.Id, catalogItem.Name, catalogItem.PictureUri); var orderItem = new OrderItem(itemOrdered, item.UnitPrice, item.Quantity); items.Add(orderItem); } var order = new Order(basket.BuyerId, shippingAddress, items); await _orderRepository.AddAsync(order); }
在该项目与“Microsoft.NET企业级应用架构设计第二版”书中描述的领域服务职责不完全一样,来看一下:
(1) 项目中,领域服务只是用来执行领域业务逻辑,包括了订单服务OrderService和购物车服务BasketService。书中描述是可能跨多个实体。当一块业务逻辑无法融入任何现有聚合。
/// <summary> /// 添加购物车服务,没有跨越多个聚合,应该不放在领域服务中。 /// </summary> /// <param name="basketId"></param> /// <param name="catalogItemId"></param> /// <param name="price"></param> /// <param name="quantity"></param> /// <returns></returns> public async Task AddItemToBasket(int basketId, int catalogItemId, decimal price, int quantity) { var basket = await _basketRepository.GetByIdAsync(basketId); basket.AddItem(catalogItemId, price, quantity); await _basketRepository.UpdateAsync(basket); }
总的来说,eShopOnWeb项目虽然没有完全遵循领域层中,成员职责描述,但可以理解是在代码上简化了领域层的复杂性。
(3) 仓储
仓储是协调领域模型和数据映射层的组件。仓储是领域服务中最常见类型,它负责持久化。仓储接口的实现属于基础设施层。仓储通常基于一个IRepository接口。 下面看下项目定义的仓储接口。

/// <summary> /// T是领域实体,是BaseEntity类型的实体 /// </summary> /// <typeparam name="T"></typeparam> public interface IAsyncRepository<T> where T : BaseEntity { Task<T> GetByIdAsync(int id); Task<IReadOnlyList<T>> ListAllAsync(); //使用领域规则查询 Task<IReadOnlyList<T>> ListAsync(ISpecification<T> spec); Task<T> AddAsync(T entity); Task UpdateAsync(T entity); Task DeleteAsync(T entity); //使用领域规则查询 Task<int> CountAsync(ISpecification<T> spec); }
(4) 领域规则
在仓储设计查询接口时,可能还会用到领域规则。 在仓储中一般都是定义固定的查询接口,如上面仓储的IAsyncRepository所示。而复杂的查询条件可能需要用到领域规则。在本项目中通过强大Linq 表达式树Expression 来实现动态查询。

/// <summary> /// 领域规则接口,由BaseSpecification实现 /// 最终由Infrastructure.Data.SpecificationEvaluator<T>类来构建完整的表达树 /// </summary> /// <typeparam name="T"></typeparam> public interface ISpecification<T> { //创建一个表达树,并通过where首个条件缩小查询范围。 //实现:IQueryable<T> query = query.Where(specification.Criteria) Expression<Func<T, bool>> Criteria { get; } //基于表达式的包含 //实现如: Includes(b => b.Items) List<Expression<Func<T, object>>> Includes { get; } List<string> IncludeStrings { get; } //排序和分组 Expression<Func<T, object>> OrderBy { get; } Expression<Func<T, object>> OrderByDescending { get; } Expression<Func<T, object>> GroupBy { get; } //查询分页 int Take { get; } int Skip { get; } bool isPagingEnabled { get;} }
最后Interfaces文件夹中定义的接口,都由基础设施层来实现。如:
IAppLogger日志接口
IEmailSender邮件接口
IAsyncRepository仓储接口
3.Infrastructure层
基础设施层Infrastructure依赖于ApplicationCore,这遵循依赖倒置原则(DIP),Infrastructure中代码实现了ApplicationCore中定义的接口(Interfaces文件夹)。该层没有太多要讲的,功能主要包括:使用EF Core进行数据访问、Identity、日志、邮件发送。与Equinox项目的基础设施层差不多,区别多了领域规则。

领域规则SpecificationEvaluator.cs类用来构建查询表达式(Linq expression),该类返回IQueryable<T>类型。IQueryable接口并不负责查询的实际执行,它所做的只是描述要执行的查询。
public class EfRepository<T> : IAsyncRepository<T> where T : BaseEntity { //...这里省略的是常规查询,如ADDAsync、UpdateAsync、GetByIdAsync ... //获取构建的查询表达式 private IQueryable<T> ApplySpecification(ISpecification<T> spec) { return SpecificationEvaluator<T>.GetQuery(_dbContext.Set<T>().AsQueryable(), spec); } }
public class SpecificationEvaluator<T> where T : BaseEntity { /// <summary> /// 做查询时,把返回类型IQueryable当作通货 /// </summary> /// <param name="inputQuery"></param> /// <param name="specification"></param> /// <returns></returns> public static IQueryable<T> GetQuery(IQueryable<T> inputQuery, ISpecification<T> specification) { var query = inputQuery; // modify the IQueryable using the specification's criteria expression if (specification.Criteria != null) { query = query.Where(specification.Criteria); } // Includes all expression-based includes //TAccumulate Aggregate<TSource, TAccumulate>(this IEnumerable<TSource> source, TAccumulate seed, Func<TAccumulate, TSource, TAccumulate> func); //seed:query初始的聚合值 //func:对每个元素调用的累加器函数 //返回TAccumulate:累加器的最终值 //https://msdn.microsoft.com/zh-cn/windows/desktop/bb549218 query = specification.Includes.Aggregate(query, (current, include) => current.Include(include)); // Include any string-based include statements query = specification.IncludeStrings.Aggregate(query, (current, include) => current.Include(include)); // Apply ordering if expressions are set if (specification.OrderBy != null) { query = query.OrderBy(specification.OrderBy); } else if (specification.OrderByDescending != null) { query = query.OrderByDescending(specification.OrderByDescending); } if (specification.GroupBy != null) { query = query.GroupBy(specification.GroupBy).SelectMany(x => x); } // Apply paging if enabled if (specification.isPagingEnabled) { query = query.Skip(specification.Skip) .Take(specification.Take); } return query; } }
参考资料
Microsoft.NET企业级应用架构设计 第二版

 浙公网安备 33010602011771号
浙公网安备 33010602011771号