Hive与Hadoop的交互流程
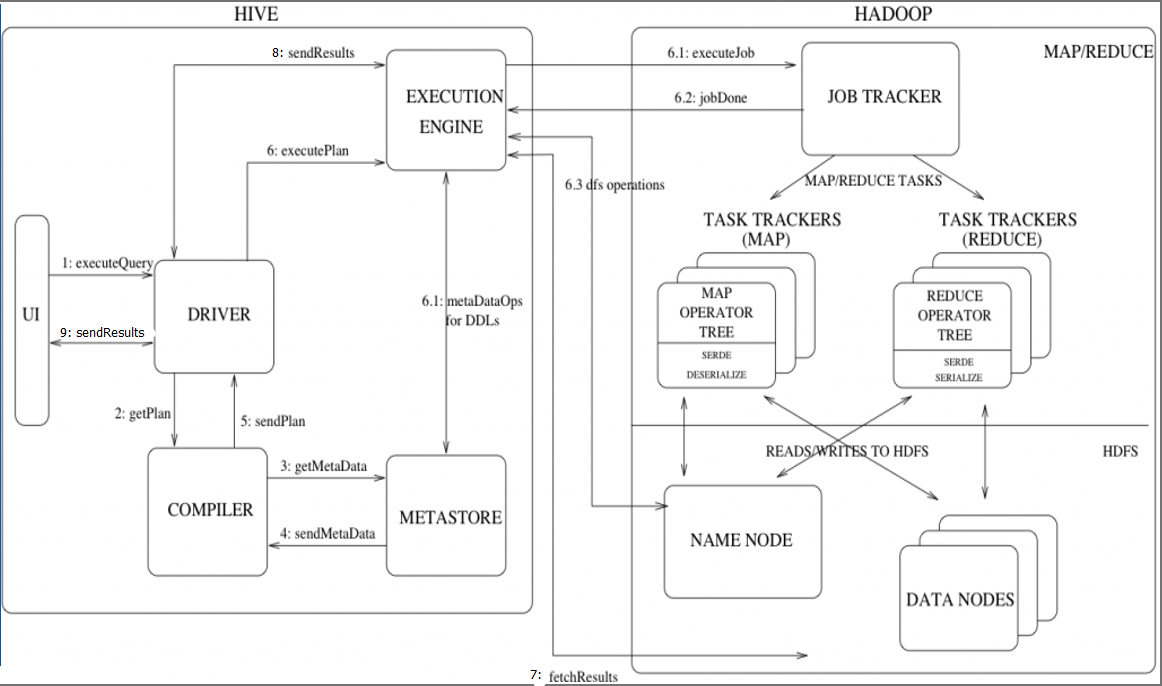
1、 executeQuery:用户通过Hive界面(CLI/Web UI)将查询语句发送到Driver(驱动有JDBC、ODBC等)来执行;
2、 getPlan :Driver根据查询编译器解析query语句,验证query语句的语法、查询计划、查询条件;
3、 getMetaData:编译器将元数据请求发送给Metastore;
4、 send MetaData:Metastore将元数据作为响应发送给编译器;
5、 send Plan:编译器检查要求和重新发送Driver的计划。至此,查询的解析和编译完成;
6、 execute Plan:Driver将执行计划发送给执行引擎;
6.1、 MetaDataOps for DDLs:执行引擎发送任务的同时,对hive元数据进行相应操作(直接对数据库表进行操作的(创建表、删除表等),直接与MetaStore进行交互)。
6.1、 execute Job:mapreduce执行job的过程。执行引擎发送任务到resourcemanager,resourcemanager将任务分配给nodenameger,由nodemanager分布式执行mapreduce任务。
6.2、 任务执行结束,返回执行结果给执行引擎,同步执行6.3;
6.3、 找Namenode获取数据
7、fetch Results:执行引擎接收来自数据节点(data node)的结果
8、sendResults:执行引擎发送这些合成值到Driver
9、sendResults:Driver将结果发送到hive接口
爱家,更要爱技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号