全文检索Elasticsearch研究
全文检索Elasticsearch研究
基于虚拟机服务器自主部署ELK服务
学习目标
了解Elasticsearch的应用场景 学习基于服务器部署ELK服务 掌握索引维护的方法 掌握索引维护的方法 掌握基本的搜索API的使用方法
约束
需要提前掌握Lucene的索引方法、搜索方法
ELK的介绍和安装
1.简介
Elasticsearch是一个基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎,基于Restful web接口。Elasticsearch是用java开发的,是当前流行的企业级搜索引擎。能到达到实时搜索,稳定、可靠、快速、安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,如果搜索的数量非常多,而且分类繁杂,如果使用传统的数据库想要完成搜索工作的创建失非常困难的。我们希望搜索解决方案要运行速度快,我们希望有一个零配置和完全免费的搜索模式,能够简单的使用JSON通过HTTP来索引数据,而搜索服务器始终可用,并且服务器可以自如扩展,我们一般都会使用全文检索技术,如solr、Elasticsearch等。
2.突出优点
扩展性好,可部署上百台服务器集群,处理PB级数据 近实时的去索引数据、搜索数据
3.原理与应用
3.1 索引结构
下图是ElasticSearch的索引结构,下边==黑色部分是物理结构==,上边==黄色部分是逻辑结构==,逻辑结构可以更好的描述ElasticSearch的工作原理及去使用物理结构中的索引文件。
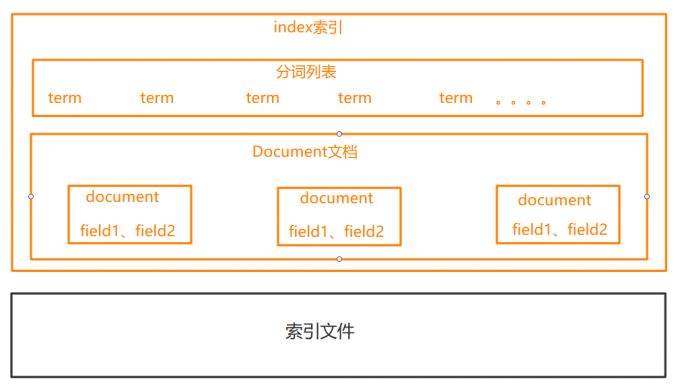
逻辑结构部分是一个倒排索引表:
将要搜索的文档内容分词,所有不重复的词做成分词列表。 将搜索的文档最终以Document方式存储起来。 每个词和document都有关联。
3.2 RESTFUL应用方法
ElasticSearch提供RESTFUL Api接口进行索引、搜索、并且支持多种客户端。
下图是ElasticSearch在项目中的应用方式:
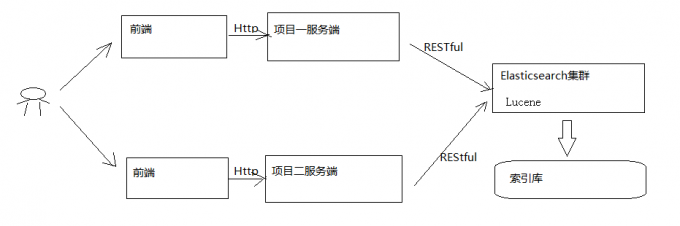
用户在前端搜索关键字 项目前端通过http方式请求项目服务端 项目服务端通过http RESTful方式请求ES集群进行搜索 ES集群从索引库检索数据
4.ElasticaSearc安装
4.1 安装配置
安装ElasticaSearc7.9.0 该版本要求至少jdk1.8以上 解压elasticsearch-7.9.0-linux-x86_64.tar.gz bin:脚本目录,包括:启动、停止等可执行脚本 config:配置文件目录 data:索引目录,存放索引文件的地方 modules:模板目录,包括了es的功能模块 plugins:插件目录,es支持插件机制
4.2 配置文件
ES配置文件的地址根据安装形式的不同而不同:
使用zip、tar安装,配置文件的地址在安装目录的config下 使用RPM安装,配置文件在/etc/elasticsearch下 使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF
4.3 安装
为了模拟真实场景,我们将在linux系统下安装Elasticsearch
4.3.1 新建一个用户gavin
处于安全考虑,Elasticsearch默认不允许以root账号运行
创建用户:
useradd gavin
设置密码:
passwd gavin
切换用户:
su gavin
删除用户:
userdel -r gavin
普通用户增加sudo命令的权限:
vim /etc/sudoers
gavin ALL=(ALL) ALL
改变目录及其目录下所有文件的所有者为当前普通用户:
chown -R yourname dirname

4.3.3 解压缩
tar -zxvf elasticsearch-7.9.0-linux-x86_64.tar.gz
4.3.4 目录重命名
mv elasticsearch-7.9.0 elasticsearch
4.3.5 修改配置文件
进入config目录,修改elasticsearch.yml和jvm.options
jvm.options
默认配置:
-Xms1g
-Xmx1g
内存占用太多,设置为不超过物理内存的一半:
-Xms512m
-Xmx512m
elasticsearch.yml
修改数据和日志目录
# 数据目录位置
path.data: /home/gavin/elasticsearch/data
# 日志目录位置
path.logs: /home/gavin/elasticsearch/logs
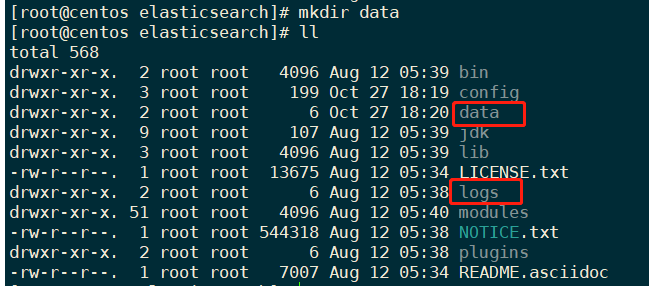
elasticsearch的安装目录默认只有logs目录,没有data目录,需要手动创建:
mkdir data
修改绑定的ip:
# 绑定0.0.0.0 允许任何ip来访问,默认只允许本机访问
network.host: 0.0.0.0
目前我们是学习单机安装,如果要做集群,只需要在这个配置文件中添加节点信息即可。
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
4.4 运行
进入elasticsearch/bin*目录下,可以看到如下的可执行文件:
然后输入运行命令:
./elasticsearch
4.5 启动报错
4.5.1 JDK版本过低 并且 不支持 root用户启动
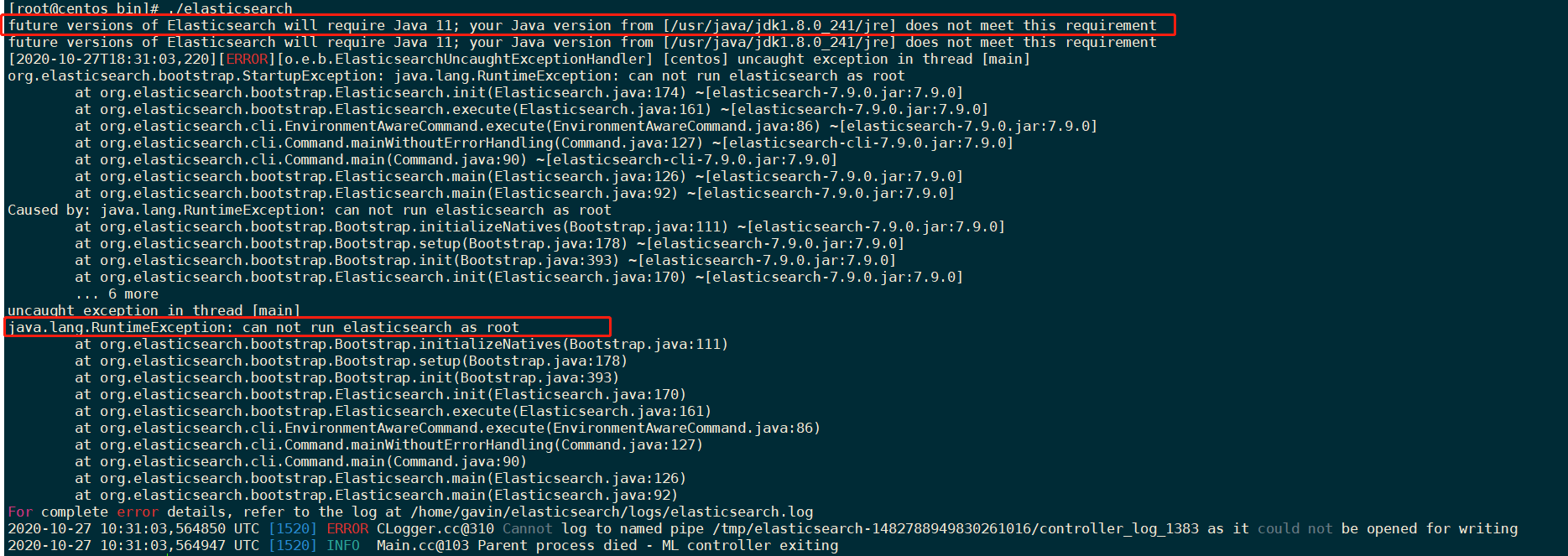
解决方案:
1.因为elasticsearch7.9.X内置了jdk,默认是jdk11,但是向下兼容,所以可以不用处理
2.切换到普通用户进行启动,此时需要修改文件目录下所有文件的所有者为当前用户。
chown -R gavin /home/gavin/elasticsearch
4.5.2 集群节点导致启动报错

解决:
vim elasticsearch.yml
ip替换host1等,多节点请添加多个ip地址,单节点可写按默认来
#配置以下三者,最少其一
#[discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes]
cluster.initial_master_nodes: ["node-1"] #这里的node-1为node-name配置的值
启动成功:
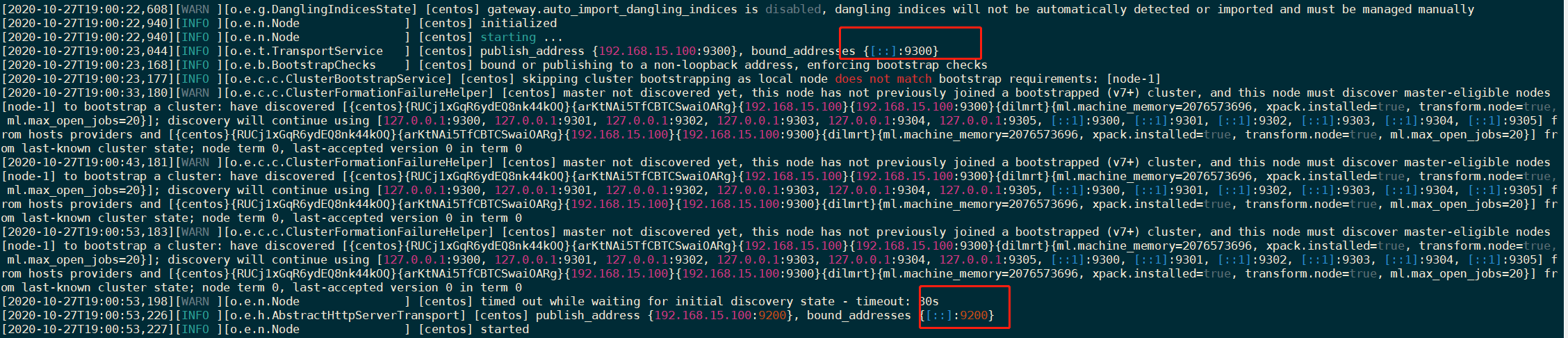
可以看到绑定了两个端口:
9200:客户端访问端口 9300:集群节点之间通讯端口
我们在浏览器中访问:http://192.168.15.100:9200/
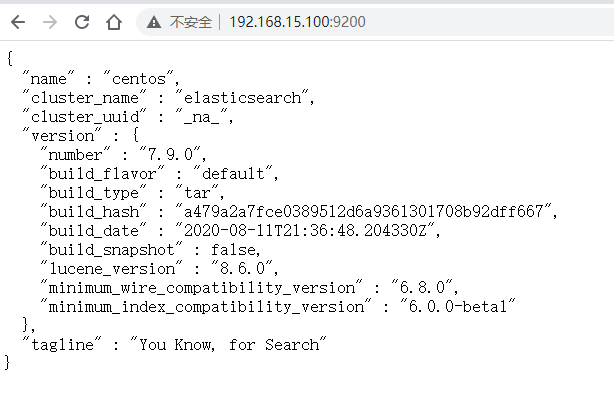
5.安装kibana
kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱状图、线状图、饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于学习Elasticsearch的语法。
5.1 安装
因为Kibana是依赖于node
查看是否服务器是否安装nodejs
[root@centos logs]# node -v
v9.3.0
如果没有安装,则安装步骤如下:
1.可以在下载页面https://nodejs.org/en/download/中找到下载地址,然后执行指令
wget https://nodejs.org/dist/v9.3.0/node-v9.3.0-linux-x64.tar.xz
2.解压缩
xz -d node-v9.3.0-linux-x64.tar.xz
tar -xf node-v9.3.0-linux-x64.tar
3.部署bin文件
根据自己nodejs的实际路径,依次执行下面命令,建立软连接:
ln -s /usr/local/software/node/bin/node /usr/bin/node
ln -s /usr/local/software/node/bin/npm /usr/bin/npm
ln -s /usr/local/software/node/bin/npx /usr/bin/npx
4.测试
node -v
npm -v
npx -v
5.1.1 解压缩kibana
tar -zxvf kibana-7.9.0-linux-x86_64.tar.gz
5.1.2 重命名安装包
mv kibana-7.9.0-linux-x86_64 kibana
5.1.3 修改配置
vim /home/gavin/kibana/config/kibana.yml
elasticsearch.hosts: ["http://192.168.15.100:9200"]
5.2 启动
cd /home/gavin/kibana/bin
./kibana
6.安装ik分析器
Lucene的IK分词器早在2012年就已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为ElasticSearch的继承插件了,与ElasticSearch一起维护升级了,版本也保持一致。
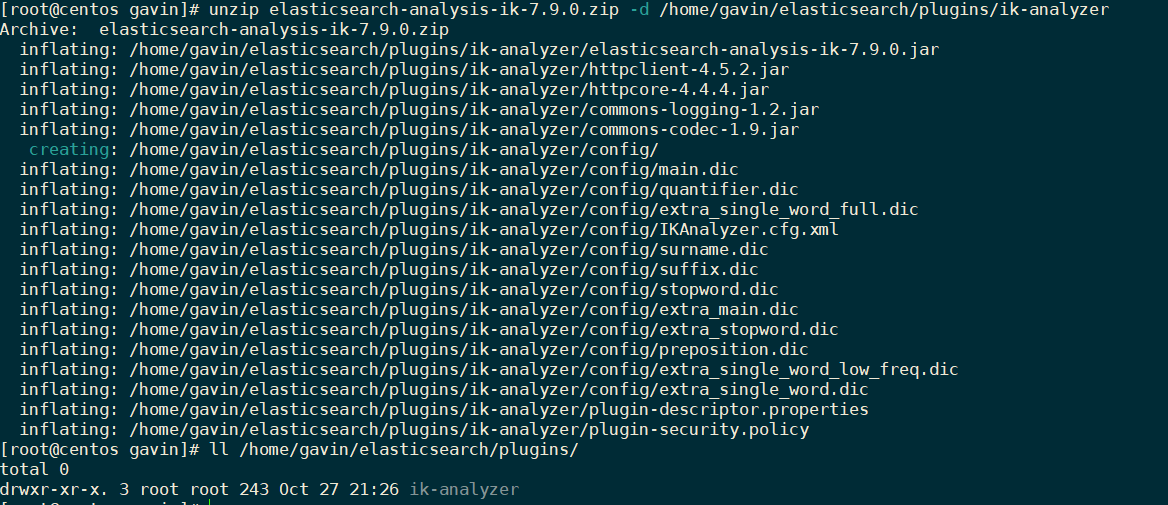
6.1 解压缩
unzip elasticsearch-analysis-ik-7.9.0.zip -d /home/gavin/kibana/plugins/ik-analyzer
6.2 重启elasticsearch
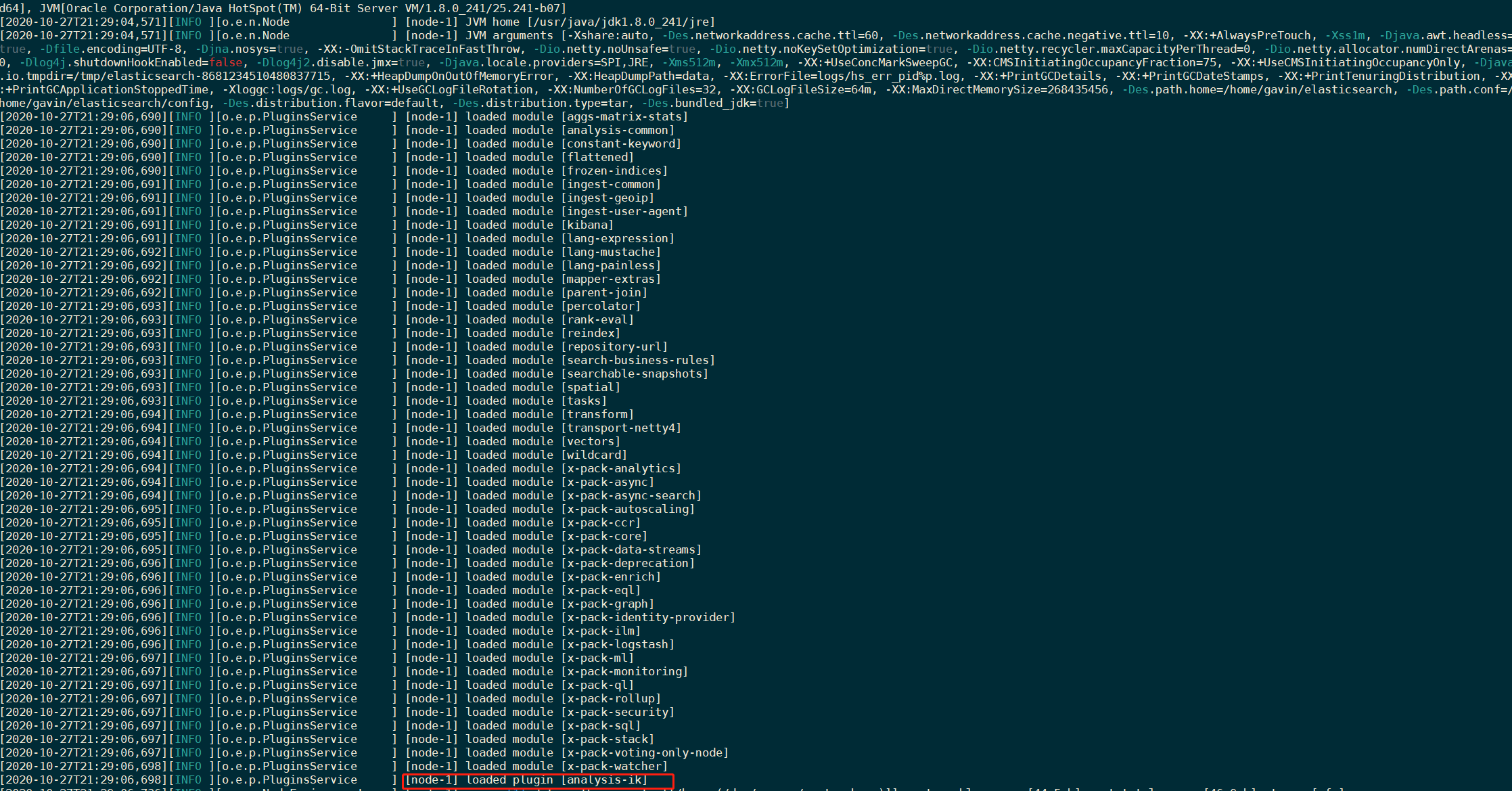
加载IK分词器插件、
6.3 测试
在Dev Tools --> console 中输入下面请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
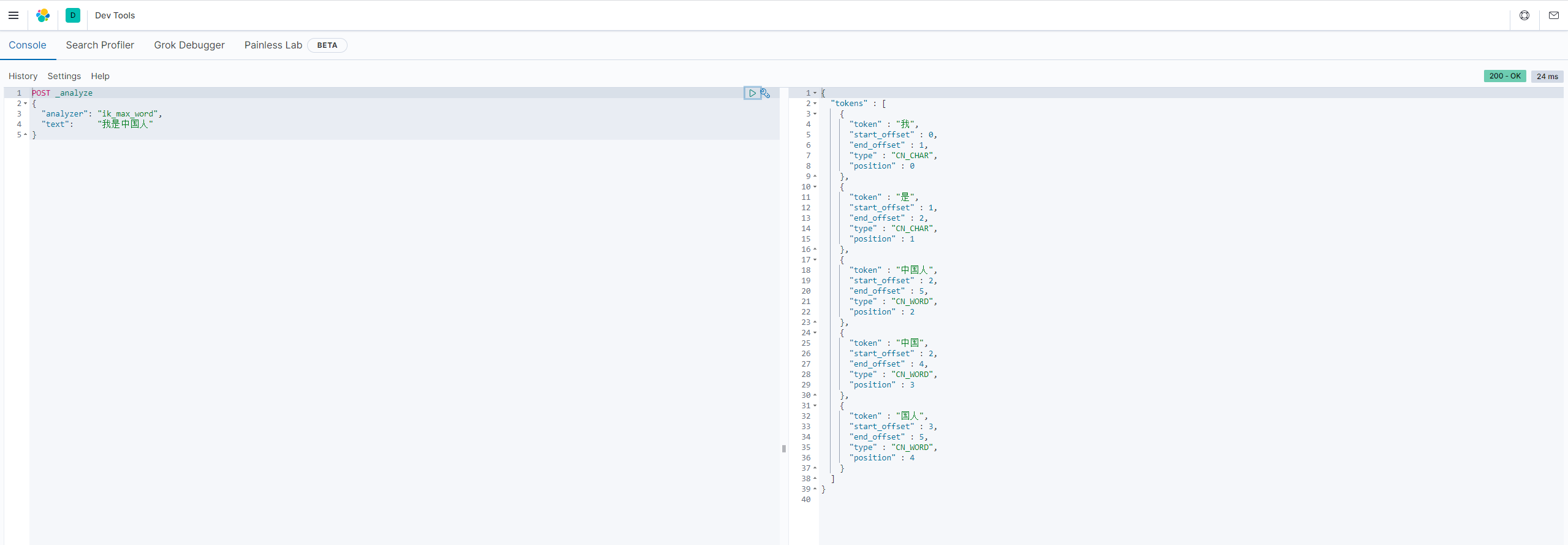
API
Elasticsearch提供了Rest风格的API,即http请求接口,而且也提供了各种语言的客户端API
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
1.客户端API
Elasticsearch支持的客户端非常多,如:https://www.elastic.co/guide/en/elasticsearch/client/index.html
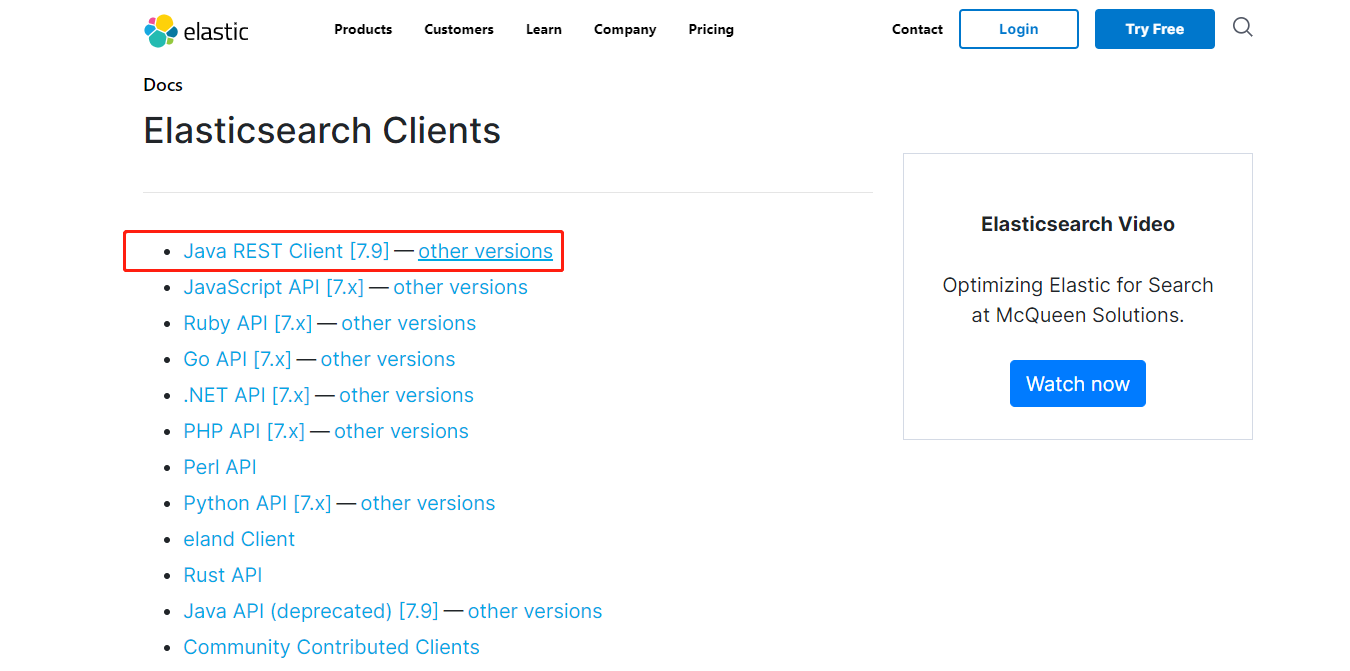
点开Java Rest Client后,会有两个:
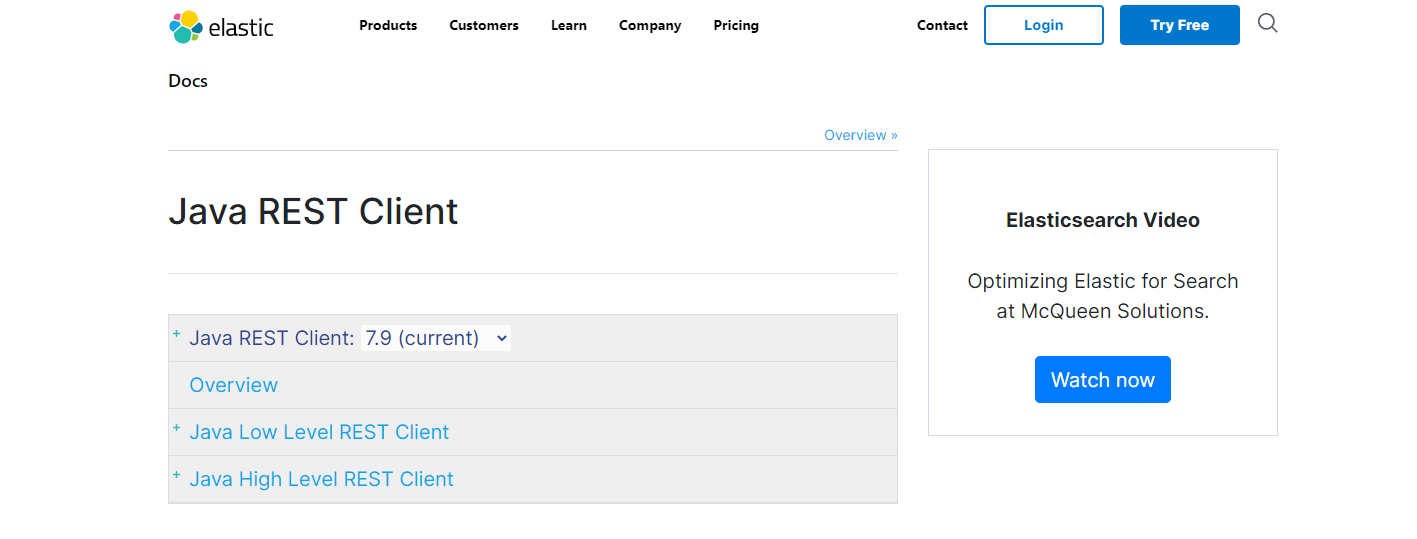
Java Low Level REST Client:是低级别封装,提供一些基础功能,但更灵活 Java High Level REST Client:是在Low Level Rest Client基础上进行的高级别封装,功能更丰富和完善,而且API会变得简单
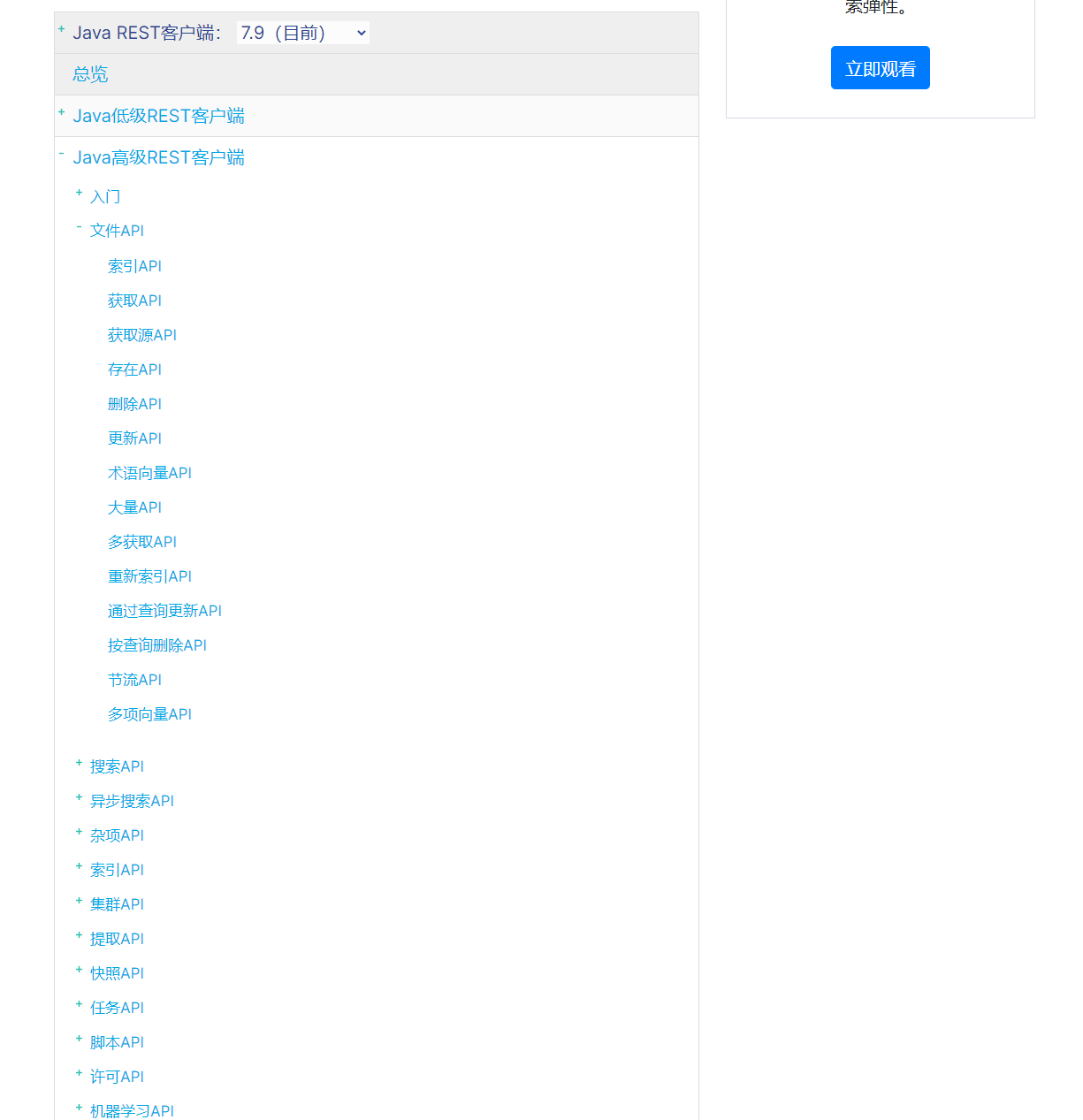
2.如何学习
2.1 操作索引
Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与mysql类似
对比关系:
索引(indices) --------------------------------------------- Databases 数据库
类型(type) ------------------------------------------ Table 数据表
文档(Document) ---------------------------Row 行
字段(field) -----------------------------Columns 列
说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引 |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引、订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型,属性、是否索引、是否存储等特性 |
特别说明:
Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡
2.2语法
Elasticsearch采用Rest风格API,因此其API就是一次http请求,可以使用任何工具进行发起http请求
2.1.1 索引库设置
创建索引索引库设置:
请求方式:PUT
请求路径:/索引名
请求参数:json格式:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}settings:索引库的设置
number_of_shards:分片数量
number_of_replicas:副本数量
测试
使用postman进行创建索引并对索引库进行设置测试
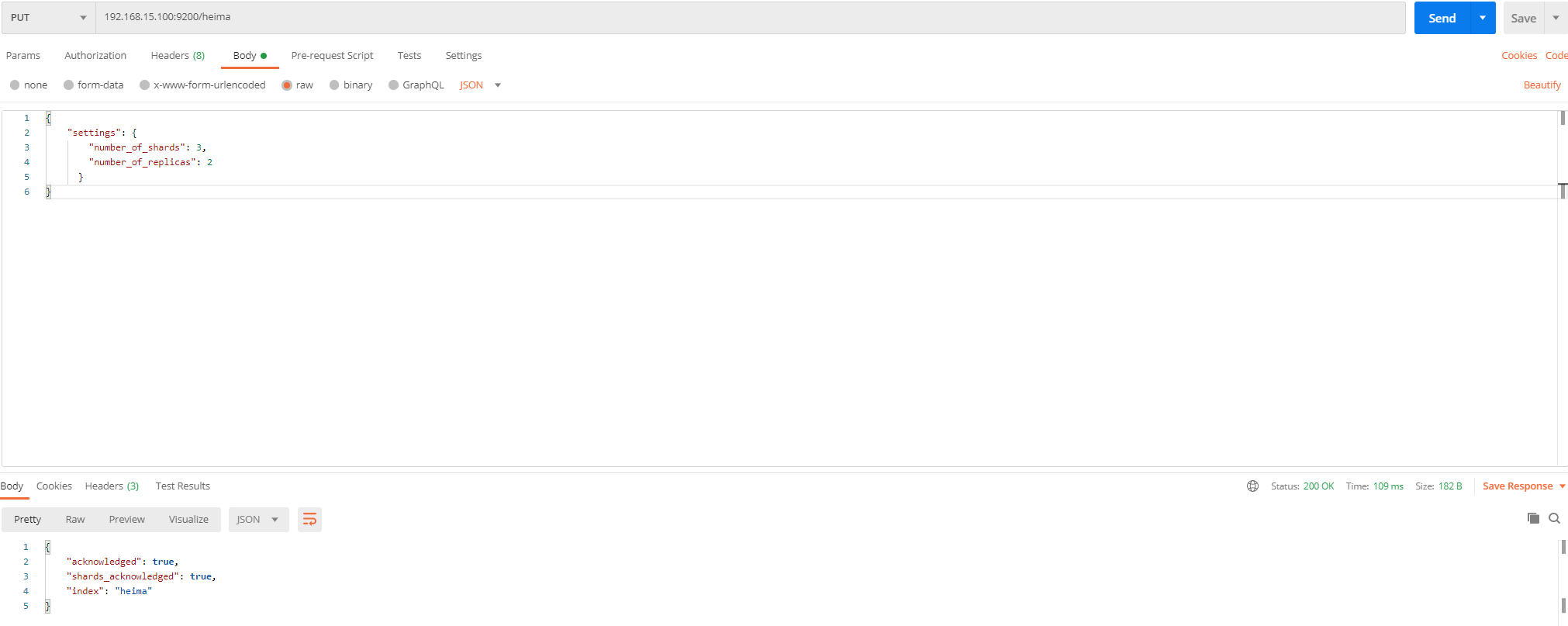
2. 使用kibana进行创建索引并对索引库进行设置测试

查看索引库设置
语法:
GET ceshi

或者,使用*来查询所有索引配置:

删除索引库设置
语法:
DELETE /索引库名

再次查看
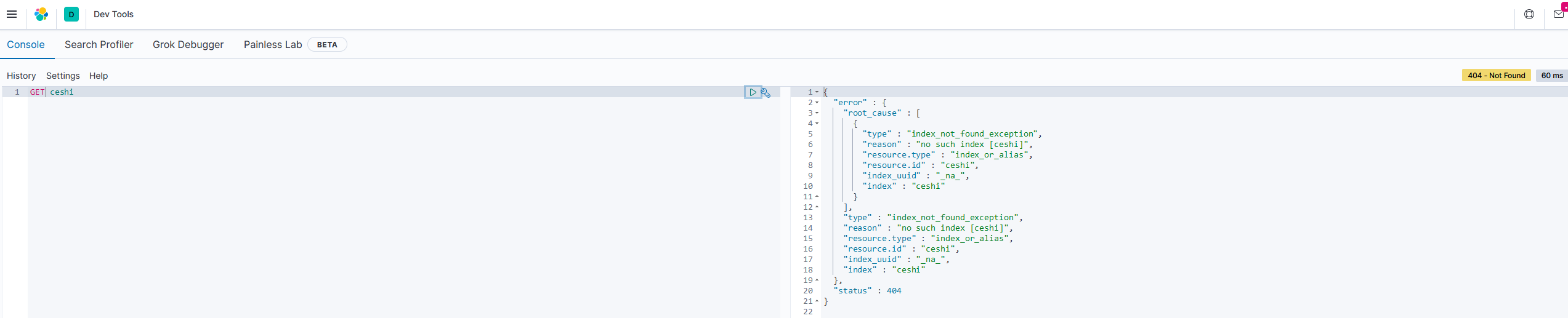
2.1.2 映射配置
索引库创建好之后就是添加数据,再添加数据之前必须定义映射
映射:
定义文档的过程,文档包含哪些字段,这些字段是否保存、是否索引、是否分词等
创建映射字段
语法:
请求方式是PUT,类型名称和_mapping可以互换位置
PUT /索引库名称/_doc/类型名称
{
"properties": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}类型:就是前面提过的type的概念,类似于数据库中的不同表
字段名:任意填写,可以指定很多属性,如:
type:类型,可以是text、long、short、date、integer、object等 index:是否索引,默认为true store:是否存储,默认是false analyzer:分词器,这里的 ik_max_word即表示使用ik分词器
示例:
请求:
PUT ceshi/_doc/goods
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "float"
}
}
}
特别说明:
传统ES6创建映射的时候是把上面的**_doc换成_mapping**
ES7这个**_mapping已经移除了,使用_doc**代替
否则会报如下错误:

响应结果:
{
"_index" : "ceshi",
"_type" : "_doc",
"_id" : "goods",
"_version" : 3,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
查看映射关系
语法:
GET 索引库名/_mapping示例:
GET ceshi/_mapping结果:
![]()
字段属性详解
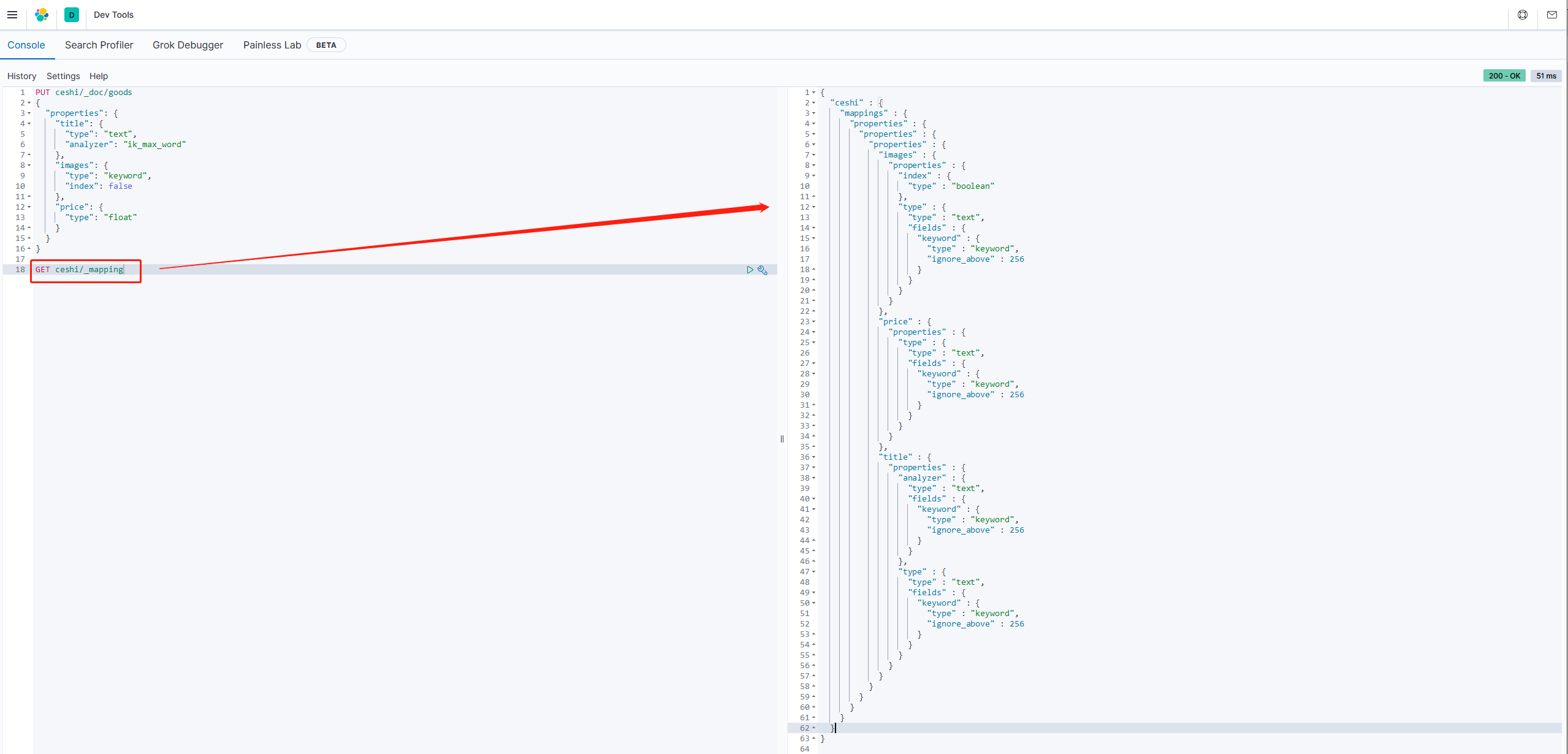
3.1 type
Elasticsearch中支持的数据类型非常丰富
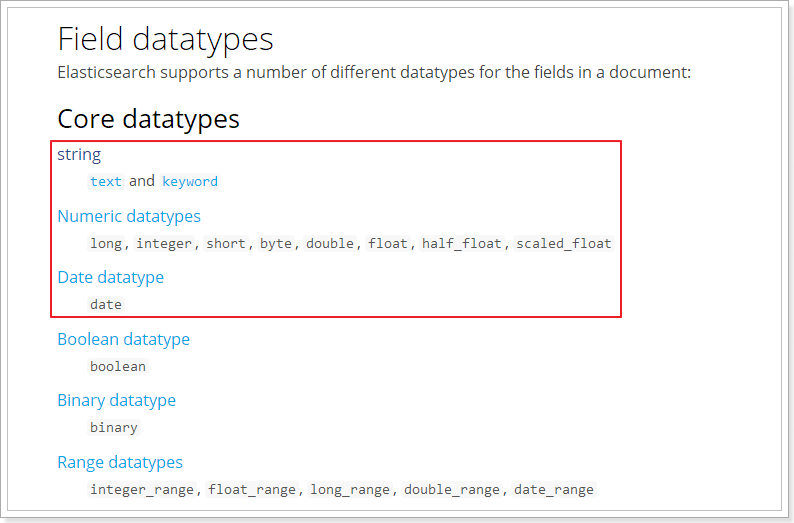
常用的说明下:
String类型,分为两种: text:可分词,不可参与聚合 keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
Numerical:数值类型,分两类 基本数据类型:long、integer、short、byte、double、float、half_float 浮点数的高精度类型:scaled_float 需要指定一个精度因子,比如10或100。Elasticsearch会把真实值乘以这个因子以后存储,取出时再还原。
Date:日期类型 Elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
3.2 index
index影响字段的索引情况
true:字段会被索引,则可以用来进行搜索。默认值是 truefalse:字段不会被索引,不能用来搜索
特别说明:
index的默认值就是
true,也就是说你不进行任何配置,所有字段都会被索引。但是有些字段我们不希望索引的,就需要手动设置index为false
3.3 store
是否将数据额外存储
在lucene和solr中,我们设置store字段为false,那么这个字段在文档列表中就不会有这个字段的值,用户搜索结果中就不会显示出来。
但在Elasticsearch中,即便设置为false,也可以搜索结果。
原因是Elasticsearch在创建文档索引库时,会将文档中的原始数据备份,保存到一个叫_source的属性中,而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在_source以外额外存储一份数据,多余,因此我们一般都会讲store设置为false,事实上,store的默认是就是false。
2.1.3 新增数据
1.随机生成id
通过POST请求,可以向一个已经存在的索引库中添加数据
语法:
POST /索引库名/_doc/类型名
{
"key": "value"
}
示例:
POST /ceshi/_doc/goods
{
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2688.01
}
运行结果:

查看新增数据结果
GET /ceshi/_search
{
"query":{
"match_all":{}
}
}
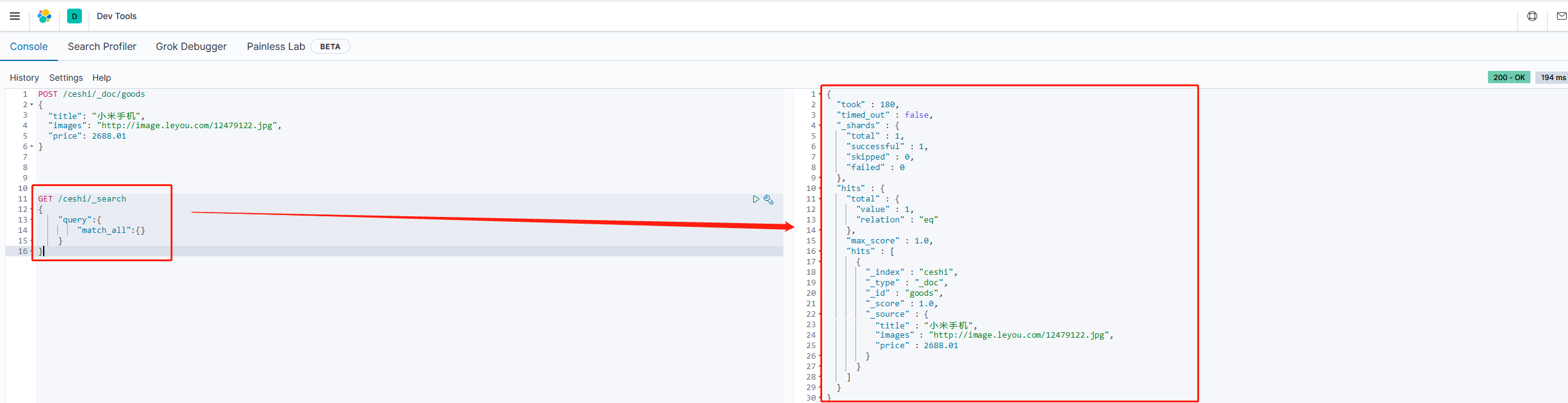
_source:源文档信息,所有数据都在里面 _id:这条文档的唯一标识,与文档自己的id没有关联
2.自定义id
如果我们在新增数据的时候指定id,可以按如下操作:
语法:
POST /索引库名/_doc/id
{
"key": "value"
}
示例:
POST /ceshi/_doc/2
{
"title": "小米手机",
"images": "http://image.leyou.com/12479122.jpg",
"price": 2988.02
}
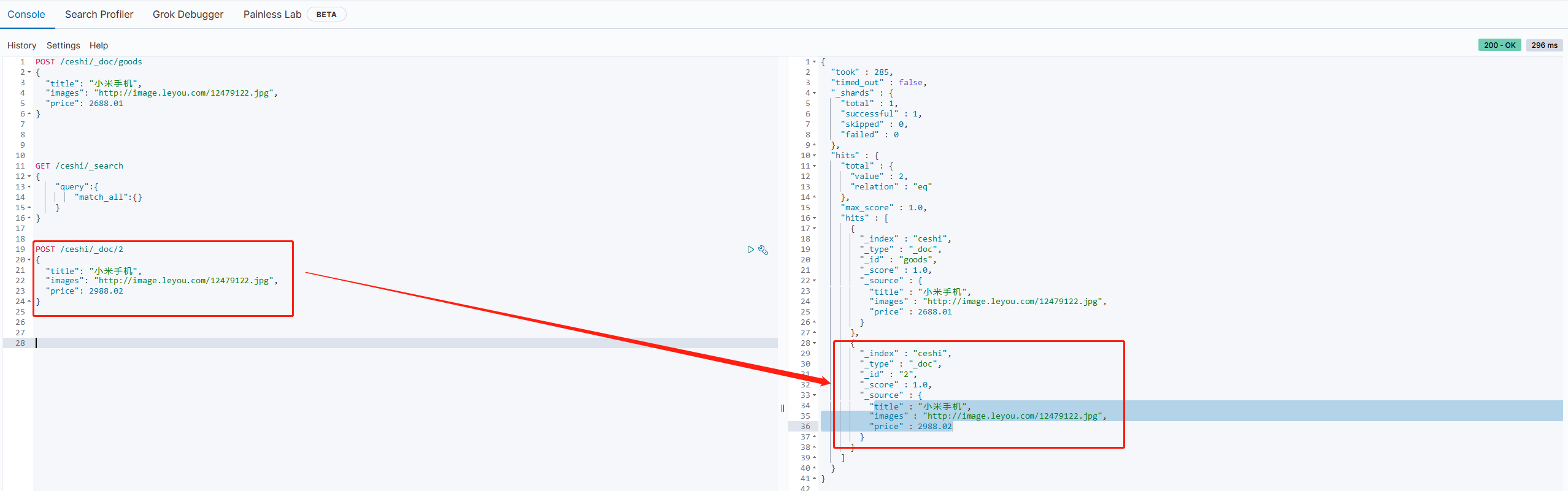
2.1.4 智能判断
在学习solr时,我们在新增数据时,智能使用提前批配置好映射属性的字段,否则就会报错
不过在Elasticsearch中,可以不需要给索引库设置任何的映射属性的字段,它也可以根据输入的数据来判断类型,动态添加数据映射
示例:
POST /ceshi/_doc/3
{
"title":"超米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":2899.00,
"stock": 200,
"saleable":true
}
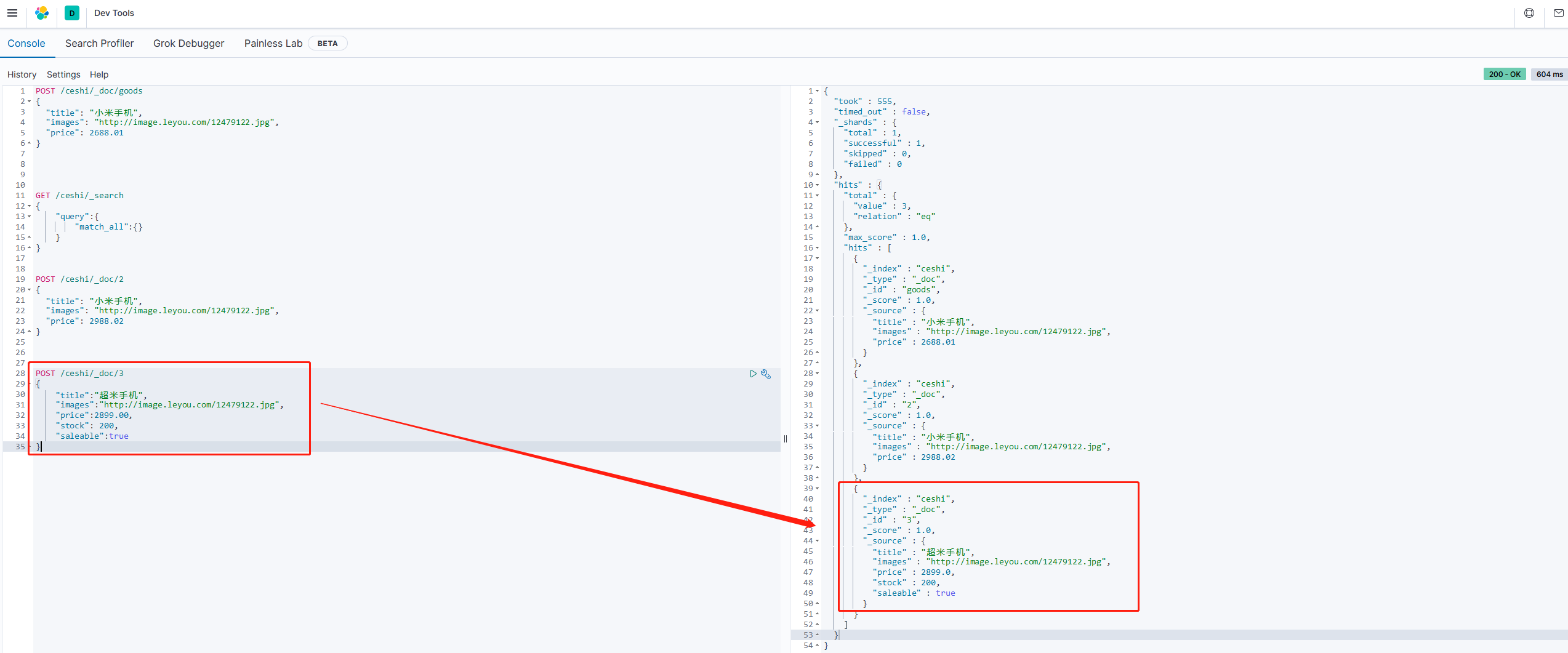
我们发现,ceshi索引库额外增加了stock库存和saleable是否上架两个字段。
查看此时的索引库映射关系
GET ceshi/_mapping
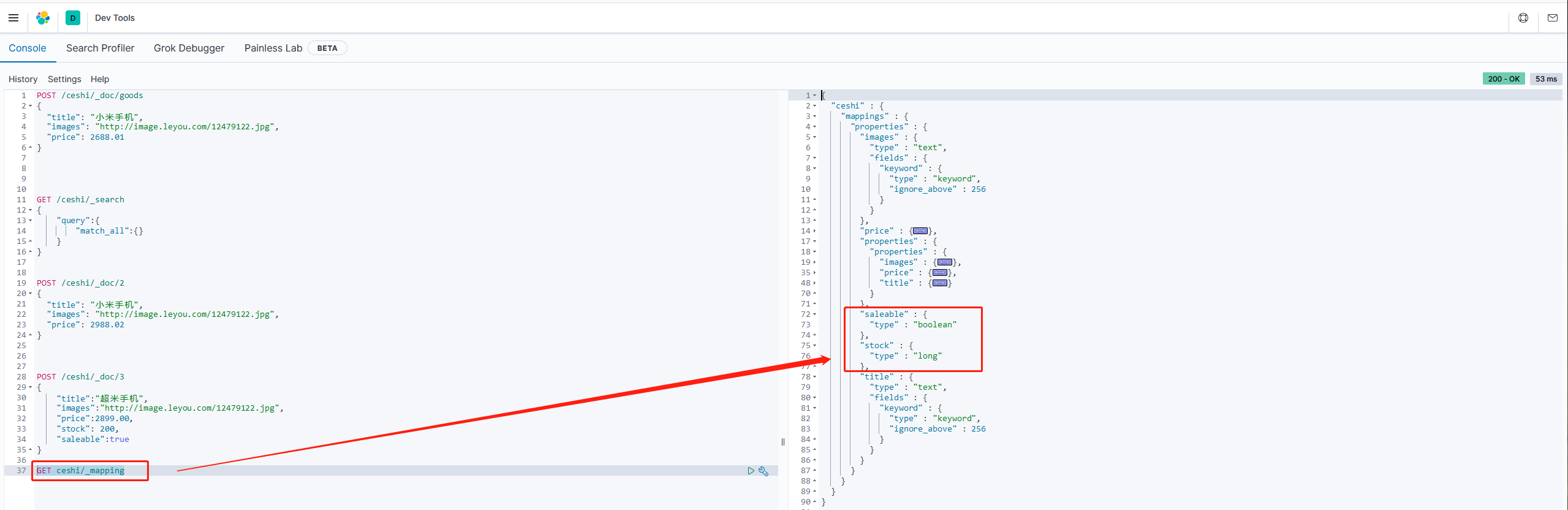
2.1.5 修改数据
把刚才新增请求的方式改为PUT,就是修改了,不过修改必须指定id
id对应文档存在,则修改 id对应文档不存在,则新增
比如,我们把id为3的数据进行修改:
PUT /ceshi/_doc/3
{
"title":"超大米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":3899.00,
"stock": 100,
"saleable":true
}
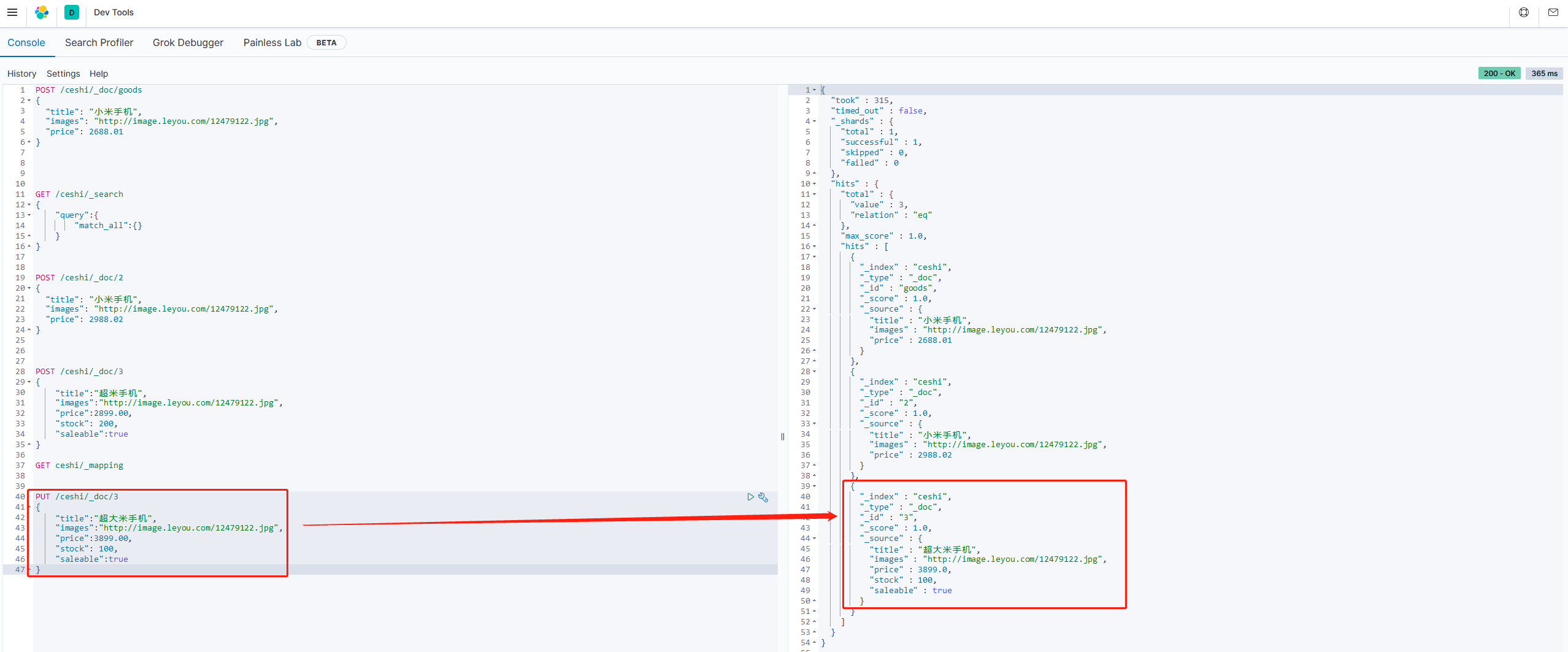
2.1.6 删除数据
删除数据使用DELETE请求方式,同样,根据id进行删除
语法:
DELETE /索引库名/_doc/id
示例:
DELETE /ceshi/_doc/1
结果:删除id为1的索引库数据
2.1.7 查询数据
基本查询 _source过滤 结果过滤 高级查询 排序
1.基本查询
基本语法
GET /索引库名/_search
{
"query": {
"查询类型": {
"查询条件": "查询条件值"
}
}
}
query:表示一个查询对象,里面可以有不同的查询属性
查询类型:如,
mastch_all、match、term、range等查询条件:
查询条件会根据类型的不同,写法也有差异,后面详细讲解
2.查询所有(match_all)
GET /ceshi/_search
{
"query": {
"match_all": {}
}
}
query:代表查询对象 match_all:代表查询所有
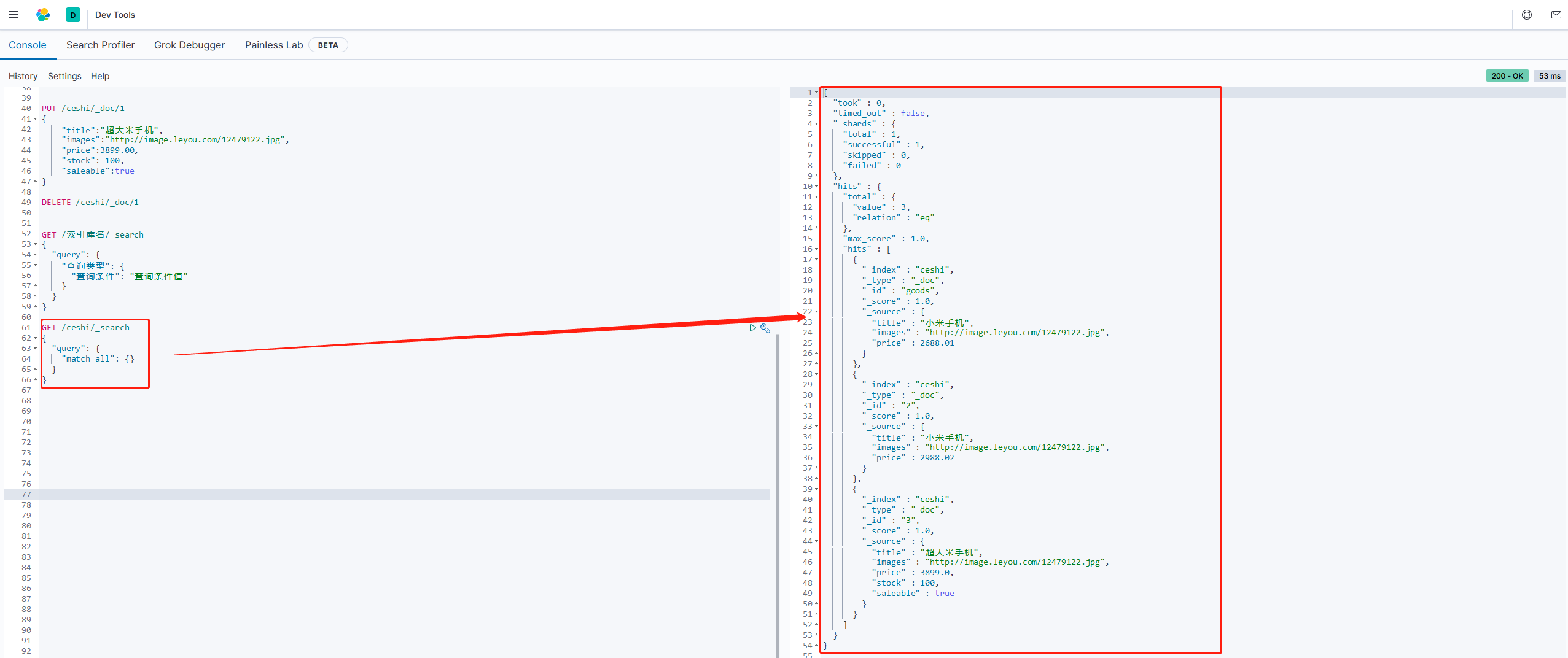
took:查询花费时间,单位是毫秒 time_out:是否超时 _shards:分片信息 hits:搜索结果总览对象
total:搜索到的总条数 max_score:所有结果中文档得分的最高分 hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
_index:索引库 _type:文档类型 _id:文档id _score:文档得分 _source:文档的源数据
3.匹配查询(match)
先增加一条数据,便于测试
PUT /ceshi/_doc/1
{
"title":"小米电视4A",
"images":"http://image.leyou.com/12479122.jpg",
"price":1899.00
}
特别说明:增加数据使用
POST和PUT的区别
PUT:需要指定id,否则会报错,幂等操作 POST:指定的id存在,则更新数据,不存在要么自定义id,要么随机生成,非幂等操作
从结果中看到,索引库中有2部手机,1台电视
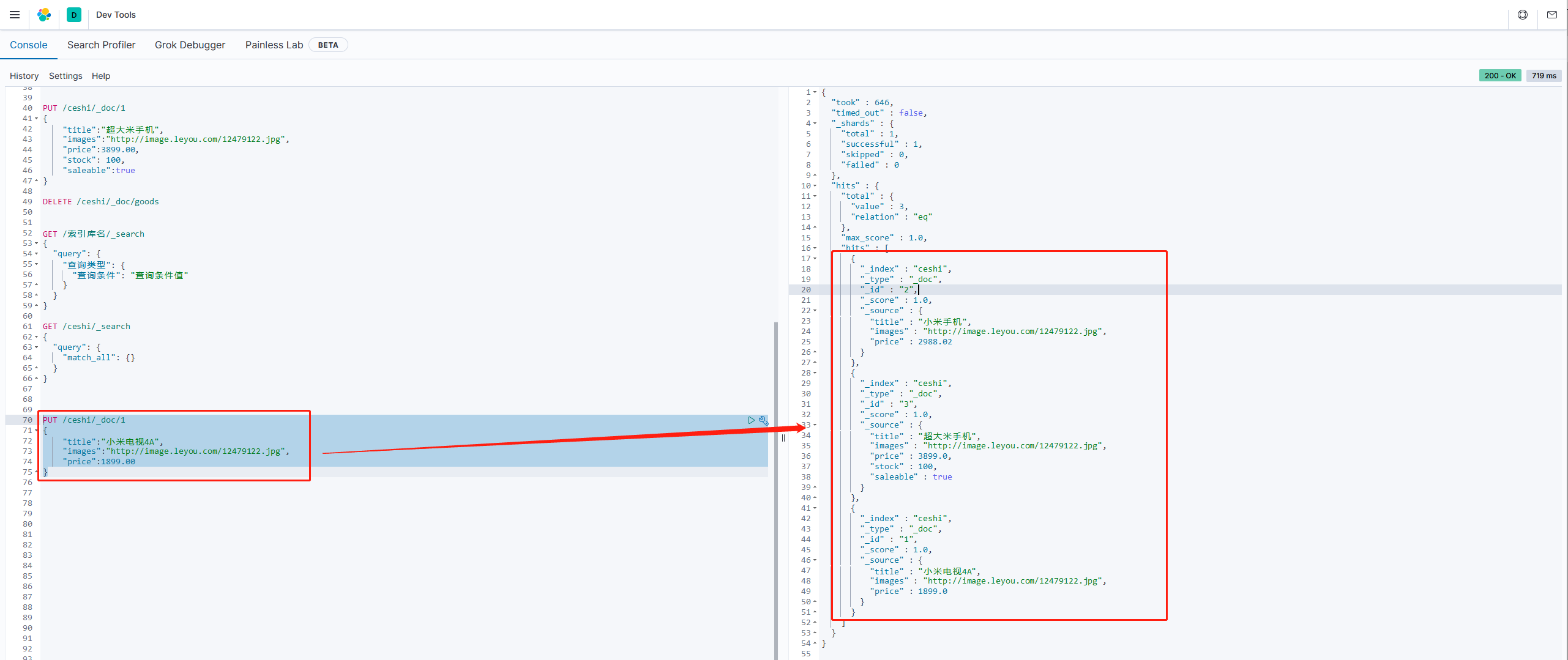
or关系
match类型查询,会把查询条件进行分词。然后进行查询,多个词条之间是or的关系
GET /ceshi/_search
{
"query": {
"match": {
"title": "小米电视"
}
}
}
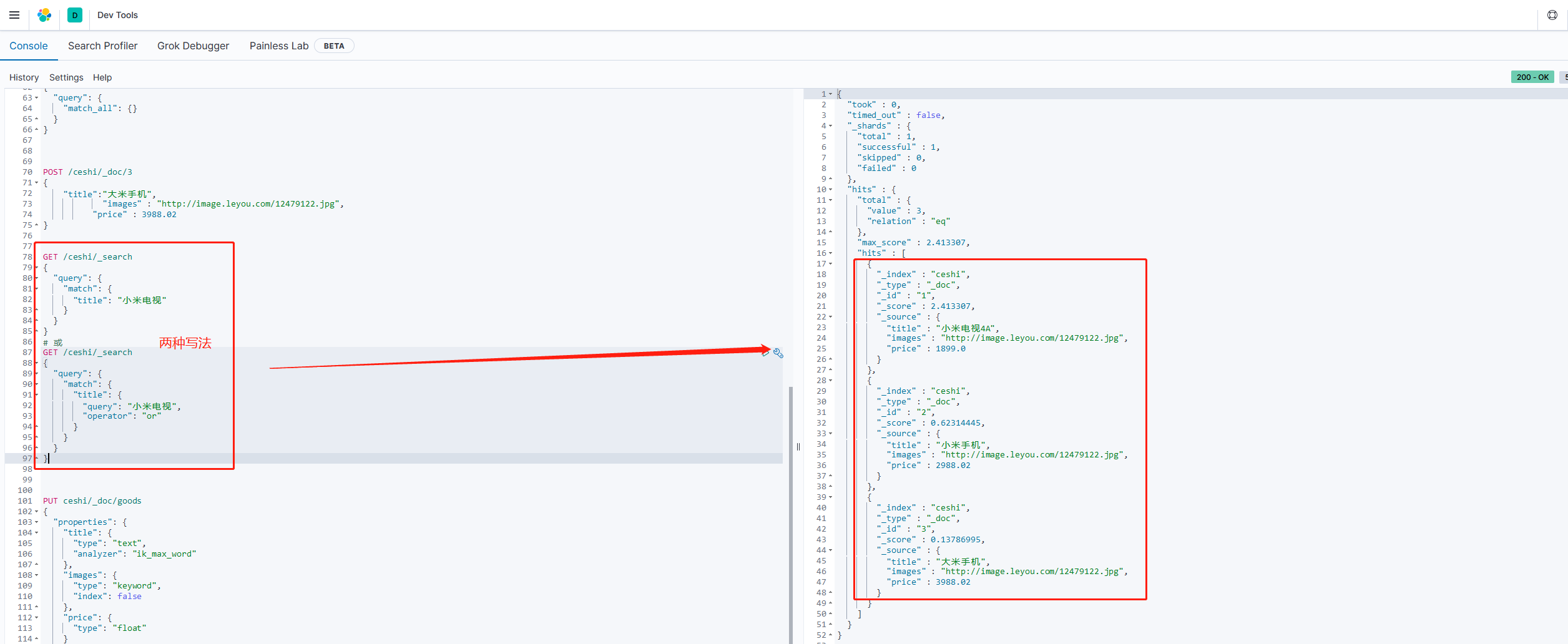
默认情况下,是会通过分词,使多个词之间是or的关系。
and关系
某些时候需要精确查找,需要将多个词关系设置为and。
GET /ceshi/_search
{
"query": {
"match": {
"title": {
"query": "小米电视",
"operator": "and"
}
}
}
}
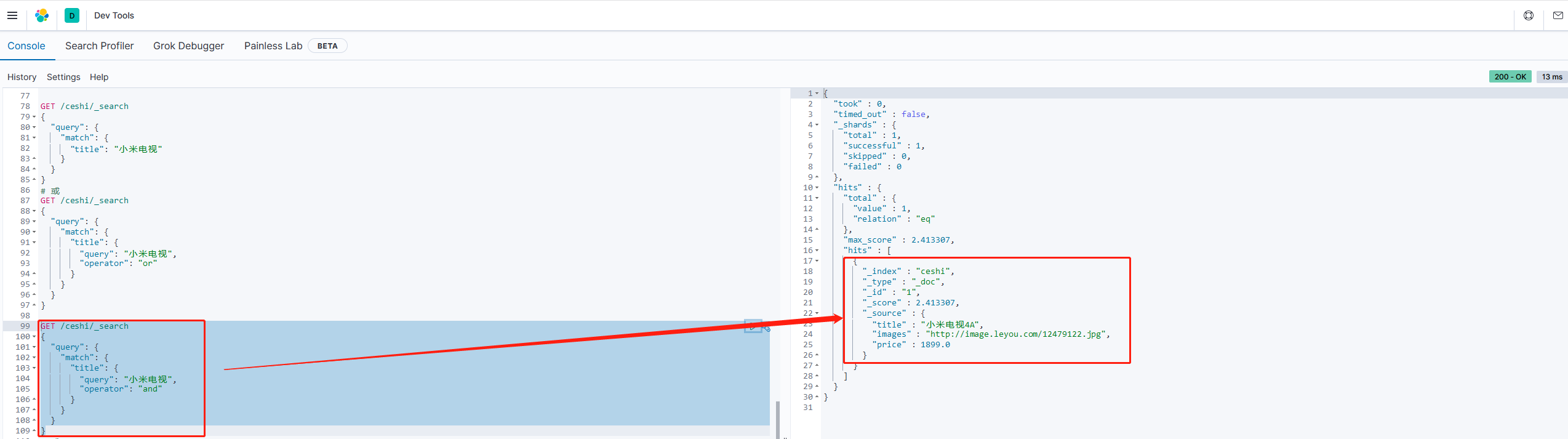
本例中,只有同时包含
小米和电视的词条才会被搜索到
or and and 之间
场景:如果用户给定的条件分词后有5个查询词项,想查找只包含其中4个词的文档,该如何处理?将operator操作符设置成and只会将此文档排除。
有时候这正是我们期望的,但在全文搜索的大多数应用场景下,我们既想包含那些可能相关的文档,同时又排除那些不太相关的。换句话说,我们想要处于中间某种结果。
match查询支持minimum_should_match最小匹配参数,这让我们可以指定匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量。
示例:
GET /ceshi/_search
{
"query": {
"match": {
"title": {
"query": "小米曲面电视",
"minimum_should_match": "75%"
}
}
}
}
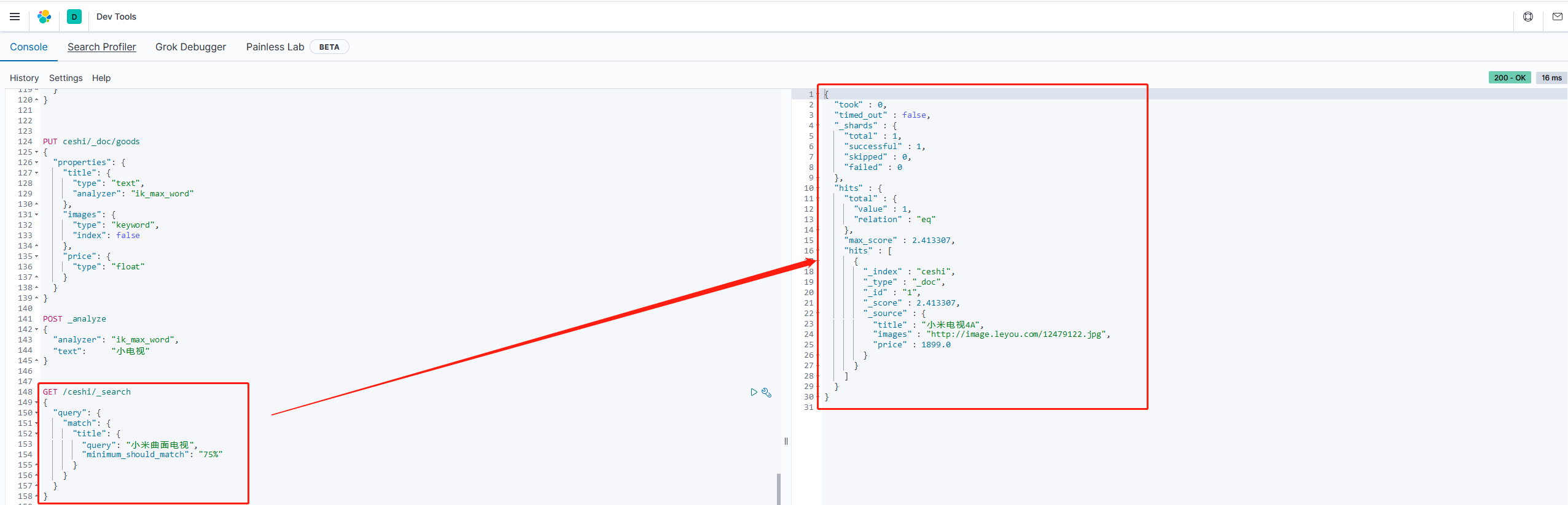
多字段查询(multi_match)
match和multi_match类似,不同的是multi_match可以在多个字段中查询
示例:
GET /ceshi/_search
{
"query":{
"multi_match": {
"query": "小",
"fields": [ "title", "subTitle" ]
}
}
}
词条匹配(term)
term查询被用于精确值匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串
示例:
GET /ceshi/_search
{
"query": {
"term": {
"price": "1899"
}
}
}
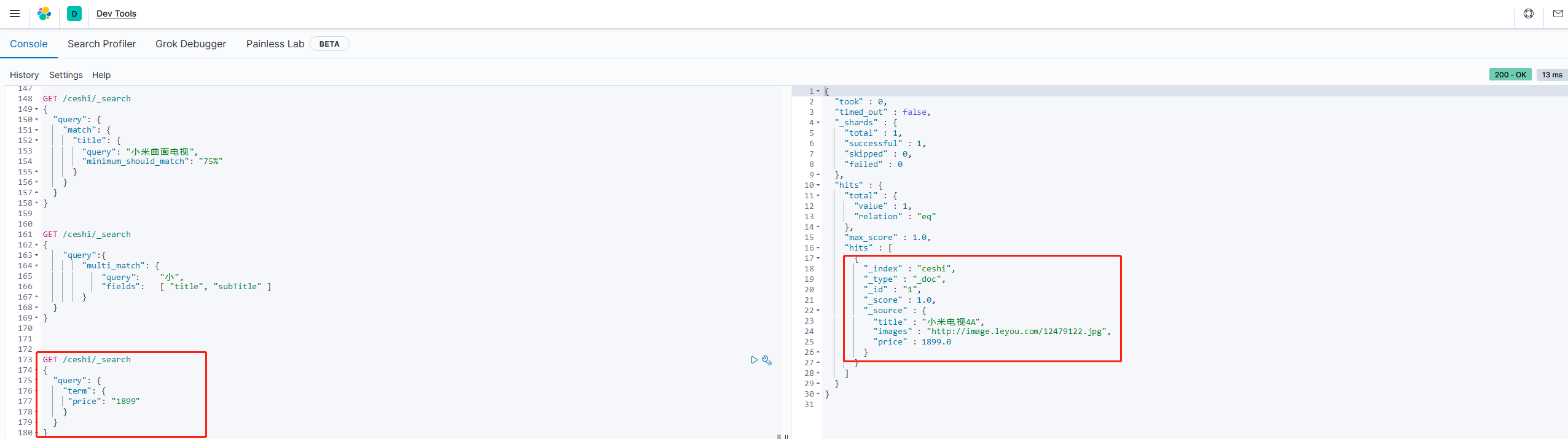
多词条精确匹配(terms)
terms查询和term查询一样,但它允许你指定多值进行匹配。如果这个字段中包含了指定值中的任何一个值,那么这个文档满足条件:
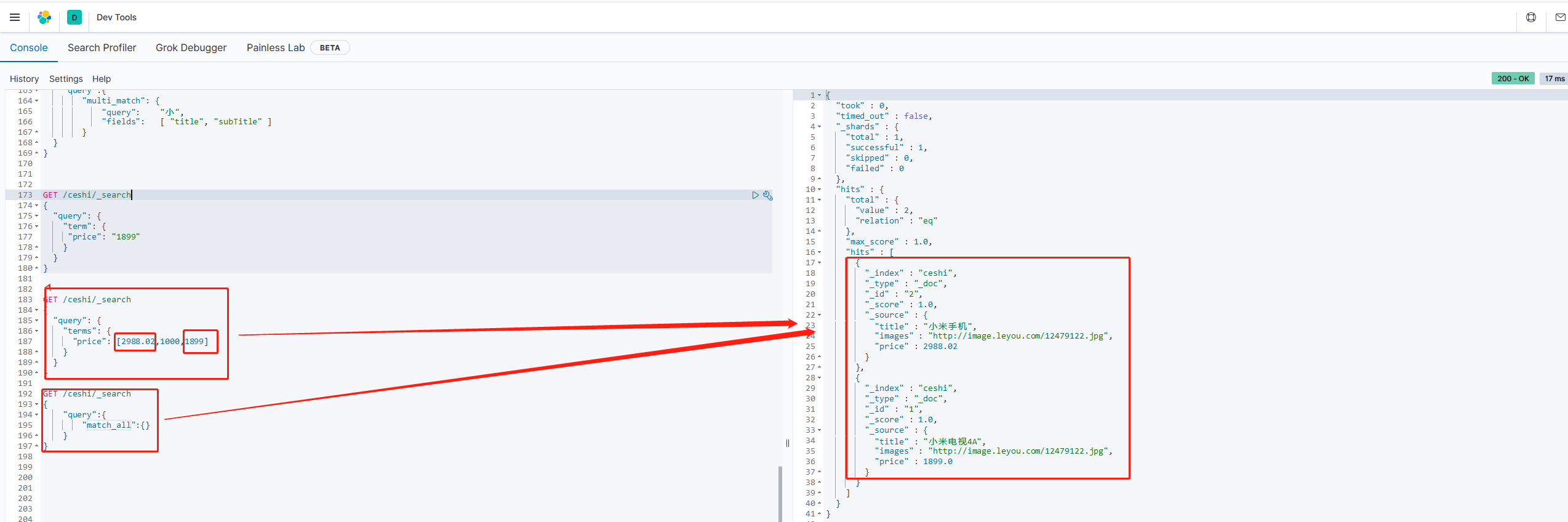
结果过滤
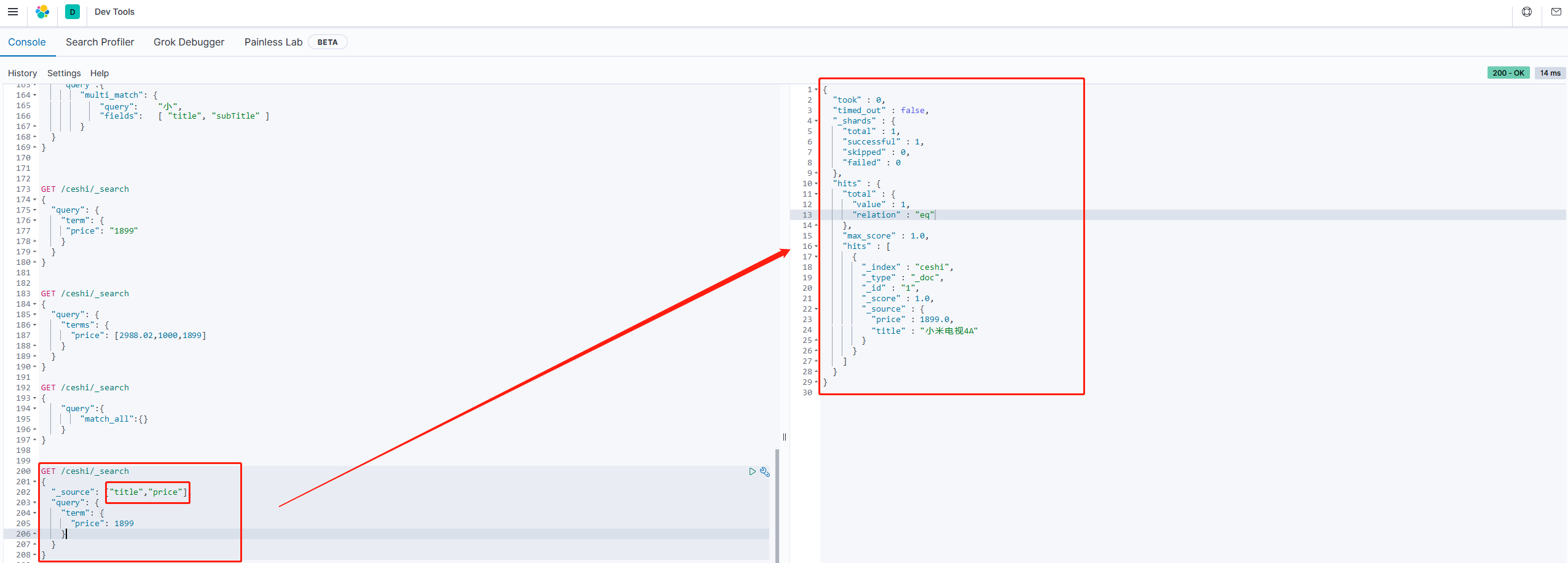
默认情况下,elasticsearch在搜索结果中,会把文档中保存在
_source的所有字段返回。但是,如果我们只想要获取其中的部分字段,我们可以添加_source的过滤。
直接指定字段
示例:
GET /ceshi/_search
{
"_source": ["title","price"],
"query": {
"term": {
"price": 1899
}
}
}![]() 2. 指定includes和excludes
2. 指定includes和excludes我们也可以通过“
includes:来指定想要显示的字段 excludes:来指定不想要显示的字段
示例:
GET /ceshi/_search
{
"_source": {
"includes": ["title","images"]
},
"query": {
"term": {
"price": 1899
}
}
}
GET /ceshi/_search
{
"_source": {
"excludes": ["title","images"]
},
"query": {
"term": {
"price": 1899
}
}
}![]()
 2. 指定includes和excludes
2. 指定includes和excludes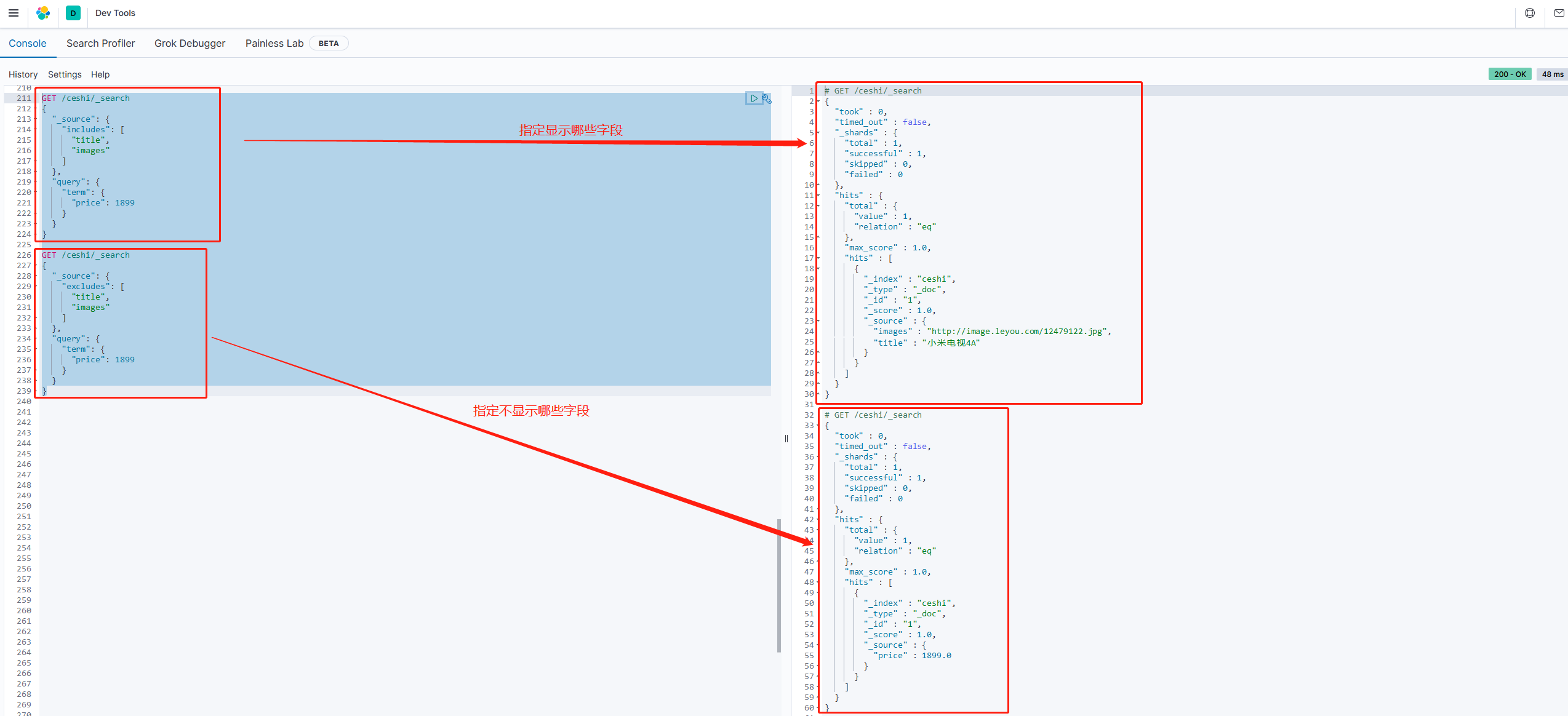
2.18 高级查询
1.布尔组合(bool)
bool把各种其他查询通过must(与)、must_not(非)、shoud(或)的当时组合
示例
# 查询title可能包含“大米”,但一定包含“手机”的数据
GET /ceshi/_search
{
"query": {
"bool": {
"must": {"match":{"title":"大米"}},
"must_not":{"match":{"title":"电视"}},
"should":{"match":{"title":"手机"}}
}
}
}
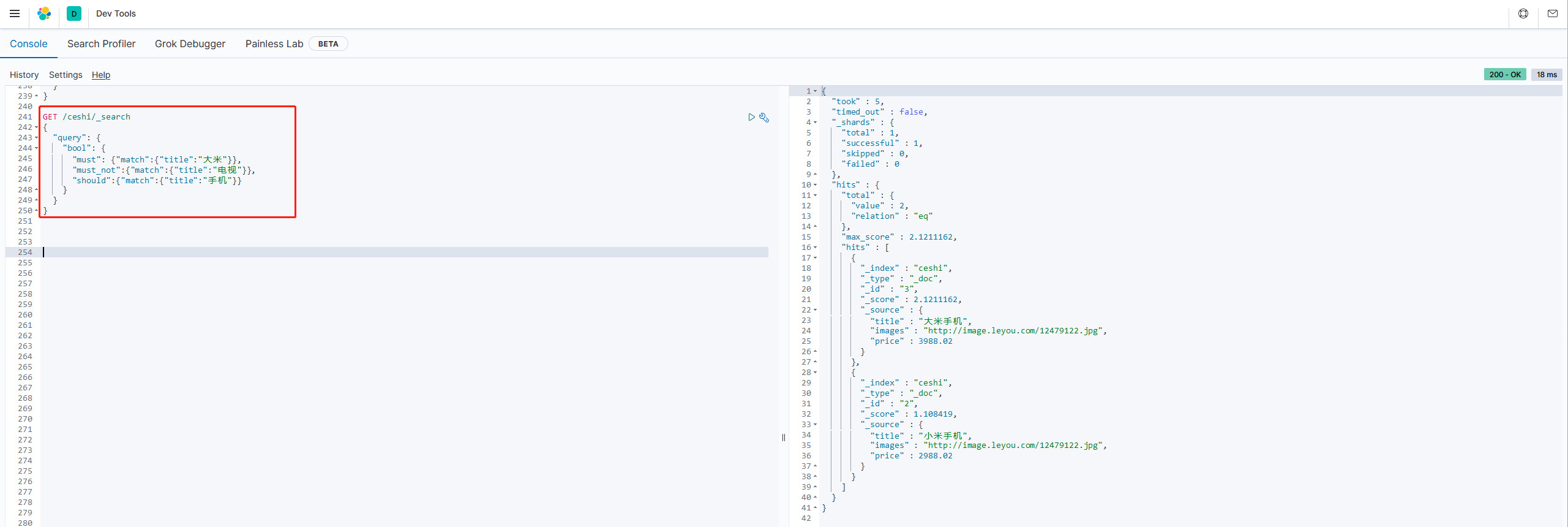
2.范围查询(range)
range查询找出那些落在指定区间内的数字或时间
示例
# 查询price在1000-2900范围内的数据
GET /ceshi/_search
{
"query": {
"range": {
"price": {
"gte": 1000,
"lte": 2900
}
}
}
}
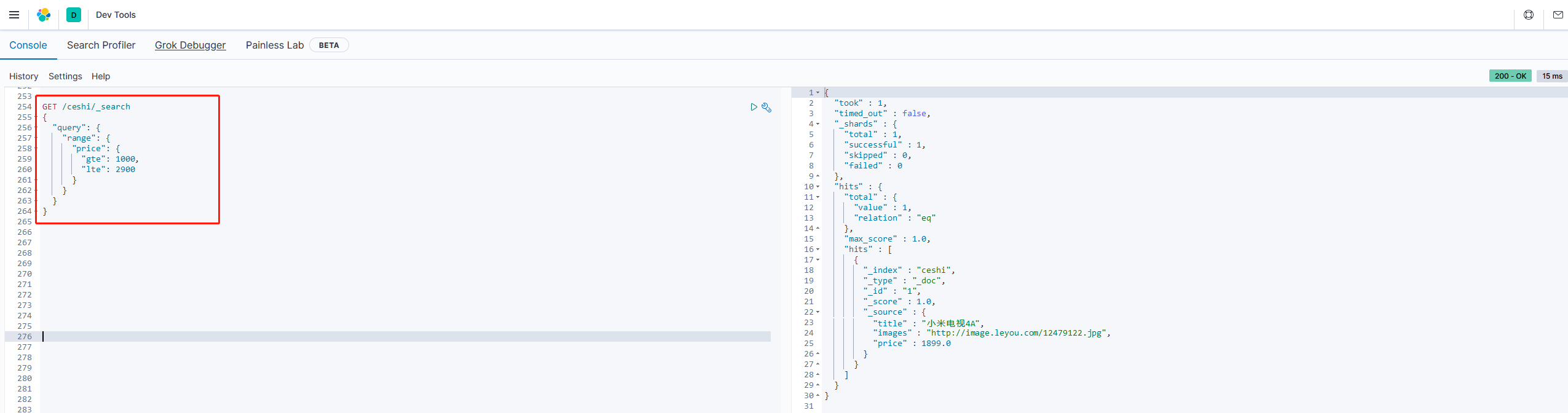
range查询允许以下字符:
| 操作符 | 说明 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
3.模糊查询(fuzzy)
新增一条数据
POST /ceshi/_doc/4
{
"title":"apple手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":6899.00
}
fuzzy查询时term查询的模糊等价。它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的编辑距离不得超过2
POST /ceshi/_doc/4
{
"title":"apple手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":6899.00
}
上面查询也是可以查到apple手机数据的
我们可以通过fuzziness属性来指定允许的偏差距离:
GET /ceshi/_search
{
"query": {
"fuzzy": {
"title": {
"value": "appaa",
"fuzziness": 3
}
}
}
}
也是可以查到数据
注意:
fuzzinexx值越大,偏差距离也越大,模糊查询的范围也越大,反之。
4.过滤(filter)
条件查询找那个进行过滤
所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要吧过滤条件作为查询条件来用。而是使用filter方式:
GET /ceshi/_search
{
"query": {
"bool": {
"must":{"match":{"title":"手机"}},
"filter": {
"range": {
"price": {
"gte": 1000,
"lte": 5000
}
}
}
}
}
}
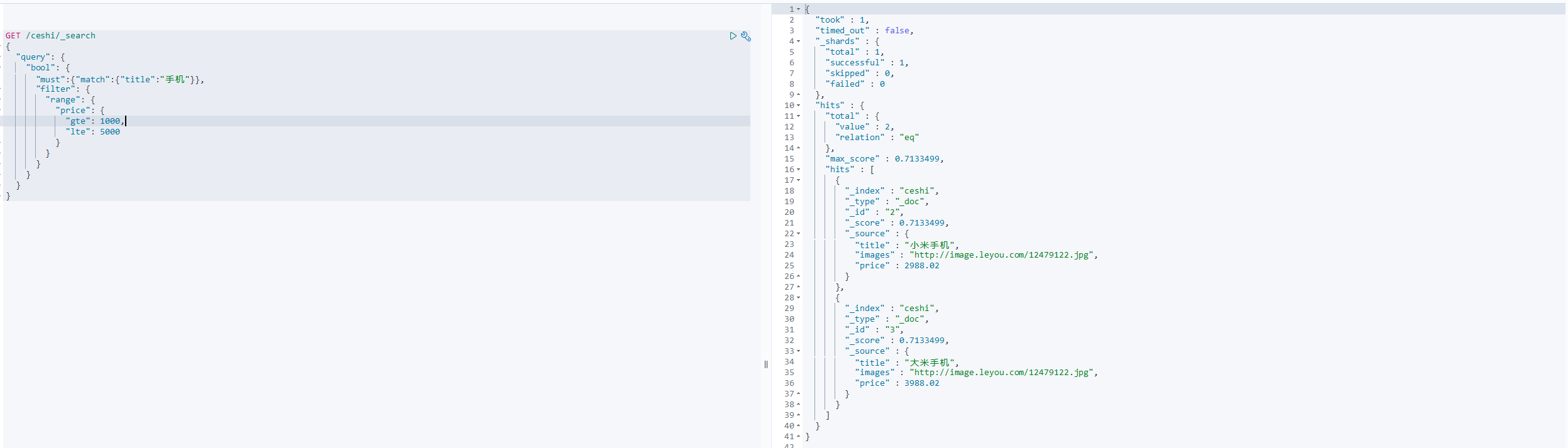
注意:
filet中还可以再次进行bool组合条件过滤
无查询条件,直接过滤
如果一个查询只有过滤,没有查询条件,不希望进行评分,我们可以使用constant_score取代只有filter语句的bool查询。在性能上时完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
示例:
GET /ceshi/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 1000,
"lte": 4000
}
}
}
}
}
}
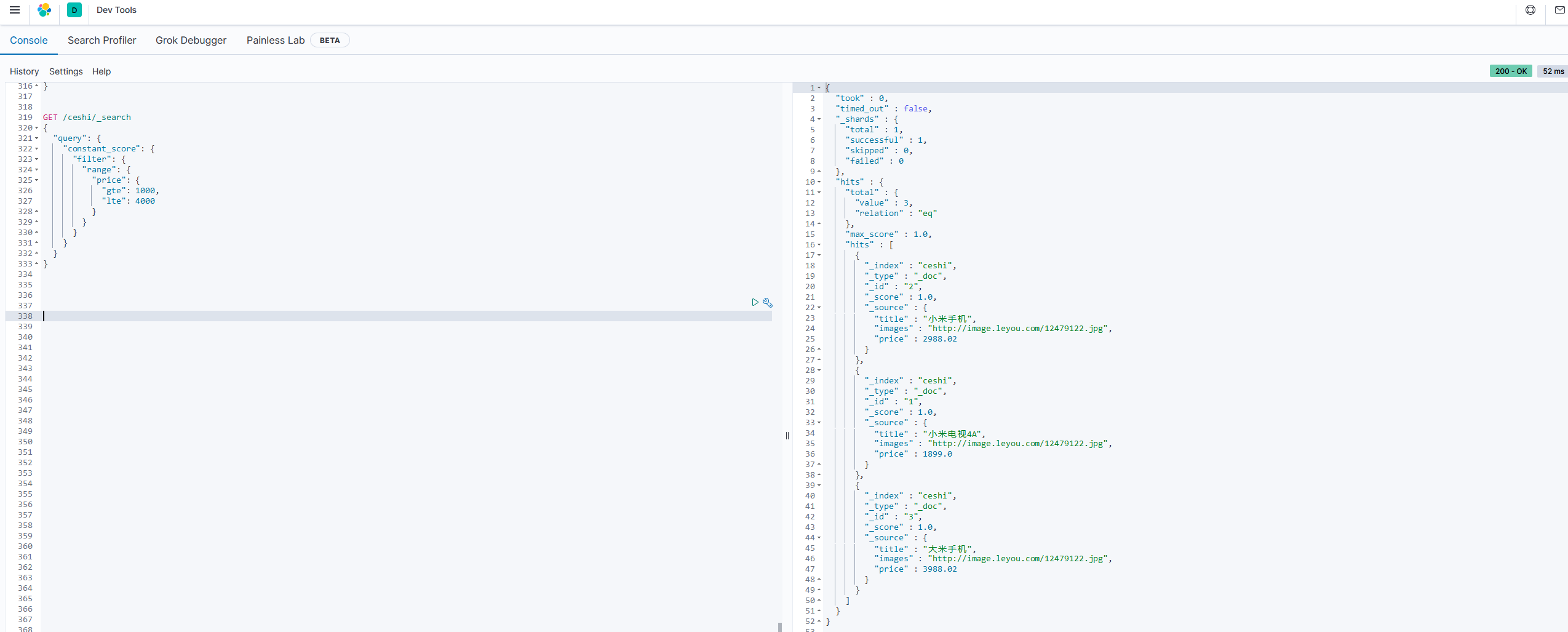
5.排序
需求:想要将查询条件title和price范围过滤出来结果,进行首先按照价格排序,然后按照得分排序:
GET /ceshi/_search
{
"query": {
"bool": {
"must":{"match":{"title":"手机"}},
"filter":{
"range": {
"price": {
"gte": 1000,
"lte": 7000
}
}
}
}
},
"sort": [
{"price": {"order": "desc"}},
{"_score": {"order": "desc"}}
]
}
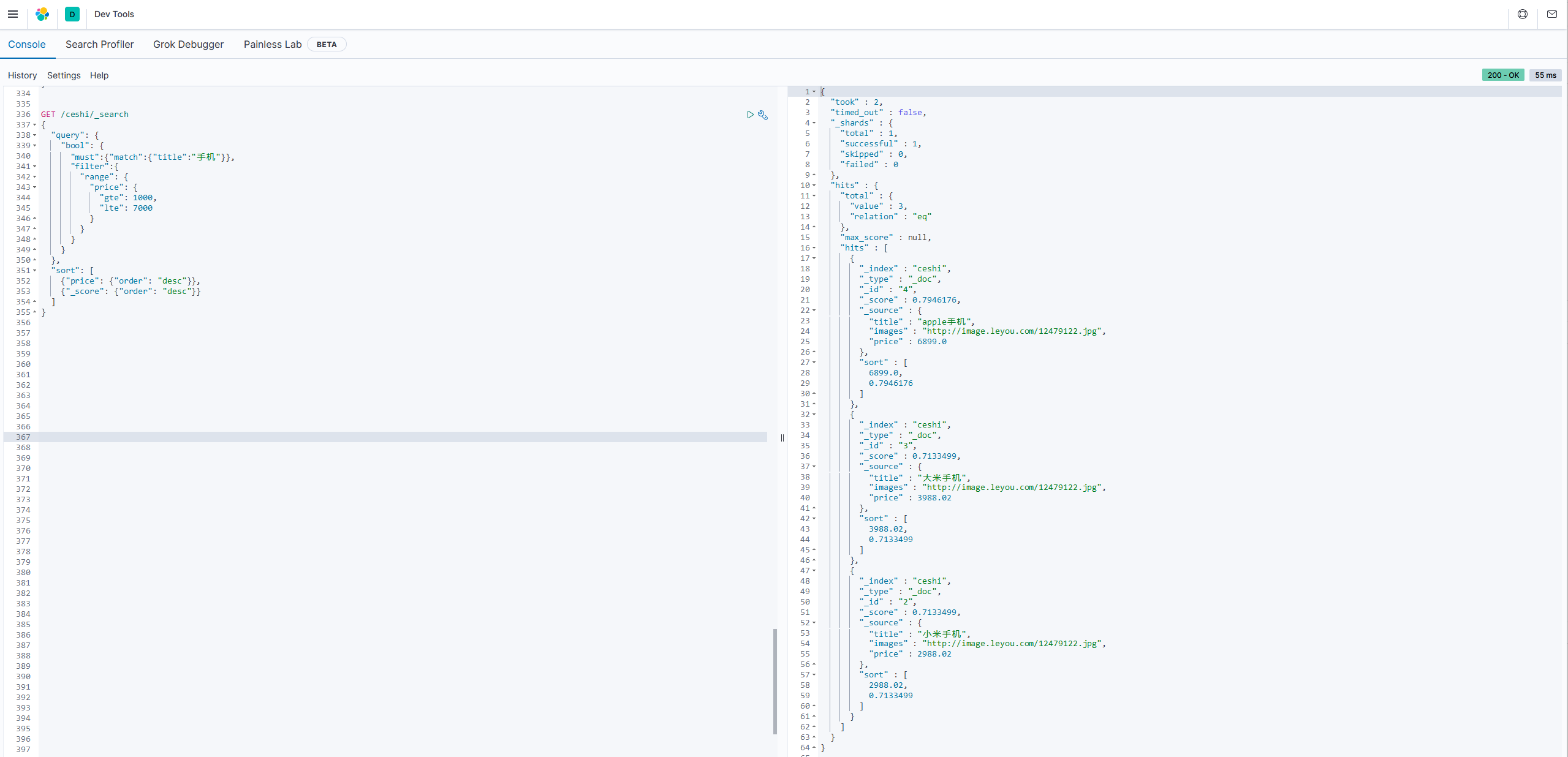
2.3聚合aggregations
聚合可以让我们及其方便的实现对数据的统计、分析。例如:
什么品牌的手机最受欢迎 这些手机的平均价格、最高价格、最低价格 这些手机每月的销售情况如何
实现这些统计功能要比数据库的sql方便的多,而且查询速度非常快,可以实现实时搜索效果。
2.3.1 基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种:
桶 度量
1.桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶。例如,我们根据国籍对人划分,可以得到中国桶、英国桶、美国桶。。。
Elasticsearch中提供的划分桶的方式很多:
Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分一组 Histogram Aggregation:根据数值阶梯分组,与日期类似 Terms Aggregation:根据词条内容分组,词条内容完全匹配分为一组 Range Aggregation:数值和日期的范围分组,指定开始和结束,然后分段分组 。。。
综上所述,我们发现bucket aggregations只负责对数据进行分组,并不进行计算,因此bucket中往往会嵌套另一种聚合:metrics aggregations 即度量。
2.度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等操作。这些在ES中称为度量。
比较常用的一些度量聚合方式:
Avg Aggregation:求平均值 Max Aggregation:求最大值 MIn Aggregation:求最小值 Percentiles Aggregation:求百分比 Stats Aggregation:同时返回avg、max、min、sum、count等 Sum Aggregation:求和 Top hits Aggregation:求前几 Value Count Aggregation:求总数 。。。
开始测试
为了方便测试,我们首先批量导入测试数据
2.3.2 创建索引库
PUT /cars
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties":{
"color":{"type":"keyword"},
"make":{"type":"keyword"}
}
}
}
查看索引库映射关系:GET /cars/_mapping
注意:在ES中,需要进行聚合、排序、过滤的字段其处理方式比较特殊,因此不能被分词。这里我们将color和make这两个字段类型设置为keyword类型,这个类型不会被分词,将来就可以参与聚合
导入数据:
POST /cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
查看cars索引库中的数据:
GET /cars/_search
{
"query": {
"match_all": {}
}
}
2.3.3 聚合为桶
1.按照cars中的color字段来划分桶
GET /cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}
size:查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率 aggs:声明这是一个聚合查询,是aggregations的缩写
popular_color:给这次聚合起一个名字,任意。
terms:划分桶的方式,这里是根据词条划分
field:划分桶的字段
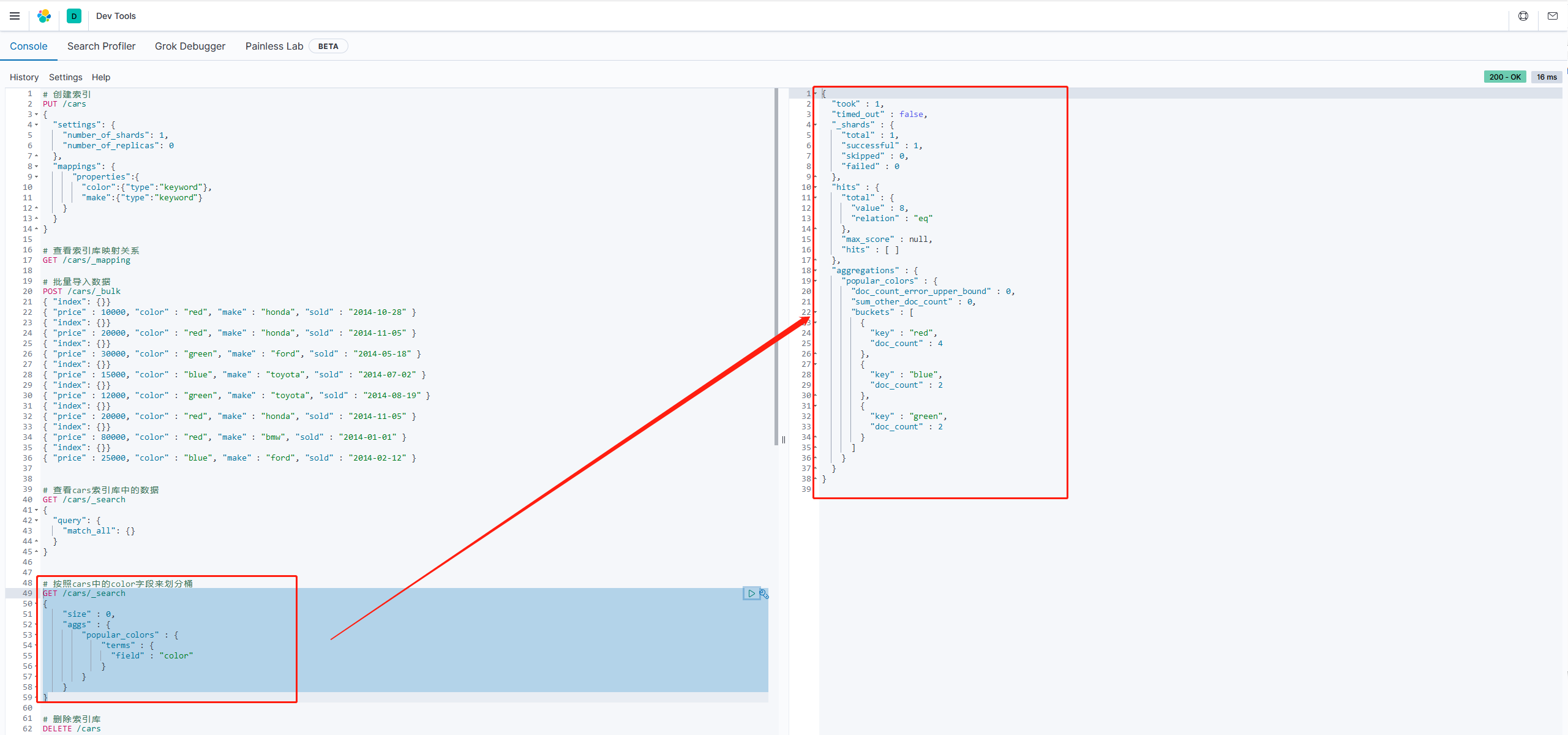
hits:查询结果为空,因为我们设置了size为0 aggregations:聚合的结果
popular_clor:我们定义的聚合名称
buckets:查找到的桶,每个不同的color字段值都会形成一个桶
key:这个桶对应的color字段的值 doc_count:这个桶中的文档数量 总结:通过聚合的结果我们发现,目前红色的小车比较畅销
2.3.4 桶内度量
前面的例子告诉我们每个桶里面的文档数量。但通常,我们的应用需要提供更为复杂的文档度量。例如,每种颜色骑车的平均价格是多少?
因此,我们需要告诉Elasticsearch使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在==桶内==,度量的运算会基于==桶内==的文档进行。
示例:
需求:按照cars中的color字段划分桶,并求相应每个桶中的平均价格
GET /cars/_search
{
"size": 0,
"aggs": {
"popular_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
arrgs:我们在aggs(popular_color)中添加新的aggs。可见==度量也是一个聚合,度量是在桶中的聚合==。 avg_price:度量聚合的名称,任意 avg:度量的类型,这里是求平均值 field:度量运算的字段
结果:
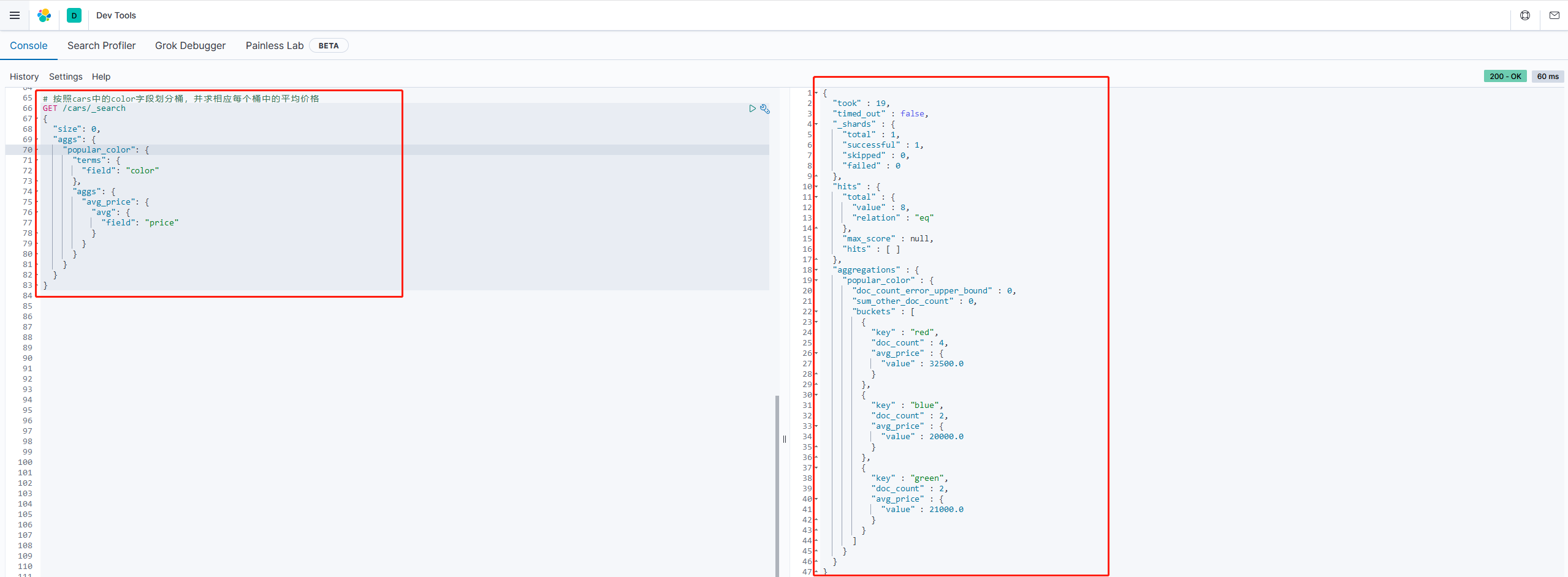
我们可以看到每个桶中都有自己的avg_price字段,这就是度量聚合的结果
2.3.5 桶内嵌套桶
上面示例是桶内嵌套度量运算。事实上桶内不仅可以嵌套运算,还可以嵌套其他桶。也就是说在每个分组中,可以再分更多桶。
示例:
需求:我们想要统计每种颜色的汽车中,分别属于哪个制造商,按照make字段在进行分桶
GET /cars/_search
{
"size": 0,
"aggs": {
"popular_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"maker":{
"terms": {
"field": "make"
}
}
}
}
}
}
结果:
{
"took" : 14,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_color" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4,
"maker" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "honda",
"doc_count" : 3
},
{
"key" : "bmw",
"doc_count" : 1
}
]
},
"avg_price" : {
"value" : 32500.0
}
},
{
"key" : "blue",
"doc_count" : 2,
"maker" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "ford",
"doc_count" : 1
},
{
"key" : "toyota",
"doc_count" : 1
}
]
},
"avg_price" : {
"value" : 20000.0
}
},
{
"key" : "green",
"doc_count" : 2,
"maker" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "ford",
"doc_count" : 1
},
{
"key" : "toyota",
"doc_count" : 1
}
]
},
"avg_price" : {
"value" : 21000.0
}
}
]
}
}
}
我们可以看到,新的聚合maker被嵌套在原来每一个color的桶中。 每个颜色下面都根据make字段进行了分组 我们从结果中读到的信息:
红色车共有4辆 红色车的平均售价32500 其中3辆是Honda本田制造,1辆是BMW宝马制造
2.3.6 阶梯分桶(Histogram)
histogram是把数值类型的字段,按照一定的阶梯大小进行分组。需要指定一个阶梯值(interval)来划分阶梯大小
示例
需求:比如你有价格字段,如果你设定interval的值为200.那么阶梯就会是这样的:
0,200,400,600,。。。
上面列出的是每个阶梯的key,也是区间的起点
如果一件商品的价格是450,会落在哪个阶梯区间呢?计算公式如下:
bucket_key = Math.floor((value-offset)/interval)*interval+offset
value:就是当前数据的值,本例中是450 offset:起始偏移值,默认为0 interval:阶梯间隔,比如200 因此得到的key=Math.floor((450-0)/200)*200+0=400
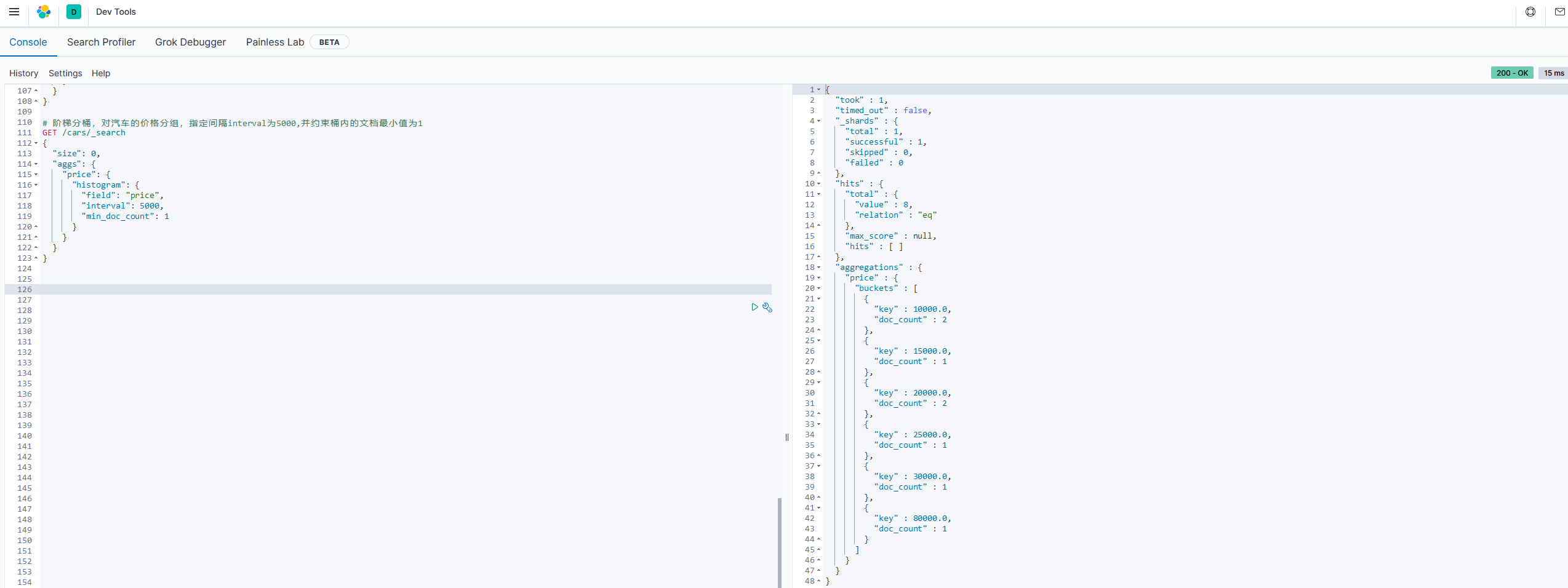
我们对汽车的价格进行分组,指定间隔interval为5000:
# 阶梯分桶,对汽车的价格分组,指定间隔interval为5000,并约束桶内的文档最小值为1
GET /cars/_search
{
"size": 0,
"aggs": {
"price": {
"histogram": {
"field": "price",
"interval": 5000,
"min_doc_count": 1
}
}
}
}
2.3.7 范围分桶(range)
范围分桶和阶梯分桶类似,也是把数字按照阶段进行分组,只不过range方式需要你自己指定每一组的起始和结束大小
2.4 Spring Data Elaticsearch
Elasticsearch提供的java客户端有一些不太方便的地方:
很多地方需要在java中拼接json字符串 需要自己把对象序列化为json存储 查询到结果也需要自己反序列化为对象 因此,我们可以学习Spring提供的套件:Spring Data Elaticsearch
2.4.1 简介
Spring Data Elaticsearch是Spring Data项目下的一个子模块
Spring Data官网:http://projects.spring.io/spring-data/
Spring Data的使命是给各种数据访问提供统一的编程接口,不管是关系型数据库(mysql),还是非关系型数据库(redis),或者类似Elaticsearch索引数据库。
Spring Data Elaticsearch的页面:https://projects.spring.io/spring-data-elasticsearch/
特征:
支持Spring的基于 @configuration的java配置方式,或者XML配置方式提供了用于操作ES的便捷工具类 ElaticsearchTemplate。包括实现文档到POJO之间的自动智能映射利用Spring的数据转换服务实现的功能丰富的对象映射 基于注解的元数据映射方式,而且可扩展以支持更多不同的数据格式 根据持久层接口自动生成对象实现方法,无需人工编写基本操作代码(类似mybatis,根据接口自动得到实现,也支持人工定制查询)
2.4.2 项目实战
1.创建一个项目,导入如下pom依赖:
<!-- high client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${es.version}</version>
</dependency>
<!-- rest-high-level-client 依赖如下两个jar -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${es.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${es.version}</version>
</dependency>
2.application.yml配置
es:
host: 192.168.15.100
port: 9200
scheme: http
3.es配置类
@Configuration
public class ElaticsearchConfig {
@Value("${es.host}")
public String host;
@Value("${es.port}")
public int port;
@Value("${es.scheme}")
public String scheme;
@Bean(destroyMethod = "close")
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host, port, scheme)));
}
}
4.单元测试
创建索引库
@Test
public void createIndexTest() throws IOException {
CreateIndexRequest indexRequest = new CreateIndexRequest(index);
CreateIndexResponse response = client.indices().create(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
判断索引库是否存在
@Test
public void indexExistsTest() throws IOException {
GetIndexRequest request = new GetIndexRequest(index);
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
添加文档
@Test
public void addDocTest() throws IOException {
IndexRequest request = new IndexRequest(index);
String source = JSONObject.toJSONString(new Users(1000, "瑟曦", 30));
request.source(source, XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult()); //CREATED
}
批量添加文档
@Test
public void batchAddDocTest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
List<IndexRequest> indexRequests = generateRequests();
indexRequests.forEach(x -> {
bulkRequest.add(x);
});
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(response.hasFailures());
}
public List<IndexRequest> generateRequests() {
List<IndexRequest> requests = new ArrayList<>();
requests.add(generateNewRequests(new Users(1, "雪诺", 25)));
requests.add(generateNewRequests(new Users(2, "艾丽娅", 20)));
requests.add(generateNewRequests(new Users(3, "珊莎", 23)));
return requests;
}
public IndexRequest generateNewRequests(Users users) {
IndexRequest indexRequest = new IndexRequest(index);
indexRequest.source(JSONObject.toJSONString(users), XContentType.JSON);
return indexRequest;
}
根据条件搜索文档
@Test
public void serachTest() throws IOException {
SearchRequest request = new SearchRequest(index);
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(new RangeQueryBuilder("age").from(20).to(30))
.mustNot(new TermQueryBuilder("id", 1000));
builder.query(boolQueryBuilder);
request.source(builder);
System.out.println("搜索语句为:" + request.source().toString());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("搜索结果:" + response);
SearchHits hits = response.getHits();
SearchHit[] hitsArr = hits.getHits();
for (SearchHit documentFields : hitsArr) {
System.out.println(documentFields.getSourceAsString());
}
}
修改文档
@Test
public void modifyDocTest() throws IOException {
UpdateRequest request = new UpdateRequest(index, "nqHRknUBJcoqc7s-i-Az");
Map<String, Object> params = new HashMap<>();
params.put("id", 4);
request.doc(params);
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
删除指定ID的文档
@Test
public void deleteDocTest() throws IOException {
DeleteRequest request = new DeleteRequest(index, "nqHRknUBJcoqc7s-i-Az");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
删除索引库
@Test
public void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest(index);
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
完结
与springboot集成的话也可直接使用ElasticsearchRestTemplate,也是基于RestHighLevelClient的模板封装,后续有需要可以研究下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号