数据采集与融合技术第三次作业
数据采集与融合技术第三次作业
| 学号姓名 | Gitee仓库地址 |
|---|---|
| 102202116 李迦勒 | 李迦勒/黑马楼直面爬虫 - 码云 - 开源中国 |
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码如下:
item.py
点击查看代码
import scrapy
class DangdangImagesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
import scrapy
class DangdangImagesItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
#spider.py
点击查看代码
import os
import scrapy
from dangdang_images.items import DangdangImagesItem
class DangdangSearchSpider(scrapy.Spider):
name = 'dangdang_search'
allowed_domains = ['search.dangdang.com','ddimg.cn']
start_urls = ['https://search.dangdang.com/?key=����&act=input'] # 替换为实际的搜索URL
max_images = 128 # 最大图片下载数量
max_pages = 28 # 最大页数
image_count = 0 # 已下载图片数量计数
page_count = 0 # 已访问页面计数
点击查看代码
def parse(self, response):
# 检查是否达到爬取的页数限制
if self.page_count >= self.max_pages or self.image_count >= self.max_images:
return
# 获取所有书籍封面图片的 URL
image_urls = self.extract_image_urls(response)
for url in image_urls:
if self.image_count < self.max_images:
self.image_count += 1
item = DangdangImagesItem()
# 使用 response.urljoin 补全 URL
item['image_urls'] = [response.urljoin(url)]
print("Image URL:", item['image_urls'])
yield item
else:
return # 如果图片数量达到限制,停止爬取
# 控制页面数量并爬取下一页
self.page_count += 1
next_page = response.css("li.next a::attr(href)").get()
if next_page and self.page_count < self.max_pages:
yield response.follow(next_page, self.parse)
def extract_image_urls(self, response):
# 获取所有书籍封面图片的 URL
image_urls = response.css("img::attr(data-original)").getall()
if not image_urls:
# 有些图片URL属性可能是 `src`,尝试备用选择器
image_urls = response.css("img::attr(src)").getall()
return image_urls
import os
import scrapy
from dangdang_images.items import DangdangImagesItem
import concurrent.futures
class DangdangSearchSpider(scrapy.Spider):
name = 'dangdang_search'
allowed_domains = ['search.dangdang.com', 'ddimg.cn']
start_urls = ['https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'] # 替换为实际的搜索URL
max_images = 135 # 最大图片下载数量
max_pages = 35 # 最大页数
image_count = 0 # 已下载图片数量计数
page_count = 0 # 已访问页面计数
def parse(self, response):
# 检查是否达到爬取的页数限制
if self.page_count >= self.max_pages or self.image_count >= self.max_images:
return
# 获取所有书籍封面图片的 URL
image_urls = response.css("img::attr(data-original)").getall()
if not image_urls:
# 有些图片URL属性可能是 `src`,尝试备用选择器
image_urls = response.css("img::attr(src)").getall()
# 使用 ThreadPoolExecutor 下载图片
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = []
for url in image_urls:
if self.image_count < self.max_images:
self.image_count += 1
item = DangdangImagesItem()
# 使用 response.urljoin 补全 URL
item['image_urls'] = [response.urljoin(url)]
print("Image URL:", item['image_urls'])
futures.append(executor.submit(self.download_image, item))
else:
break # 如果图片数量达到限制,停止爬取
# 控制页面数量并爬取下一页
self.page_count += 1
next_page = response.css("li.next a::attr(href)").get()
if next_page and self.page_count < self.max_pages:
yield response.follow(next_page, self.parse)
def download_image(self, item):
# 获取图片 URL
image_url = item['image_urls'][0]
# 确定保存路径
image_name = image_url.split("/")[-1] # 从 URL 中提取图片文件名
save_path = os.path.join('./images2', image_name)
try:
# 发送 GET 请求下载图片
response = requests.get(image_url, stream=True)
response.raise_for_status() # 检查请求是否成功
# 创建目录(如果不存在)
os.makedirs(os.path.dirname(save_path), exist_ok=True)
# 保存图片到本地
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
self.logger.info(f"Image downloaded and saved to {save_path}")
except requests.exceptions.RequestException as e:
self.logger.error(f"Failed to download image from {image_url}: {e}")
pipelines.py
点击查看代码
class DangdangImagesPipeline:
def process_item(self, item, spider):
return item
settings.py
点击查看代码
BOT_NAME = "dangdang_images"
SPIDER_MODULES = ["dangdang_images.1"]
NEWSPIDER_MODULE = "dangdang_images.1"
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
Obey robots.txt rules
ROBOTSTXT_OBEY = False
图片存储路径
IMAGES_STORE = './images'
爬取的图片
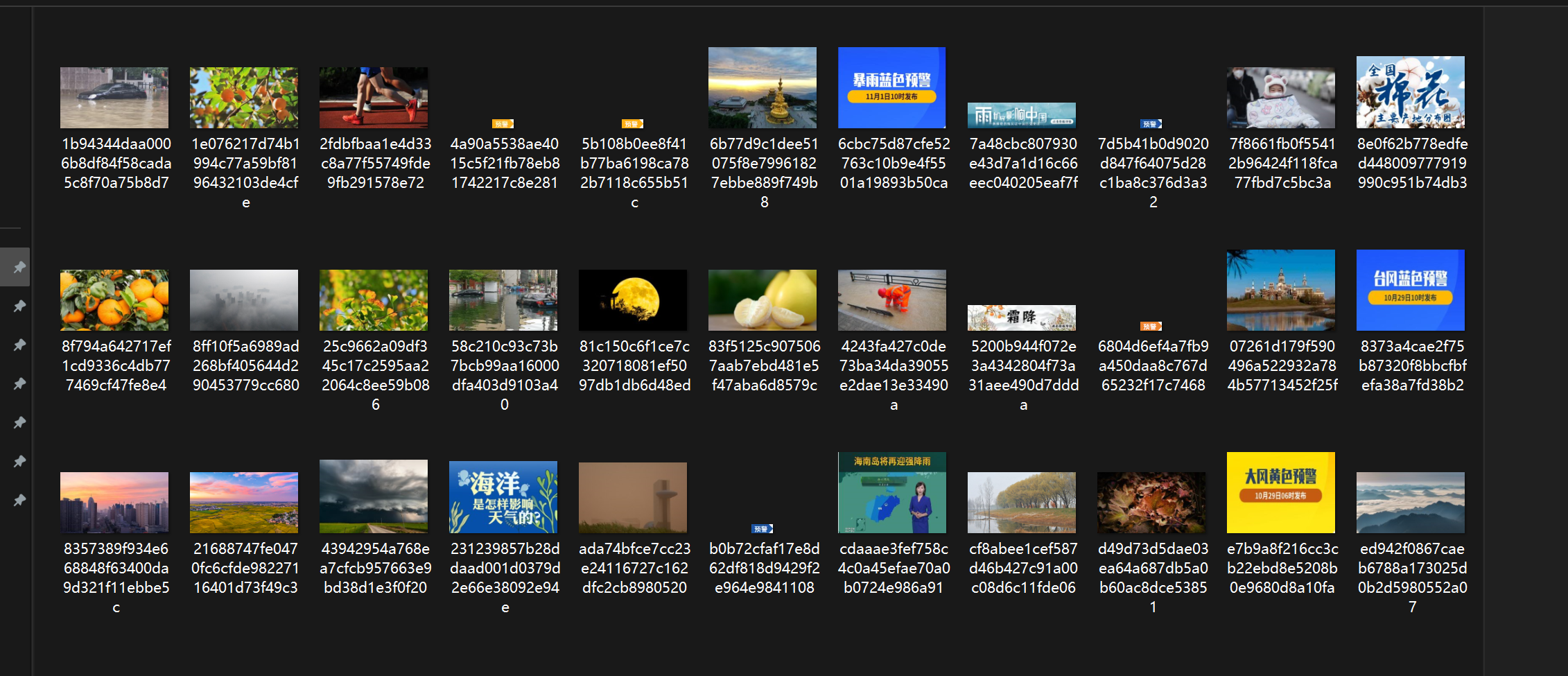
作业心得
首先,通过使用Scrapy框架,我了解到其高效的工作流程,尤其在请求调度、数据处理和数据输出等方面都十分灵活。在这次实践中,我设计了两个爬虫,一个是单线程的,一个是多线程的,以此体验两者的差异。多线程虽然速度更快,但也更容易遇到连接被阻断的情况,因此我在程序中引入了对请求频率的控制。
在爬取时,我还设置了页数和图片数量的限制,以确保程序符合作业要求,并避免给服务器带来过大的压力。这种控制措施也让我更深入理解了爬虫道德和数据获取的边界。
另外,将图片的 URL 信息输出到控制台以及保存图片时,我学会了如何使用 Scrapy 的 Item 管理爬取的数据,这种结构化的数据存储方式很便于后续处理。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
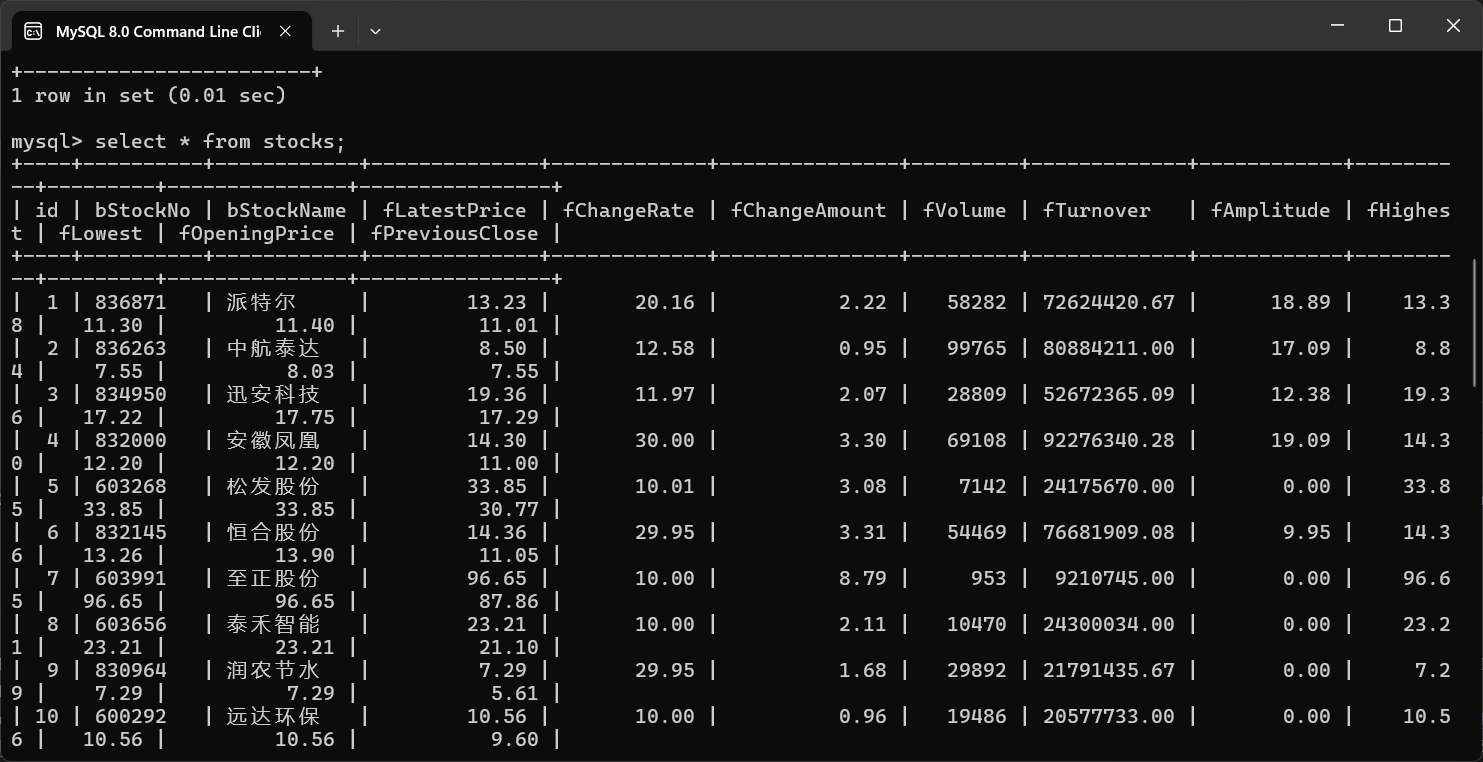
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
代码如下:
item.py
点击查看代码
import scrapy
class StockScraperItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
import scrapy
import scrapy
class StocksScraperItem(scrapy.Item):
bStockNo = scrapy.Field()
bStockName = scrapy.Field()
fLatestPrice = scrapy.Field()
fChangeRate = scrapy.Field()
fChangeAmount = scrapy.Field()
fVolume = scrapy.Field()
fTurnover = scrapy.Field()
fAmplitude = scrapy.Field()
fHighest = scrapy.Field()
fLowest = scrapy.Field()
fOpeningPrice = scrapy.Field()
fPreviousClose = scrapy.Field()
spider.py
import scrapy
import json
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
点击查看代码
# 股票分类及接口参数
cmd = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "f3&fs=m:1+t:2,m:1+t:23",
"深证A股": "f3&fs=m:0+t:6,m:0+t:80",
"北证A股": "f3&fs=m:0+t:81+s:2048",
}
start_urls = []
def start_requests(self):
for market_code in self.cmd.values():
for page in range(1, 3): # 爬取前两页
url = f"https://98.push2.eastmoney.com/api/qt/clist/get?cb=jQuery&pn={page}&pz=20&po=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid={market_code}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
# 提取JSON格式数据
data = response.text
left_data = re.search(r'^.*?(?=\()', data)
if left_data:
left_data = left_data.group()
data = re.sub(left_data + '\(', '', data)
data = re.sub('\);', '', data)
try:
stock_data = json.loads(data)
except json.JSONDecodeError as e:
self.logger.error(f"JSON Decode Error: {e}")
return # 返回以避免后续操作
self.logger.info(f"Parsed JSON Data: {json.dumps(stock_data, indent=4, ensure_ascii=False)}") # 打印解析后的数据
if 'data' in stock_data and 'diff' in stock_data['data']:
for key, stock in stock_data['data']['diff'].items(): # 遍历 diff 字典
# 在此添加调试信息,检查每个股票的数据
self.logger.debug(f"Stock Data: {stock}")
yield {
'bStockNo': stock.get("f12", "N/A"),
'bStockName': stock.get("f14", "N/A"),
'fLatestPrice': stock.get("f2", "N/A"),
'fChangeRate': stock.get("f3", "N/A"),
'fChangeAmount': stock.get("f4", "N/A"),
'fVolume': stock.get("f5", "N/A"),
'fTurnover': stock.get("f6", "N/A"),
'fAmplitude': stock.get("f7", "N/A"),
'fHighest': stock.get("f15", "N/A"),
'fLowest': stock.get("f16", "N/A"),
'fOpeningPrice': stock.get("f17", "N/A"),
'fPreviousClose': stock.get("f18", "N/A")
}
else:
self.logger.warning("No 'data' or 'diff' found in stock_data.")
else:
self.logger.warning("Left data not found in response.")
pipelines.py
点击查看代码
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
port=crawler.settings.get('MYSQL_PORT'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
db=crawler.settings.get('MYSQL_DB'),
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.db,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.connection.cursor()
import pymysql
from itemadapter import ItemAdapter
class StocksScraperPipeline:
def open_spider(self, spider):
self.connection = pymysql.connect(
host='127.0.0.1',
port=33068,
user='root', # 替换为你的MySQL用户名
password='160127ss', # 替换为你的MySQL密码
database='spydercourse', # 数据库名
charset='utf8mb4',
use_unicode=True,
)
self.cursor = self.connection.cursor()
# 创建表格
create_table_sql = """
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(10),
bStockName VARCHAR(50),
fLatestPrice DECIMAL(10, 2),
fChangeRate DECIMAL(5, 2),
fChangeAmount DECIMAL(10, 2),
fVolume BIGINT,
fTurnover DECIMAL(10, 2),
fAmplitude DECIMAL(5, 2),
fHighest DECIMAL(10, 2),
fLowest DECIMAL(10, 2),
fOpeningPrice DECIMAL(10, 2),
fPreviousClose DECIMAL(10, 2)
);
"""
self.cursor.execute(create_table_sql)
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
print(f"Storing item: {item}") # 打印每个存储的项
try:
insert_sql = """
INSERT INTO stocks (bStockNo, bStockName, fLatestPrice, fChangeRate, fChangeAmount, fVolume, fTurnover, fAmplitude, fHighest, fLowest, fOpeningPrice, fPreviousClose)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (
item['bStockNo'],
item['bStockName'],
float(item['fLatestPrice']),
float(item['fChangeRate']),
float(item['fChangeAmount']),
int(item['fVolume']),
float(item['fTurnover']),
float(item['fAmplitude']),
float(item['fHighest']),
float(item['fLowest']),
float(item['fOpeningPrice']),
float(item['fPreviousClose']),
))
self.connection.commit()
except Exception as e:
print(f"Error storing item: {e}")
print(f"SQL: {insert_sql} | Values: {item}")
return item
爬取结果:
实验心得
我进一步掌握了 Scrapy 框架中数据处理和存储的流程,尤其是 Item、Pipeline 的使用和数据的序列化输出。
首先,通过定义 Scrapy 的 Item,我设计了适合的字段来存储股票信息,例如股票代码、股票名称等,按照英文命名规范来组织字段,确保数据结构清晰。然后在 Pipeline 中实现数据的存储过程,把数据序列化并写入 MySQL 数据库。Pipeline 是 Scrapy 中数据处理的关键步骤,这次实践让我加深了对 Pipeline 中各处理阶段的理解。
为了精确获取信息,我使用了 XPath 定位技术,在解析网页数据时更高效。XPath 表达式使得数据提取更加准确和简洁,尤其适合处理结构化的网页内容。
在实现整个爬取流程后,我将数据存储在 MySQL 数据库中。这让我学会了如何在 Scrapy 中配置数据库连接,并掌握了在 Pipeline 中进行数据库操作的方法。将数据直接写入 MySQL,为后续的数据分析和处理奠定了基础。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码如下:
item.py
点击查看代码
import scrapy
class BocExchangeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
import scrapy
class BankItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 时间
pipelines.py
点击查看代码
class BocExchangePipeline:
def process_item(self, item, spider):
return item
import pymysql
from scrapy.exceptions import DropItem
class BankPipeline:
def init(self, mysql_host, mysql_user, mysql_password, mysql_db, mysql_port):
self.mysql_host = mysql_host
self.mysql_user = mysql_user
self.mysql_password = mysql_password
self.mysql_db = mysql_db
self.mysql_port = mysql_port
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host=crawler.settings.get('MYSQL_HOST', 'localhost'),
mysql_user=crawler.settings.get('MYSQL_USER', 'root'),
mysql_password=crawler.settings.get('MYSQL_PASSWORD', ''),
mysql_db=crawler.settings.get('MYSQL_DB', 'boc_exchange'),
mysql_port=crawler.settings.get('MYSQL_PORT', 3306),
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.mysql_host,
user=self.mysql_user,
password=self.mysql_password,
database=self.mysql_db,
port=self.mysql_port,
charset='utf8mb4',
use_unicode=True
)
self.cursor = self.connection.cursor()
create_table_query = """
CREATE TABLE IF NOT EXISTS exchange_rates (
id INT AUTO_INCREMENT PRIMARY KEY,
Currency VARCHAR(100),
TBP DECIMAL(10,2),
CBP DECIMAL(10,2),
TSP DECIMAL(10,2),
CSP DECIMAL(10,2),
Time VARCHAR(20)
)
"""
self.cursor.execute(create_table_query)
self.connection.commit()
def process_item(self, item, spider):
insert_query = """
INSERT INTO exchange_rates (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_query, (
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
))
self.connection.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.connection.close()
spider.py
点击查看代码
import scrapy
from boc_exchange.items import BankItem
class ExchangeSpider(scrapy.Spider):
name = "exchange"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 解析表格数据
table = response.xpath('//table[@class="table-data"]')[0]
rows = table.xpath('.//tr')
for row in rows[1:]: # 跳过表头
item = BankItem()
item['Currency'] = row.xpath('.//td[1]/text()').get().strip()
item['TBP'] = row.xpath('.//td[2]/text()').get().strip()
item['CBP'] = row.xpath('.//td[3]/text()').get().strip()
item['TSP'] = row.xpath('.//td[4]/text()').get().strip()
item['CSP'] = row.xpath('.//td[5]/text()').get().strip()
item['Time'] = row.xpath('.//td[6]/text()').get().strip() # 根据实际情况调整
yield item
运行结果
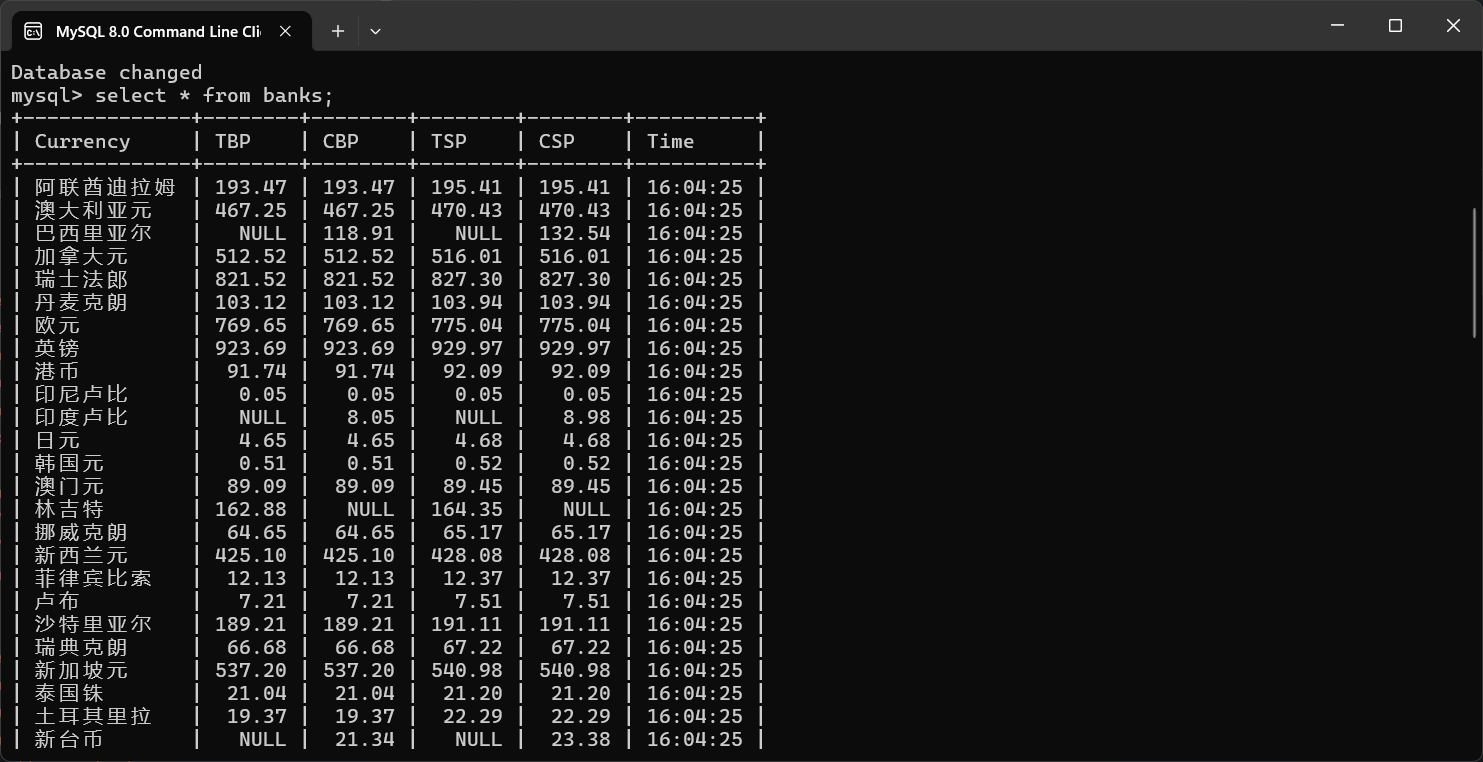
实验心得
在这项外汇数据爬取的作业中,我进一步加深了对 Scrapy 框架的掌握,尤其是通过 Item、Pipeline 以及 MySQL 数据存储的综合应用,使得数据的抓取和存储更加高效和规范。
首先,我定义了 Item 来存储外汇数据,设置了符合需求的字段,如货币名称、买入价、卖出价等。在抓取数据时,我使用了 XPath 定位方法,通过清晰的路径表达式精准提取所需数据。这种方式能够高效地从网页中抓取结构化数据,使数据处理更加简洁和准确。
接着,我在 Pipeline 中实现数据的序列化和存储。Pipeline 使得我可以逐条处理数据,将其清洗并写入 MySQL 数据库。我配置了数据库连接参数,并在 Pipeline 中对每个 Item 进行处理,将数据直接存储到数据库表中,为数据的持久化和后续分析提供了基础。
通过这次作业,我不仅熟练掌握了 Scrapy 中的 Item 和 Pipeline 用法,还在实践中体验了如何结合 XPath 提高爬虫的精准度。同时,将数据存入 MySQL 的过程,让我熟悉了 Scrapy 与数据库的集成方法,为之后的数据处理提供了宝贵经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号