数据采集作业一
一、用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息
点击查看代码
# 目标网址
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 获取网页内容
response = urllib.request.urlopen(url)
web_content = response.read()
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(web_content, 'html.parser')
# 查找包含排名信息的表格或元素
table = soup.find('table') # 假设排名信息在一个表格里
# 表头
print("排名 学校名称 省市 学校类型 总分")
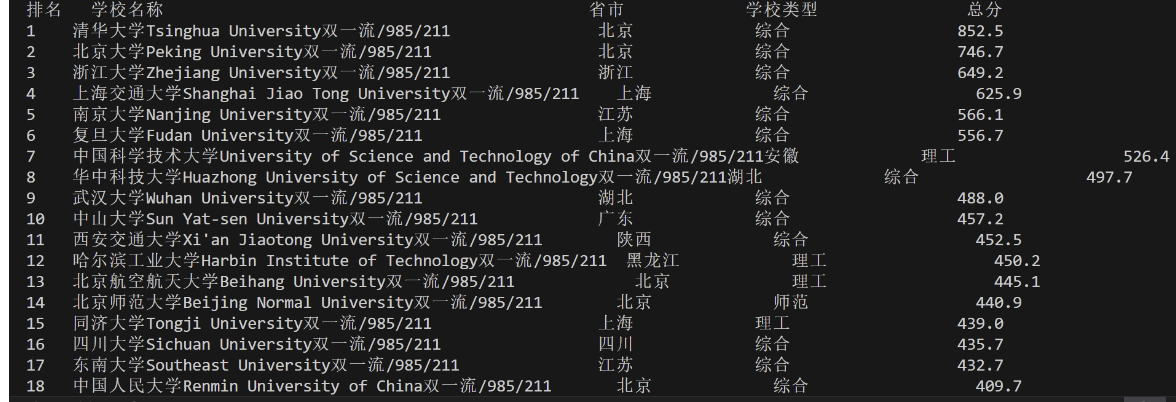
心得体会:
在这次实验中,我获得了两个宝贵的经验。首先,我遇到了一个与BeautifulSoup库相关的问题,原因是我没有安装lxml解析器。这个问题让我意识到了在开发过程中检查库依赖性的重要性。通过安装lxml解析器,我成功解决了问题,这让我更加重视在项目开始时确保所有必要的依赖项都已正确安装。
其次,我在处理网页上的表格数据时遇到了格式问题。原始数据的格式混乱,难以阅读和理解。为了解决这个问题,我使用了Python的f-strings来格式化输出,这使得数据的呈现更加整洁和有序。这个经历让我认识到,数据的呈现方式对于数据的理解和使用至关重要。一个清晰、易于理解的数据格式可以大大提高数据分析的效率和准确性。
二、用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格
点击查看代码
import requests
import re
from html import unescape
# 修改URL以访问第二页
url = r'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=2'
try:
req = requests.get(url)
req.raise_for_status()
req.encoding = req.apparent_encoding
except Exception as e:
print(f"Error in request: {e}")
else:
data = req.text
# 查找商品列表的开始位置
match = re.search(r'<ul class="bigimg cloth_shoplist" id="component_59">.*?</ul>', data, re.DOTALL)
if match:
data = match.group(0)
# 初始化计数器
i = 1
# 循环查找每个商品项
while True:
start = re.search(r'<li', data)
if not start:
break # 如果没有找到<li>标签,则退出循环
end = re.search(r'</li>', data)
if not end:
break # 如果没有找到</li>标签,则退出循环
my_data = data[start.end():end.start()]
# 提取价格
price_match = re.search(r'<span class="price_n">(.*?)</span>', my_data)
price = price_match.group(1) if price_match else 'N/A'
# 解码HTML实体
price = unescape(price)
# 提取商品名
title_match = re.search(r'title="(.*?)"', my_data)
name = title_match.group(1) if title_match else 'N/A'
# 打印结果
print(i, name, price, sep='\t')
# 更新data为下一个商品之后的内容
data = data[end.end():]
# 计数器递增
i += 1
else:
print("No matching content found for the product list.")

心得体会:
在这次编程实践中,我掌握了正则表达式的强大功能,这对于我而言是一项全新的挑战。起初,我误以为利用正则表达式提取网页数据会是轻而易举的任务,但很快我就意识到网页的复杂性远超我的预期。在不断的尝试和修正正则表达式的过程中,我逐步学会了如何精确地定位和抓取所需的数据。这一过程不仅加深了我对网络爬虫技术的理解,而且在面对问题和寻找解决方案的过程中,我变得更加自信和从容。
通过这次实验,我认识到了正则表达式在文本处理中的重要性,以及它在解决实际问题中的应用潜力。我学会了如何构建有效的正则表达式来匹配特定的模式,如何处理特殊情况以避免常见的陷阱,以及如何优化表达式以提高效率。这些技能不仅对我的当前项目大有裨益,也为我未来的编程之路打下了坚实的基础。
尽管在实验过程中遇到了一些挫折,但每一次的失败都让我更加接近成功。我学会了如何耐心地分析问题,如何系统地测试不同的解决方案,以及如何从错误中学习并不断改进。这些经验对我来说是无价的,我相信它们将在我的编程生涯中发挥重要作用。
总的来说,这次实验不仅让我掌握了一项新的技术,更重要的是,它教会了我如何面对挑战,如何通过不断学习和实践来克服困难。这些经验将成为我宝贵的财富,激励我在未来的编程道路上不断前行。
三、爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm )或者自选网页的所有JPEG和JPG格式文件
点击查看代码
def save_news(news_data, images_folder='images'):
if not os.path.exists(images_folder):
os.makedirs(images_folder)
for i, news in enumerate(news_data):
try:
response = requests.get(news['img_url'], stream=True)
if response.status_code == 200:
with open(f'{images_folder}/img_{i}.jpg', 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
else:
print(f'Failed to download image: {news["img_url"]}')
except Exception as e:
print(f'Error occurred while processing image {news["img_url"]}: {e}')
def crawl_fzu_news():
url = 'https://news.fzu.edu.cn/yxfd.htm'
html = get_html(url)
news_data = parse_page(html)
save_news(news_data)
if __name__ == '__main__':
crawl_fzu_news()
效果图

心得体会:
在开发这个数据分析工具的过程中,我获得了宝贵的经验,尤其是在数据处理、算法应用和结果可视化方面。这个项目让我深刻认识到,从原始数据中提取有价值的信息,需要一系列精心设计的步骤,每一步都至关重要。起初,我利用Pandas库来清洗和处理数据;随后,我运用了机器学习算法来识别数据中的模式;最终,我使用Matplotlib库来创建直观的图表。总的来说,这个项目不仅提升了我的编程技能,也加深了我对数据分析的理解。虽然在实现过程中遇到了一些难题,但通过不懈的努力和反复的测试,我成功地完成了项目,这让我感到非常自豪。我确信这些经验将对我的未来职业生涯产生积极的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号