es7.x集群搭建(不使用容器的方式)
elasticsearch集群搭建
1、Elasticsearch 的节点类型
在 Elasticsearch 主要分成两类节点,一类是 Master,一类是 DataNode。
1.1 Master 节点
在 Elasticsearch 启动时,会选举出来一个 Master 节点。
Master 节点主要负责: 管理索引(创建索引、删除索引)、分配分片 维护元数据 管理集群节点状态 不负责数据写入和查询,比较轻量级 一个 Elasticsearch 集群中,只有一个 Master 节点。在生产环境中,内存可以相对 小一点,但机器要稳定。(es7.x默认最小内存的1g)(通过 jvm.options 文件设置堆大小或者启动时通过 ES_JAVA_OPTS 设置)
1.2 DataNode 节点
在 Elasticsearch 集群中,会有 N 个 DataNode 节点。DataNode 节点主要负责: 数据写入、数据检索,大部分 Elasticsearch 的压力都在 DataNode 节点上 在生产环境中,内存最好配置大一些
2、分片和副本机制
2.1 分片(Shard)
Elasticsearch 是一个分布式的搜索引擎,索引的数据也是分成若干部分,分布在不同的服务器节点中 分布在不同服务器节点中的索引数据,就是分片(Shard)。Elasticsearch 会自动管理分片,如果发现分片分布不均衡,就会自动迁移 一个索引(index)由多个 shard(分片)组成,而分片是分布在不同的服务器上的
2.2 副本
为了对 Elasticsearch 的分片进行容错,假设某个节点不可用,会导致整个索引库 都将不可用。所以,需要对分片进行副本容错。每一个分片都会有对应的副本。在 Elasticsearch 中,默认创建的索引为 1 个分片、每个分片有 1 个主分片和 1 个副本 分片。 每个分片都会有一个 Primary Shard(主分片),也会有若干个 Replica Shard(副 本分片) Primary Shard 和 Replica Shard 不在同一个节点上
2.3 指定分片、副本数量
// 创建指定分片数量、副本数量的索引 PUT /job_idx_shard_temp { "mappings":{ "properties":{ "id":{"type":"long","store":true}, "area":{"type":"keyword","store":true}, "exp":{"type":"keyword","store":true}, "edu":{"type":"keyword","store":true}, "salary":{"type":"keyword","store":true}, "job_type":{"type":"keyword","store":true}, "cmp":{"type":"keyword","store":true}, "pv":{"type":"keyword","store":true}, "title":{"type":"text","store":true}, "jd":{"type":"text"}, "creat_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } }, "settings":{ "number_of_shards":3, "number_of_replicas":2 } } // 查看分片、主分片、副本分片 GET /_cat/indices?v
3、Elasticsearch 工作流程
3.1 Elasticsearch 文档写入原理
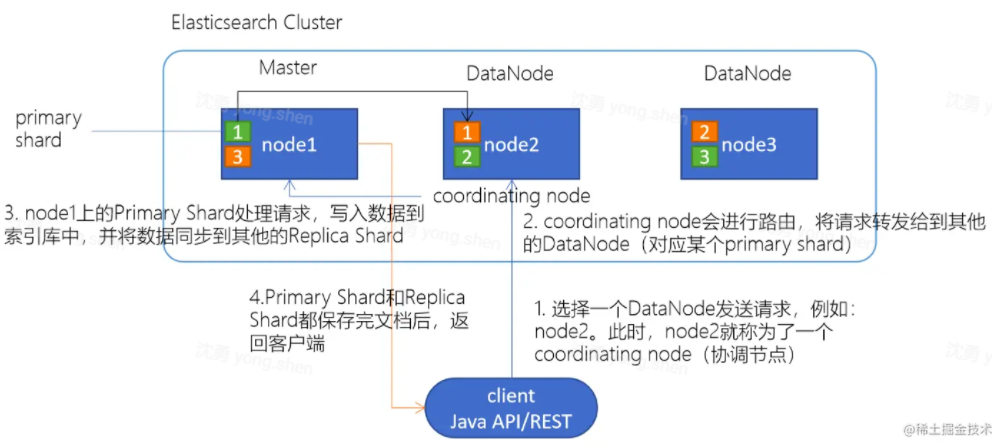
1.选择任意一个 DataNode 发送请求,例如:node2。此时,node2 就成为一个 coordinating node(协调节点)
2.计算得到文档要写入的分片 shard = hash(routing) % number_of_primary_shards routing 是一个可变值,默认是文档的 _id
3.coordinating node 会进行路由,将请求转发给对应的 primary shard 所在的 DataNode(假设 primary shard 在 node1、replica shard 在 node2)
4.node1 节点上的 Primary Shard 处理请求,写入数据到索引库中,并将数据同步到 Replica shard 5.Primary Shard 和 Replica Shard 都保存好了文档,返回 client
3.2 Elasticsearch 检索原理
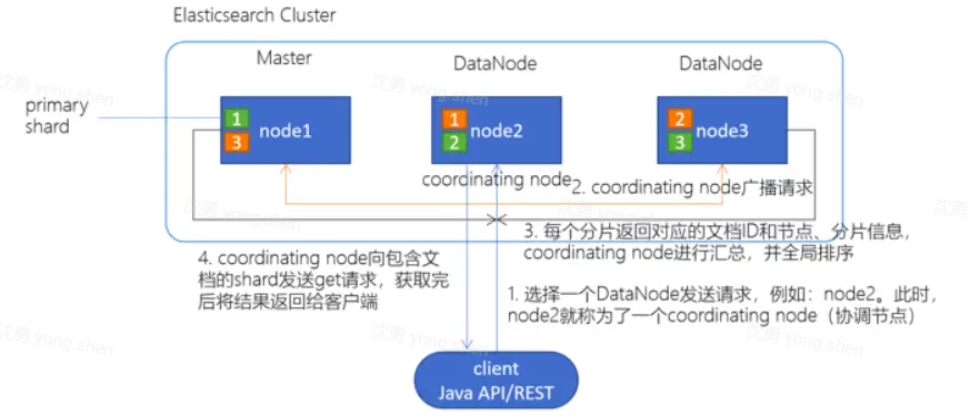
1.client 发起查询请求
2.某个 DataNode 接收到请求,该 DataNode 就会成为协调节点 (Coordinating Node) 协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求 每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档 ID、节点信息、分片信息返回给协调节点
3. 协调节点将所有的结果进行汇总,并进行全局排序 协调节点向包含这些文档 ID 的分片发送 get 请求,对应的分片将文档数据返回给协调节点,
4.协调节点将数据返回给客户端
4、ElasticSearch存储
4.1 溢写到文件系统缓存
当数据写入到 ES 分片时,会首先写入到内存中,然后通过内存的 buffer 生成一个 segment,并刷到文件系统缓存中,数据可以被检索(注意不是直接刷到磁盘) ES 中默认 1 秒,refresh 一次 **
4.2 写 translog 保障容错
在写入到内存中的同时,也会记录 translog 日志,在 refresh 期间出现异常,会根据 translog 来进行数据恢复 等到文件系统缓存中的 segment 数据都刷到磁盘中,清空 translog 文件
4.3 flush 到磁盘
ES 默认每隔 30 分钟会将文件系统缓存的数据刷入到磁盘
4.4 segment 合并
Segment 太多时,ES 定期会将多个 segment 合并成为大的 segment,减少索引查询时 IO 开销,此阶段 ES 会真正的物理删除(之前执行过的 delete 的数据)
5. 为什么需要至少三个节点
参考:https://www.cnblogs.com/xiaohanlin/p/14155964.html
防止脑裂:
“脑裂”问题可能的成因
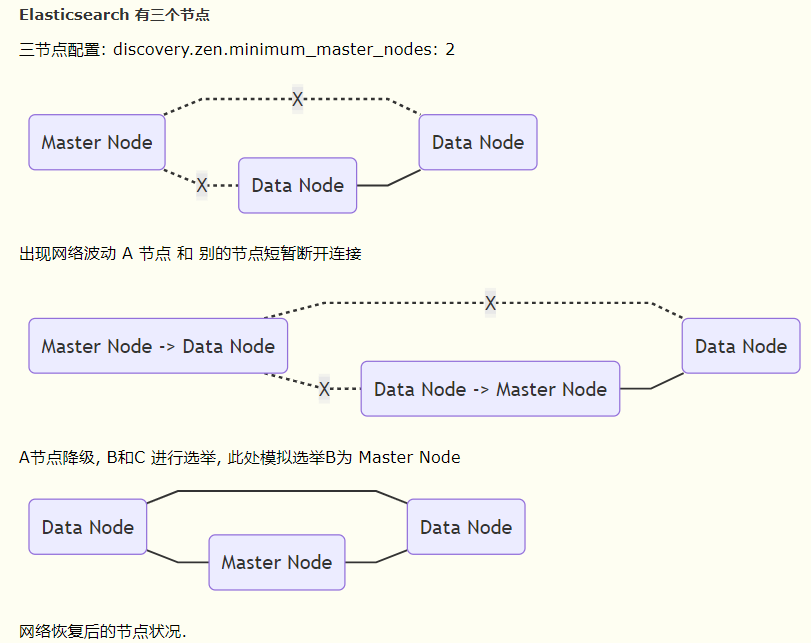
1.网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片
2.节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
3.内存回收:data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
脑裂问题解决方案:
1.减少误判:discovery.zen.ping_timeout节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如6s,discovery.zen.ping_timeout:6),可适当减少误判。
2.选举触发 discovery.zen.minimum_master_nodes:1
该参数是用于控制选举行为发生的最小集群主节点数量。
当备选主节点的个数大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n/2)+1,n为主节点个数(即有资格成为主节点的节点个数)
增大该参数,当该值为2时,我们可以设置master的数量为3,这样,挂掉一台,其他两台都认为主节点挂掉了,才进行主节点选举。
3.角色分离:即master节点与data节点分离
主节点配置为: node.master: true node.data: false 从节点配置为: node.master: false node.data: true
discovery.zen.minimum_master_nodes:选举Maste时需要的节点数 (n / 2 + 1) n为可能被选做master的节点数的和
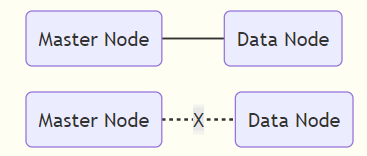
假设 Elasticsearch 有两个节点
-
discovery.zen.minimum_master_nodes: 1
此时出现网络波动, 导致 A—B 之间短暂断开连接, 根据选举规则, B将自己选举为 Master, 当网络波动结束, 就会出现两个Master的情况.

-
discovery.zen.minimum_master_nodes: 2
Master 出现故障, 则 B 将永远不可能将自己选择为 Master
6. es集群搭建
三台机器:["192.168.3.216","192.168.3.215","192.168.3.193"]
1. 官网下载tar包7.3.2 为例 elasticsearch-7.3.2-linux-x86_64.tar.gz
2. 上传服务器
3. 解压:tar -zxvf elasticsearch-7.3.2-linux-x86_64.tar.gz
4. 修改配置
cd elasticsearch-7.3.2/config/ vim elasticsearch.yml
master上配置:
# 集群名 cluster.name: ronnie-es # 节点名 我这是3台机器机, 所以分别是node-1 到 node-3 node.name: node-1 # 主机名 network.host: 192.168.3.216 # http连接端口, ps: 默认9300-9400为集群内部通信端口 http.port: 9216 transport.port: 9316 discovery.seed_hosts: ["192.168.3.215:9316","192.168.3.216:9316","192.168.3.193:9316"] # 比较新的版本不需要配置多波和防脑裂 discovery.zen.ping_timeout: 120s client.transport.ping_timeout: 60s discovery.zen.ping.unicast.hosts: ["192.168.3.216","192.168.3.215","192.168.3.193"] # 初始主节点 cluster.initial_master_nodes: ["node-1","node-2","node-3"] # 是否可以选为master node.master: true # 是否作为data节点,master节点可以不做为data节点,其他的节点作为data节点 node.data: true # 是否支持跨域 http.cors.enabled: true # *表示支持所有域名 http.cors.allow-origin: "*" #数据和存储路径 path.data: /home/elasticsearch-7.3.2/data path.logs: /home/elasticsearch-7.3.2/logs
5. 将es发送到其他机器上
scp -r /home/elasticsearch-7.3.2/ root@192.168.3.215:/home/
scp -r /home/elasticsearch-7.3.2/ root@192.168.3.193:/home/
6. 修改另外两台机器的elasticsearch.yml 节点名和主机名,其他不变
# 节点名 node.name: node-2 # 主机名 network.host: 192.168.3.1215
7. 创建非root用户,启动es
groupadd es useradd es -g es -p 123456 cd ~ chown -R es:es elasticsearch-7.3.2/ # 切换为es用户 su es
8. 运行es
cd elasticsearch-7.3.2 ./bin/elasticsearch # 守护进程启动 ./bin/elasticsearch -d # 停止直接查出pid然后kill ps -aux |grep elasticsearch kill -9 pid号
JVM配置
默认情况,ES 告诉 JVM 使用一个最小和最大都为 1GB 的堆。但是到了生产环境,这个配置就比较重要了,确保 ES 有足够堆空间可用。
ES 使用 Xms(minimum heap size) 和 Xmx(maxmimum heap size) 设置堆大小。你应该将这两个值设为同样的大小。
Xms 和 Xmx 不能大于你物理机内存的 50%。
jvm.options 位于
$ES_HOME/config/jvm.options当通过tarorzip包安装/etc/elasticsearch/jvm.options当通过 Debian or RPM packages

 浙公网安备 33010602011771号
浙公网安备 33010602011771号