filebeat + kafka + ELK搭建
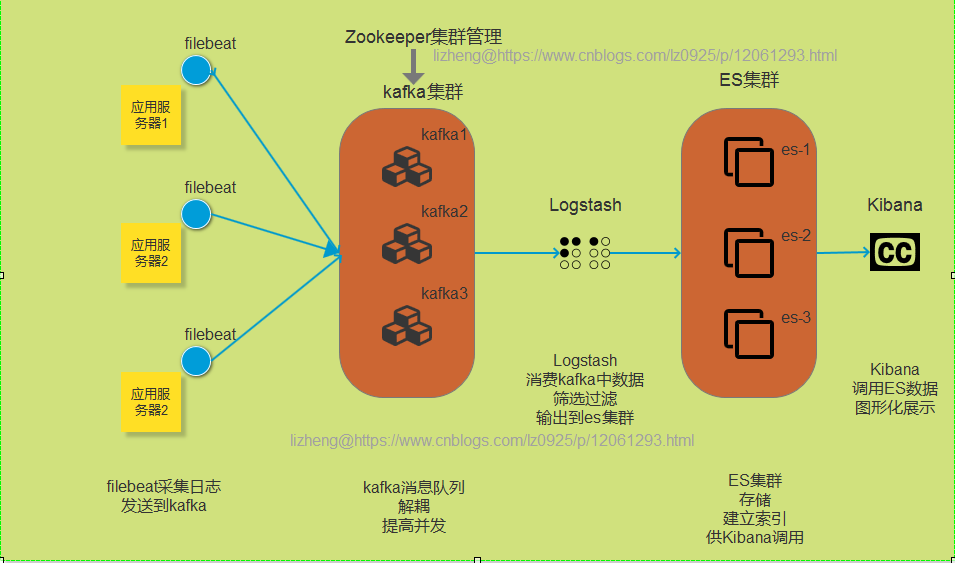
1. 项目流程
2. 压缩与解压 .tar.gz 格式的文件
1、压缩命令:
tar -zcvf 压缩文件名 .tar.gz 被压缩文件名
可先切换到当前目录下,压缩文件名和被压缩文件名都可加入路径。
2、解压缩命令:
命令格式:
tar -zxvf 压缩文件名.tar.gz
解压缩后的文件只能放在当前的目录。
3. centos7防火墙开关
查看防火墙状态
firewall-cmd --state
停止firewall
systemctl stop firewalld.service
禁止firewall开机启动
systemctl disable firewalld.service
-
下载zookeeper镜像:
-
下载kafka镜像:
docker pull wurstmeister/kafka
-
在自己选的目录下创建一个docker-compose.yml文件:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka ports: - "9092" environment: KAFKA_ADVERTISED_HOST_NAME: "10.0.0.202" KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 LANG: "en_US.UTF-8" volumes: - /var/run/docker.sock:/var/run/docker.sock
4. 启动docker-compose
> docker-compose up -d
5. 启动多个kafka 节点,比如3个
> docker-compose scale kafka=3
**测试使用:**
1.通过指定容器名(假设容器名为 elk_kafka_1)进入一个Kafka容器: docker exec -it elk_kafka_1 /bin/bash 2.创建一个topic(其中假设zookeeper容器名为 elk_zookeeper_1,topic名为testtopic),输入: $KAFKA_HOME/bin/kafka-topics.sh --create --topic testtopic \ --zookeeper elk_zookeeper_1:2181 --replication-factor 1 \ --partitions 1 3.查看新创建的topic: $KAFKA_HOME/bin/kafka-topics.sh --zookeeper elk_zookeeper_1:2181 \ --describe --topic testtopic 4.发布消息: (输入若干条消息后 按^C 退出发布) $KAFKA_HOME/bin/kafka-console-producer.sh --topic=testtopic \ --broker-list elk_kafka_1:9092 5.接收消息: $KAFKA_HOME/bin/kafka-console-consumer.sh \ --bootstrap-server elk_kafka_1:9092 \ --from-beginning --topic testtopic
拉取centos镜像
产生的log文件和filebeat运行在这个centos容器中
拉取镜像:
docker pull centos
完成之后可以使用docker images查看镜像情况
制作centos容器
docker run -itd --name centos --privileged=true centos /sbin/init
使用docker ps查看容器情况
进入centos容器:
docker exec -it --privileged=true centos /bin/bash
安装wget:
yum install wget -y
在[elastic官网](https://www.elastic.co/cn/downloads/beats/filebeat)找到下载地址
进入自己filebeat的目录,下载:
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.1.1-linux-x86_64.tar.gz
解压包:
tar -zxvf filebeat-7.1.1-linux-x86_64.tar.gz
配置filebeat.yml 注意hosts后是kafka端口,去docker ps查看一下
filebeat.inputs: - type: log enabled: true paths: - /usr/log/elk.log output.kafka: hosts: ["10.0.0.202:49153","10.0.0.202:49154","10.0.0.202:49155"] topic: 'testtopic'
启动filebeat:
./filebeat -e -c filebeat.yml
然后另开窗口进入centos容器向日志文件里加东西试试,kafka这边的消费者终端能收到东西就说明filebeat到kafka这里是好了
echo "filebeat test 777哈哈 888777777 测试" >> /usr/log/elk.log
docker pull docker.elastic.co/logstash/logstash:7.1.1
完成之后可以使用docker images查看镜像情况
制作logstash容器
docker run -itd -p 5044:5044 -p 5045:5045 --name logstash -e ES_JAVA_OPTS="-Xms1G -Xmx1G" logstash:7.1.1
使用docker ps查看容器情况
进入logstash容器修改配置config(也可以通过映射文件,在外面直接修改然后再启动容器)
logstash.yml :
http.host: "0.0.0.0" xpack.monitoring.elasticsearch.hosts: [ "http://10.211.55.4:9200" ]
新建文件 elk.config :
input { stdin{} kafka { bootstrap_servers => ["10.0.0.202:49166,10.0.0.202:49167,10.0.0.202:49168"] consumer_threads => 1 topics => ["testtopic"] auto_offset_reset => "earliest" } } output { stdout{} elasticsearch { hosts => "http://10.0.0.202:9200" index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } }
测试阶段可以在input里面加一个stdin{},可以通过控制台输入
启动logstash:
bin/logstash -f config/elk.config
可能会遇到这个报错,到data目录下删除.lock文件即可
Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the "path.data" setting.
同步数据库到es三种方式
1. logstash-input-jdbc: ruby语言开发,不能同步删除记录,同步分表时麻烦,ES官方推荐
2. elasticsearch-jdbc: Java开发,只支持到ES2.3.4
3. go-mysql-elastic:go语言开发,可以同步全库增删改查,但社区维护少有bug,不建议上生产环境
sudo yum install gem
-
换源
gem sources -l # 删除默认的源 gem sources --remove https://rubygems.org/ #添加新的源 gem sources -a https://gems.ruby-china.org/ gem sources -l
-
修改Gemfile的数据源地址。步骤:
whereis logstash # 查看logstash安装的位置, 我的在 /opt/logstash/ 目录 sudo vi Gemfile # 修改 source 的值 为: "https://gems.ruby-china.org/" sudo vi Gemfile.lock # 找到 remote 修改它的值为: https://gems.ruby-china.org/
-
安装logstash-input-jdbc
-
方法一
cd bin/
logstash-plugin install logstash-input-jdbc
如果成功就成功了。
-
方法二
进入源码地址的release页面
关于插件版本的选择 参考这里:
复制下载地址
sudo wget https://github.com/logstash-plugins/logstash-input-jdbc/archive/v1.0.0.zip cd bin/ logstash-plugin install v1.0.0.zip
-
方法三直接本地下载后上传,解压安装
实例:
-
mysql数据库,es,和logstash已经安装启动
-
进入logstash,进入配置文件中新增两个文件(elk.conf上面有了,jdbc.sql)前缀名无所谓
-
一个 mysql 的java 驱动包 : mysql-connector-java-5.1.36-bin.jar,官网下载上传解压
宿主机本地文件上传到docker容器里:docker cp 宿主机本地路径 容器ID:容器路径
elk.conf中input下配置:
input{ jdbc { jdbc_connection_string => "jdbc:mysql://106.75.30.97:8005/el_pvmi" jdbc_user => "root" jdbc_password => "l4396" jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" codec => plain { charset => "UTF-8"} use_column_value => true tracking_column => id record_last_run => true last_run_metadata_path => "/usr/share/logstash/config/station_parameter.txt" jdbc_paging_enabled => true jdbc_page_size => 300 clean_run => false statement_filepath => "/usr/share/logstash/config/jdbc.sql" schedule => "* * * * *" } }
jdbc.sql :后面一定跟上排序id asc,并开启分页,否则一直处理同一批数据,造成死循环,最好的方式是表中加一个update_time字段每次修改都自动更新时间,使用update_time就可以当数据库有修改时自动同步
select * from station where id > :sql_last_value order by id asc
拉取镜像:
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.1.1
启动运行容器:
docker run --name es -p 9200:9200 -p 9300:9300 \ docker.elastic.co/elasticsearch/elasticsearch:7.1.1
docker pull docker.elastic.co/kibana/kibana:7.1.1
-
建容器:
docker run -d --name kibana -p 5601:5601 docker.elastic.co/kibana/kibana:7.1.1
浏览器访问:http://10.0.0.202:5601

