scrapy请求传参、提高爬取效率、中间件、user-agent池、分布式爬虫
scrapy请求传参、提高爬取效率、中间件、user-agent池、分布式爬虫
1. scrapy请求传参
def parse(self, response): div_list = response.css('div.post_item') for div in div_list: item = ScrItem() dec = div.css('p.post_item_summary::text').extract()[-1] author = div.css('.post_item_foot a::text').extract_first() item['author'] = author # 将数据存入meta中,callback调用下一个函数 yield Request(url, callback=self.parse_detail, meta={'item':item}) next_page = response.css('div.pager a:last-child::attr(href)').extract_first() yield Request(next_page) def parse_detail(self, response):
# 将数据取出 item = response.meta.get('item') content = response.css('#cnblogs_post_body').extract_first() item['content'] = content yield item
2. 提高爬取效率
在配置文件中配置相关配置即可
1、增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100 # 并发设置成100
2、提高日志级别:在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写
LOG_LEVEL='ERROR'
3、禁止cookie:如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False
4、禁止重试:对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False
5、减小下载超时:如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 # 超时时间为10s
3. fake-useragent
请求头中的携带的useragent,搞一个ua池然后随机返回一个,有对应的模块简单使用就好
安装:pip3 install fake-useragent
使用:
from fake_useragent import UserAgent
ua=UserAgent(verify_ssl=False)
print(ua.random) # 随机生成一个useragent
4. 中间件
有爬虫中间件与下载中间件,一般用的最多的就是下载中间件
1. 下载中间件
1、在配置中配置
# 爬虫中间件 SPIDER_MIDDLEWARES = { 'scr.middlewares.ScrSpiderMiddleware': 543, } # 下载中间件 DOWNLOADER_MIDDLEWARES = { 'scr.middlewares.ScrDownloaderMiddleware': 543, }
2、在middlewares.py中写中间件
下载中间件主要有三个方法:
-process_request:(请求去的时候,走) # - return None: 继续处理当次请求,进入下一个中间件 # - return Response: 当次请求结束,把Response丢给引擎处理(可以自己爬,包装成Response) # - return Request : 相当于把Request重新给了引擎,引擎再去做调度 # - 抛异常:执行process_exception
-process_response:(请求回来的时候,走) # - return a Response object :继续处理当次Response,继续走后续的中间件 # - return a Request object:重新给引擎做调度 # - or raise IgnoreRequest :process_exception
-process_exception:(出异常,走) # - return None: continue processing this exception # - return a Response object: stops process_exception() chain :停止异常处理链,给引擎(给爬虫) # - return a Request object: stops process_exception() chain :停止异常处理链,给引擎(重新调度)


# 获取代理函数 def get_proxy(self): import requests proxy = requests.get('代理地址/get').json()['proxy'] return proxy def process_request(self, request, spider): # 1 加cookie(在request.cookies中就是访问该网站的cookie) print(request.cookies) #从你的cookie池中取出来的, 字典,设置 request.cookies={'k':'v'} print(request.cookies) # 2 加代理 在request.meta['proxy']中加 request.meta['proxy'] = self.get_proxy() # 3 修改useragent from fake_useragent import UserAgent ua = UserAgent(verify_ssl=False) request.headers['User-Agent'] = ua return None
def process_exception(self, request, exception, spider): # 如果url错误在这不能直接修改url # request.url = 'http://www.cnblogs.com/' # 如果想在中间件中修改url必须引入Request做修改, 也可以做回调 from scrapy.http import Request return Request('http://www.cnblogs.com/') # return Request('http://www.cnblogs.com/', callback=spider.parse_detail)
集成selenium可以在 process_request 和 process_response 中做,在process_request 中做效率更高
1. 在爬虫中创建bro对象和关闭爬虫
# 在爬虫中创建bro对象 bro = webdriver.Chrome(executable_path='E:\Python\scr\chromedriver.exe') # 关闭,在爬虫中 def close(self, reason): self.bro.close()
2. 在中间件中使用selenium解析并返回
from scrapy.http import HtmlResponse spider.bro.get(request.url) text = spider.bro.page_source response = HtmlResponse(url=request.url, body=text.encode('utf8')) return response
5. bitmap去重与布隆过滤器原理
1. bitmap去重
通过一个比特位来存一个地址,占用内存很小
2. 布隆过滤器
BloomFilter 会开辟一个m位的bitArray(位数组),开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(h1,h2,h3....)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。
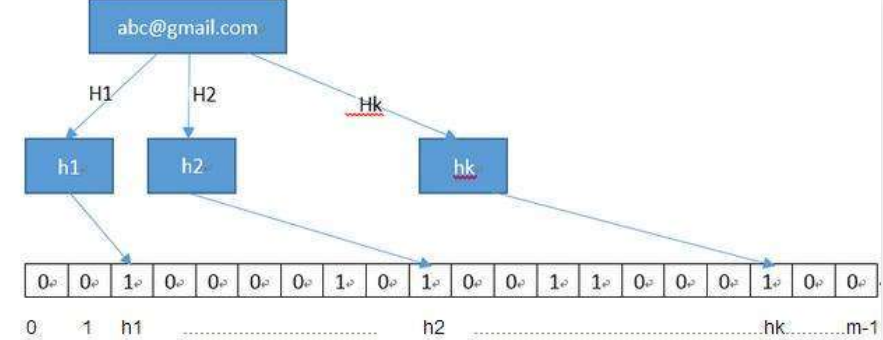
Python中使用布隆过滤器
#python3.6 安装 #需要先安装bitarray pip3 install bitarray-0.8.1-cp36-cp36m-win_amd64.whl(pybloom_live依赖这个包,需要先安装) #下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ pip3 install pybloom_live
示例一
#ScalableBloomFilter 可以自动扩容 from pybloom_live import ScalableBloomFilter bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH) url = "www.cnblogs.com" url2 = "www.baidu.com" bloom.add(url) print(url in bloom) print(url2 in bloom)
示例二
#BloomFilter 是定长的 from pybloom_live import BloomFilter bf = BloomFilter(capacity=1000) url='www.baidu.com' bf.add(url) print(url in bf) print("www.cnblogs.com" in bf)
6. 分布式爬虫
安装:pip3 install scrapy-redis
1. 原来的爬虫继承并修改start_urls
# 1 原来的爬虫继承 from scrapy_redis.spiders import RedisSpider class CnblogsSpider(RedisSpider): #start_urls = ['http://www.cnblogs.com/'] redis_key = 'myspider:start_urls'
2. 在settings中配置
# 2 在setting中配置 SCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 这里可以不配就走每一个的数据库,配置了就走公用的数据库 ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300 } # REDIS_HOST = 'localhost' # REDIS_PORT = 6379 # REDIS_ENCODING = 'utf8' REDIS_PARAMS = {'password':'2694'}
3. 多台机器启动爬虫
4. 通过命名向redis中发送起始url
redis-cli
auth password
lpush myspider:start_urls https://www.cnblogs.com

