爬虫介绍及requests模块
爬虫介绍及requests模块
1. 爬虫介绍
1. 本质
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据
本质:模拟发送http请求(requests)----》解析返回数据(re,bs4,lxml,json)---》入库(redis,mysql,mongodb)
2. 爬虫价值
互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
其实百度,谷歌,就是个大爬虫 在百度搜索,其实是去百度的服务器的库搜的,百度一直开着爬虫,一刻不停的在互联网上爬取,把页面存储到自己库中
可以爬取律师网站、房源信息、医疗、简历库,然后搭建一个搜索网站(APP,小程序)
3. 为什么Python做爬虫好
Python的包多,有爬虫的框架:scrapy,性能高,是爬虫界的Django所有爬虫相关的东西都集成了
4. 爬虫四部曲
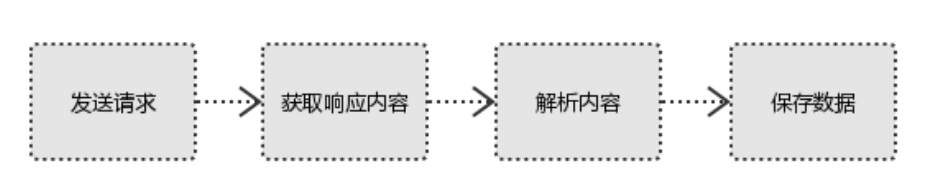
#1、发起请求 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头、请求体等 #2、获取响应内容 如果服务器能正常响应,则会得到一个Response Response包含:html,json,图片,视频等 #3、解析内容 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等 解析json数据:json模块 解析二进制数据:以b的方式写入文件 #4、保存数据 数据库 文件
2. HTTP协议
1. 特点
1、基于TCP/IP 协议之上的应用层协议
mysql,redis,MongoDB:CS架构的软件:Navicat,pymysql都是mysql客户端 通过socket自己定制的协议连接到服务端
docker,es 都是通过http(resful规范)连接到服务端
2、一次请求一次响应
客户端主动发起请求,服务端才能响应
3、无状态保存(cookie,session,token)
session:只对当前域名下有效,只适用于客户端代码和服务端代码在同一个服务器上的,session服务器会保存一份,key:用户信息
token:前后端分离,域名可以不一样,再次请求需要认证信息,authorization=token:用户信息
4、无连接
发送一次完请求,响应完就断开
1.x:线程阻塞,在同一时间内,同一域名请求的数量是有限的,超过限制数就会阻塞
2.0:采用二进制格式高效错误更少,完全多路复用,非阻塞的一个连接可并行,使用报头压缩降低开销
2. 数据格式
-
请求格式
-
请求首行(请求方式,url,协议版本)
-
请求头(一大堆k, v 键值对)
请求头包含许多有关的客户端环境和请求体的有用信息。例如,请求头可以声明浏览器所用的语言,请求体的长度等。Accept:image/gif.image/jpeg.*/*Accept-Language:zh-cnConnection:Keep-AliveHost:localhostUser-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)Accept-Encoding:gzip,deflate.
-
-
-
空行:表示请求头已经结束,接下来的是请求体
-
请求体(携带的数据 并不是一直都有,有时候可能是空的,取决于你的请求方式)
-
-
响应格式
- 响应首行(响应状态码)
- 响应头(一大堆k, v 键值对)
响应头(Response Header)响应头也和请求头一样包含许多有用的信息,例如服务器类型、日期时间、内容类型和长度等:Server:Apache Tomcat/5.0.12Date:Mon,6Oct2003 13:13:33 GMTContent-Type:text/htmlLast-Moified:Mon,6 Oct 2003 13:23:42 GMTContent-Length:112
- 空行
- 响应体(浏览器展示给用户看的数据)
3. requests模块
可以模拟发送http请求,Python内置有urlib2内置库不好用,有人就封装成了requests模块
需要下载:pip3 install requests
1. 基本使用
#各种请求方式:常用的就是requests.get()和requests.post() >>> import requests >>> r = requests.get('https://api.github.com/events') >>> r = requests.post('http://httpbin.org/post', data = {'key':'value'}) >>> r = requests.put('http://httpbin.org/put', data = {'key':'value'}) >>> r = requests.delete('http://httpbin.org/delete') >>> r = requests.head('http://httpbin.org/get') >>> r = requests.options('http://httpbin.org/get')
2. get请求
import requests # # 1 发送http请求 # # get,delete,post。。本质都是调用request函数 # ret=requests.get('https://www.cnblogs.com') # print(ret.status_code) # 响应状态码 # print(ret.text) # 响应体,转成了字符串 # print(ret.content) # 响应体,二进制
3. get请求携带参数
# 方式一:直接在url中携带 ret = requests.get('https://www.baidu.com/name=‘sy’', headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' } ) print(ret.text) # 方式二:params中携带(建议使用)中文会自动转码 ret = requests.get('http://127.0.0.1:8000/', params={'name': "美女", 'age': 18} ) print(ret.text) # headers中携带User-Agent,Referer
ret = requests.get('http://127.0.0.1:8000/', headers={ # 标志,什么东西发出的请求,浏览器信息,django框架,从(meta)中获取 'User-Agent': 'Windows NT 10.0; WOW64', # 上一个页面的地址,图片防盗链 'Referer': 'xxx' }, params={'name': "美女", 'age': 18} ) print(ret.text)
4. 携带cookie
## 方式1 headers中携带 ret = requests.get('https://www.cnblogs.com/Mr-shen/', headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36', 'cookie':'_ga=GA1.2.92651;yymWa9zVkZoKw' }) print(ret.text) ## 方式2 cookies中携带 ret = requests.get('http://127.0.0.1:8000/?name=%E7%BE%8E%E5%A5%B3', cookies={"islogin":"xxx"}) print(ret)
5. post请求
携带数据是在data中,可以使用json编码后发送
# 发送post请求(注册,登陆),携带数据(body) #data=None, json=None # data:urlencoded编码 ret=requests.post('http://0.0.0.0:8001/',data={'name':"lqz",'age':18}) # json:json编码,Django后台在body中获取 import json data=json.dumps({'name':"lqz",'age':18}) ret=requests.post('http://0.0.0.0:8001/',json=data) print(ret) # 注意:编码格式是请求头中带的,所有我可以手动修改,在headers中改
6. session对象
# session=requests.session() # # 跟requests.get/post用起来完全一样,但是它处理了cookie # # 假设是一个登陆,并且成功 # session.post() # # 再向该网站发请求,就是登陆状态,不需要手动携带cookie # session.get("地址")
7. 响应对象
# print(respone.text) # 响应体转成str # print(respone.content) # 响应体二进制(图片,视频) # # print(respone.status_code) # 响应状态码 # print(respone.headers) # 响应头 # print(respone.cookies) # 服务端返回的cookie # print(respone.cookies.get_dict()) # 转成字典 # print(respone.cookies.items()) # # print(respone.url) # 当次请求的地址 # print(respone.history) # 如果有重定向,放到一个列表中 # print(respone.encoding) # 编码方式 #response.iter_content() # 视频,图片迭代取值 # with open("a.mp4",'wb') as f: # for line in response.iter_content(): # f.write(line)
8. 乱码问题
# 加载回来的页面,打印出来,乱码(我们用的是utf8编码),如果网站用gbk, # ret.encoding='gbk' # ret=requests.get('http://0.0.0.0:8001/user') # # ret.apparent_encoding当前页面的编码 # ret.encoding 与 ret.apparent_encoding 是一样的
9. 解析json
ret = requests.get('http://127.0.0.1:8000/') a = ret.json() print(a) print(type(a))
10. 使用代理
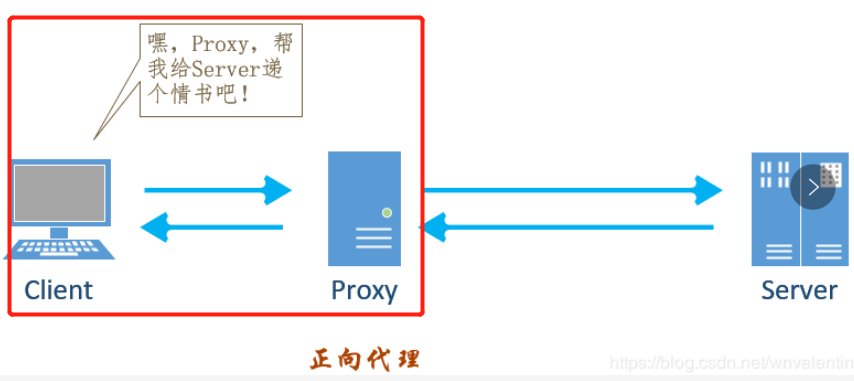

正向代理是对客户端的代理,由客户端设立,客户端了解代理服务器和目标服务器,但目标服务器不了解真正的客户端是谁;使用正向代理可达到 突破访问限制、提高访问速度、对服务器隐藏客户端IP等目的;
反向代理是对服务器的代理,由服务器设立,客户端不了解真正的服务器是谁,使用反向代理可达到负载均衡、保障服务端安全、对客户端隐藏服务器IP等目的。
requests是使用的正向代理
Django中获取客户端 ip
request.META.get('REMOTE_ADDR')
使用代理,别人获取不到我们客户端真正的ip地址只能获取到代理ip
如何使用:proxies={'http': '代理地址'}
# ret=requests.get('http://0.0.0.0:8001/',proxies={'http':'222.85.28.130:40505'}) # print(type(ret.text)) # print(ret.text)
代理地址网上会有免费的代理,但是不稳定
高匿:服务端,根本不知道我是谁
普通:服务端是能够知道我的ip的
使用代理有什么用:drf 1分钟只能访问6次,限制了ip,每次发请求都使用不同的代理就可以解决
4. 爬虫简单练习
1. 爬取梨视频
import requests import re # 正则模块 # uuid.uuid4() 可以根据时间戳生成一段世界上唯一的随机字符串 import uuid # 导入线程池模块 from concurrent.futures import ThreadPoolExecutor # 线程池限制50个线程 pool = ThreadPoolExecutor(50) # 爬虫三部曲 # 1、发送请求 def get_page(url): print(f'开始异步任务: {url}') response = requests.get(url) return response # 2、解析数据 # 解析主页获取视频详情页ID def parse_index(res): response = res.result() # 提取出主页所有ID id_list = re.findall('<a href="video_(.*?)"', response.text, re.S) # print(res) # 循环id列表 for m_id in id_list: # 拼接详情页url detail_url = 'https://www.pearvideo.com/video_' + m_id # print(detail_url) # 把详情页url提交给get_page函数 pool.submit(get_page, detail_url).add_done_callback(parse_detail) # 解析详情页获取视频url def parse_detail(res): response = res.result() movie_url = re.findall('srcUrl="(.*?)"', response.text, re.S)[0] # 异步提交把视频url传给get_page函数,把返回的结果传给save_movie pool.submit(get_page, movie_url).add_done_callback(save_movie) # 3、保存数据 def save_movie(res): movie_res = res.result() # 把视频写到本地 with open(f'{uuid.uuid4()}.mp4', 'wb') as f: f.write(movie_res.content) print(f'视频下载结束: {movie_res.url}') f.flush() if __name__ == '__main__': # main + 回车键 # 一 往get_page发送异步请求,把结果交给parse_index函数 url = 'https://www.pearvideo.com/' pool.submit(get_page, url).add_done_callback(parse_index)
2. 自动登录网站
import requests ret = requests.post('http://www.aa7a.cn/user.php', # 登录页面登录时检查携带的哪些参数 data={ 'username': '616564099@qq.com', 'password': 'lqz123', 'captcha': 'fszc', 'remember': '1', 'ref': 'http://www.aa7a.cn/', 'act': 'act_login', } ) cookie = ret.cookies.get_dict() print(cookie) # 获取到cookies后就可以正常使用了 ret1 = requests.get('http://www.aa7a.cn/', cookies=cookie) print('616564099@qq.com' in ret1.text)
# 秒杀小米手机,一堆小号 # 定时任务:一到时间,就可以发送post请求,秒杀手机 # 以后碰到特别难登陆的网站,代码登陆不进去怎么办? # 之所以要登陆,就是为了拿到cookie,下次发请求(如果程序拿不到cookie,自动登陆不进去) # 就手动登陆进去,然后用程序发请求

