pandas
pandas
1、pandas简介
pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。
Pandas的主要功能:
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
安装方法:
pip install pandas
引用方法:
import pandas as pd
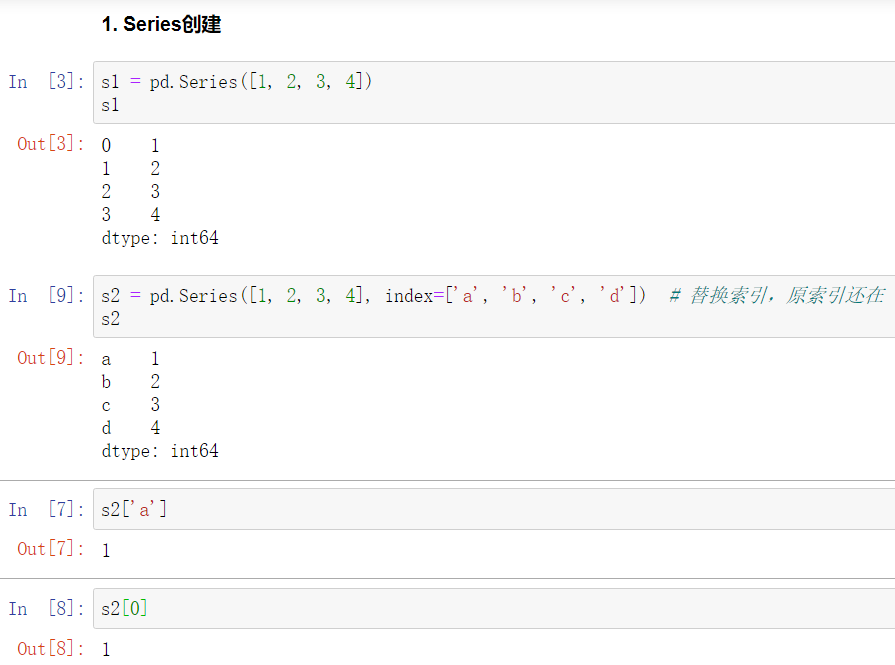
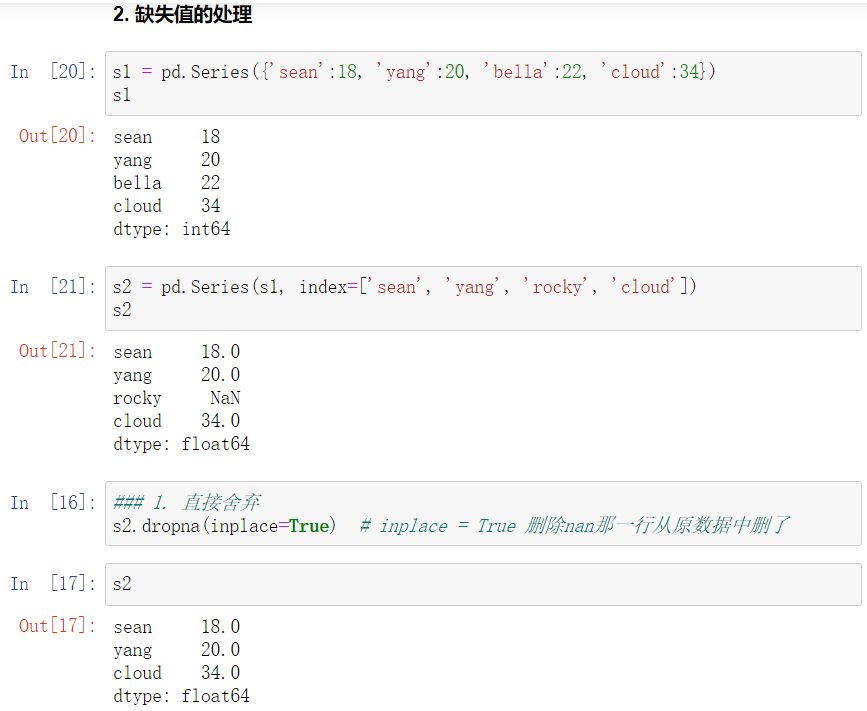
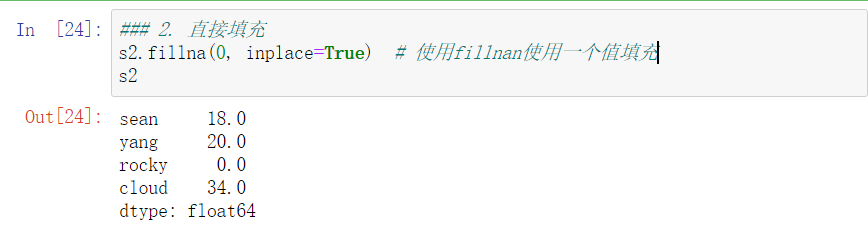
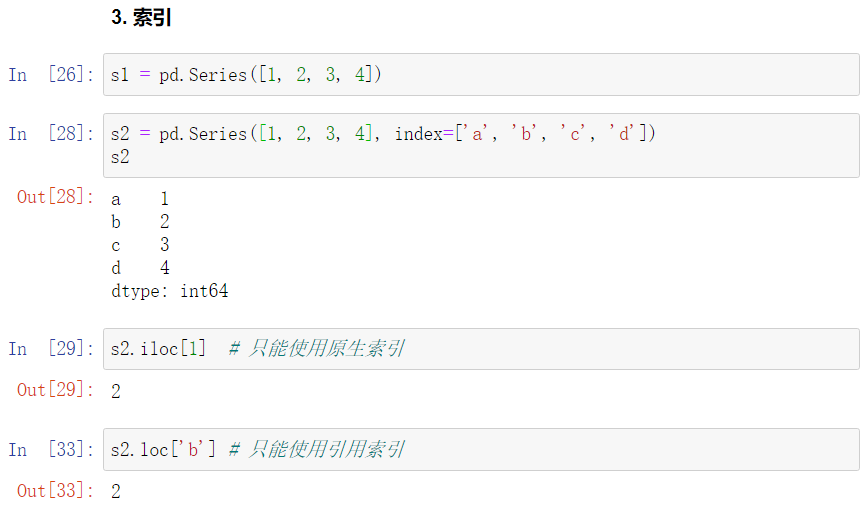
2、Series
Series特性与numpy特性相同,使用相同
3、DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
将series类型转化为dataframe类型:
series.to_frame()
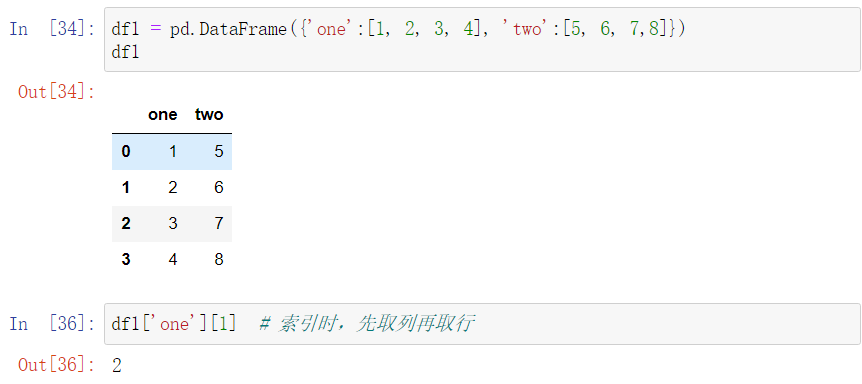
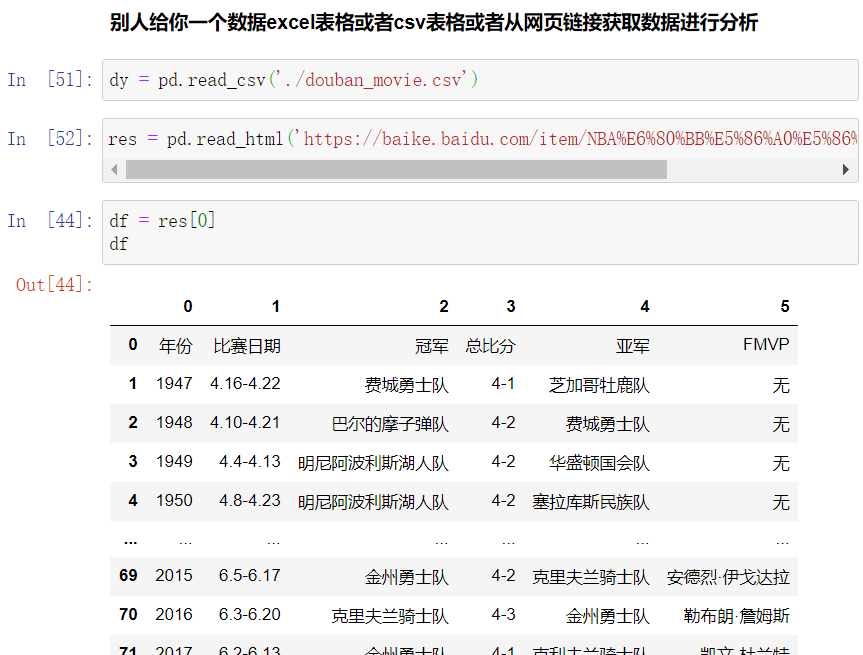
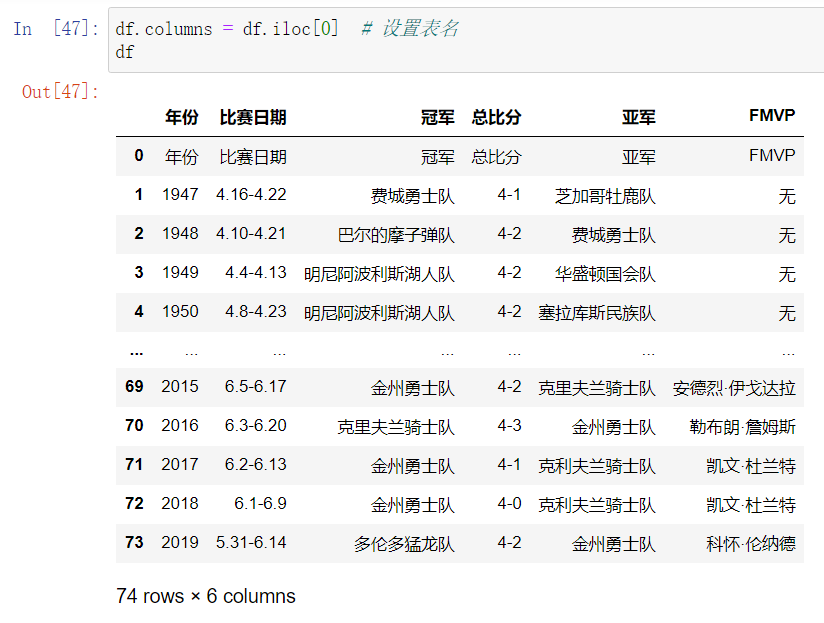
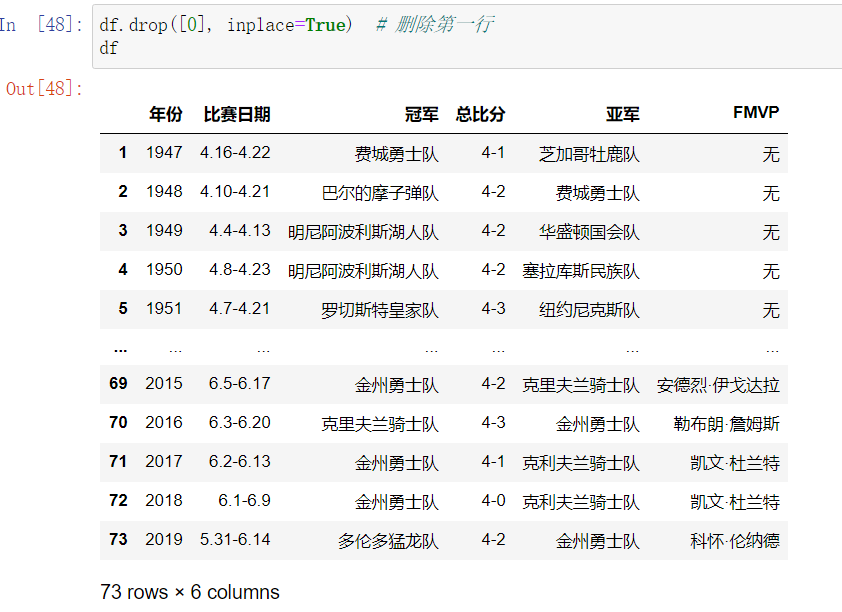

4. dataframe数据清洗常用手段
#导入必备数据分析库 import pandas as pd import numpy as np #导入excel数据文件, read_excel 没有encoding参数、 df = pd.DataFrame(pd.read_excel("TMao.xlsx")) #导入csv数据文件 # df = pd.DataFrame(pd.read_csv("Attributes.csv",header=0,sep=',')) # header =0,则指定第一行为列名;若header =1 则指定第二行为列名;
有时,我们的数据里没有列名,只有数据,这时候就需要names=[], 来指定列名;
sep: 读取csv文件时指定的分隔符,默认为逗号。注意:“csv文件的分隔符” 和 “我们读取csv文件时指定的分隔符” 一定要一致。多个分隔符时,应该使用 | 将不同的分隔符隔开;sep=":|;" csv文件有表头并且是第一行,那么names和header都无需指定; csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可; csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头; csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
import pandas as pd df = pd.DataFrame(pd.read_excel("TMao.xlsx")) x, y = df.shape print("row:", x, 'col:', y) """ 5 8 """
cols = df.columns print(cols) """ Index(['820080:Chip_PAD_蒸镀-开始时间', '820080:Chip_PAD_蒸镀-结束时间', '820080:Chip_PAD_蒸镀-片号', '820080:Chip_PAD_蒸镀-组件编码', '820080:Chip_PAD_蒸镀-批号', '820080:Chip_PAD_蒸镀-产品编号', '820080:Chip_PAD_蒸镀-设备编号', '820080:Chip_PAD_蒸镀1-Lot号码加片数'], dtype='object') """
all_types = df.dtypes sig_type = df['820080:Chip_PAD_蒸镀-开始时间'].dtype print(all_types, sig_type) """ 820080:Chip_PAD_蒸镀-开始时间 datetime64[ns] 820080:Chip_PAD_蒸镀-结束时间 datetime64[ns] 820080:Chip_PAD_蒸镀-片号 object 820080:Chip_PAD_蒸镀-组件编码 object 820080:Chip_PAD_蒸镀-批号 object 820080:Chip_PAD_蒸镀-产品编号 object 820080:Chip_PAD_蒸镀-设备编号 object 820080:Chip_PAD_蒸镀1-Lot号码加片数 object dtype: object datetime64[ns] """
空值:在pandas中的空值是"",也叫空字符串;
缺失值:在dataframe中为NAN或者NAT(缺失时间)
(在series中为none或者nan)
# df.isnull() 整体查看空值情况 # 判断是否存在空值 print(df.isnull().any()) print(df['820080:Chip_PAD_蒸镀-开始时间'].isnull().any()) """ 820080:Chip_PAD_蒸镀-开始时间 False 820080:Chip_PAD_蒸镀-结束时间 False 820080:Chip_PAD_蒸镀-片号 False 820080:Chip_PAD_蒸镀-组件编码 False 820080:Chip_PAD_蒸镀-批号 False 820080:Chip_PAD_蒸镀-产品编号 False 820080:Chip_PAD_蒸镀-设备编号 False 820080:Chip_PAD_蒸镀1-Lot号码加片数 False dtype: bool False """ # 获取空值行 print(df[df.isna().values==True]) """ 820080:Chip_PAD_蒸镀-开始时间 ... 820080:Chip_PAD_蒸镀1-Lot号码加片数 3 2022-11-18 03:50:58 ... F06765 24片 [1 rows x 8 columns] """
# 1. 删除含有空值的行or列 df2 = df.dropna(axis=0, how='any',subset=['',.. ]) """ axis => 0: 操作行 1:操作列 how => any: 行或列有一个空值就清空。 all: 行或列全部为空才清空。 thresh => 一行或一列中至少出现了thresh个才删除。 subset => 在某些列的子集中选择出现了缺失值的列删除. inplace => True: 原数据上进行修改 """ # 2.无法删除空行或列 可能空字符串。 # 将空字符串替换成空值再进行dropna()操作 df.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True) df['订单付款时间'].dropna()
df.isna().any() #查看原数据表是否存在空值 # 前后值填充 df3 = df.fillna(method='ffill',axis=0,inplace=False,limit=None,downcast=None) """ method => ffill: font-fill 根据前一个填充 bfill:back-fill 后一个 """ # 默认值填充 df3 = df.fillna("填充值") df3.isna().any() #查看填充后的数据表是否存在空值 #用均值填充空值(mean方法) df['订单金额'].fillna(df['订单金额'].mean())
# 清除dataframe cell中的空格 df['收货地址']=df['收货地址'].map(str.strip()) # 大小写转换lower/upper df['编码']=df['编码'].strip().lower() #大写同理,upper() # 更改数据格式 df['订单金额'].astype('int') #int整数类型,同理float浮点型
df['收货地址'].drop_duplicates() #删除列中后出现的值 df['收货地址'].drop_duplicates(keep='last') #删除列中先出现的值,即保留最后一个值
# 方式一:列表创建方式 data = [['Jack', 10], ['Tom', 12], ['Lucy', 13]] columns = ['Name', 'Age'] df_by_list = pd.DataFrame(data, columns=columns) print(df_by_list) # 方式:字典创建 row = { 'Name': ['Jack', 'Tom', 'Lucy'], 'Age': [10, 12, 13] } df_by_dict = pd.DataFrame(row) print(df_by_dict)
获取一行数据:
names = df['Name'].tolist() print(names) ['Jack', 'Tom', 'Lucy']
add 行列数据
增加列(直接加)
df['Gender'] = ['M', 'M', 'F'] print(df) Name Age Gender 0 Jack 10 M 1 Tom 12 M 2 Lucy 13 F
增加列 (insert 指定index)
df.insert(0, 'Gender', ['M', 'M', 'F']) # df.insert(位置, 列名, value) print(df) Gender Name Age 0 M Jack 10 1 M Tom 12 2 F Lucy 13
增加行 (loc)或(iloc):loc根据列名,iloc根据索引
df.loc[len(df.index)] = ('Lily', 20) print(df) Name Age 0 Jack 10 1 Tom 12 2 Lucy 13 3 Lily 20
修改行(loc)
df.loc[1] = ('Lily', 20) print(df) Name Age 0 Jack 10 1 Lily 20 2 Lucy 13
增加多行 (concat)
data1 = [['Lily', 23], ['Sam', 35]] columns1 = ['Name', 'Age'] df1 = pd.DataFrame(data1, columns=columns1) df2 = pd.concat([df, df1], ignore_index=True) print(df2) Name Age 0 Jack 10 1 Tom 12 2 Lucy 13 3 Lily 23 4 Sam 35 concat 要求具有相同的列名
update 更新数据
更新整行值 (A-dataframe修改B)
data1 = [['Lily', 23], ['Sam', 35]] columns1 = ['Name', 'Age'] new_df = pd.DataFrame(data1, columns=columns1) df.update(new_df) print(df) Name Age 0 Lily 23.0 1 Sam 35.0 2 Lucy 13.0
更新某个值 (loc)
df.loc[0, 'Age'] = 25 # df.loc[row名, col名] = number print(df) Name Age 0 Jack 25 1 Tom 12 2 Lucy 13
delete 删除数据
删除行(drop)
df = df.drop(df[(df['Age'] > 10) & (df['Age'] < 13)].index) # df = df.drop(0) 删除第0行 print(df) Name Age 0 Jack 10 2 Lucy 13
删除列 (drop)
df = df.drop('Age', axis=1) print(df) Name 0 Jack 1 Tom 2 Lucy
dataframe常用方法
遍历 (iterrows)
for index, row in df.iterrows(): print(index) print(row['Name']) print(row['Age'])
索引操作 (重设索引)
import pandas as pd data = [['Jack', '数学', 100],['Jack', '语文', 90], ['Jack', '英语', 80], ['Tom', '英语', 89], ['Lucy', '数学', 99]] # columns = ['Name', 'Age'] df_by_list = pd.DataFrame(data,columns=['姓名', '学科', '成绩']) df_by_list = df_by_list.set_index(['姓名']) print(df_by_list) 学科 成绩 姓名 Jack 数学 100 Jack 语文 90 Jack 英语 80 Tom 英语 89 Lucy 数学 99
映射 (map)
import pandas as pd data = [['Jack', '数学', 100],['Jack', '语文', 90], ['Jack', '英语', 80], ['Tom', '英语', 89], ['Lucy', '数学', 99]] # columns = ['Name', 'Age'] df_by_list = pd.DataFrame(data,columns=['姓名', '学科', '成绩']) df_by_list = df_by_list.set_index(['姓名']) print(df_by_list) df = df_by_list.groupby('姓名')['成绩'].sum().reset_index() print(df) dic = dict(zip(df['姓名'], df['成绩'])) print(dic) # key.map df_by_list['new'] = df_by_list.index.map(dic) """ 学科 成绩 姓名 Jack 数学 100 Jack 语文 90 Jack 英语 80 Tom 英语 89 Lucy 数学 99 姓名 成绩 0 Jack 270 1 Lucy 99 2 Tom 89 {'Jack': 270, 'Lucy': 99, 'Tom': 89} 学科 成绩 new 姓名 Jack 数学 100 270 Jack 语文 90 270 Jack 英语 80 270 Tom 英语 89 89 Lucy 数学 99 99 """
loc与iloc使用场景
两者唯一的区别就是 前者需要名称来查询。不适合复杂行列名的搜索。或者不清楚行列名的情况。一般这种情况 需要iloc以index去查找。
loc的使用情景 (名称)
df.loc[x, y]:
当x, y 都为单值时。该语句代表 行名为x 与 列名为y 的一个cell
df.loc[x]:
当只有x值时。获取 行名为x的 一行 返回值为series,并非dataframe。
df.loc[a:b,c:d]:
loc可以限制行列名的一个范围数据。
注意 loc中 时行列的名称。
iloc的使用场景 (索引)
df.iloc[x,y]: 起始值为0
当x, y 都为单值时。 该语句代表 x行y列 的一个cell
df.iloc[x]:
当只有x值时。获取第x行 返回值为series。
df.iloc[:,:]: ...
pandas将处理完成得dataframe变成python dict进行之后得逻辑处理。
df.to_dict(orient='records')
