day9-为什么需要线程锁(互斥锁)
产生背景
上一节中,每个线程互相独立。相互之间没有任何关系。但是一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时修改同一份数据,会出现什么问题呢?
现在假设这样一个例子:有一个全局的计数num,每个线程获取这个全局的计数,根据num进行一些处理,然后将num加1:
#-*- coding:utf-8 -*-
import threading, time
num = 0 #设定一个共享变量
def run(n):
global num #在每个线程中都获取这个全局变量
time.sleep(1)
num +=1 #对此全局变量进行+1操作
t_obj =[]
for i in range(500):
t = threading.Thread(target=run, args=("t-%s" % i,))
t.start()
t_obj.append(t) #为了不阻塞后面线程的启动,不在这里join(),先放在列表里
for t in t_obj: #循环线程实例列表,等待所有线程执行完毕
t.join()
print("--------all thread has been finished", threading.current_thread(), threading.active_count()) # 查看线程类型和当前活动的线程个数
print("num:",num)
#运行输出1
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 496)
#运行输出2
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 494)
#运行输出3
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 500)
#运行输出4
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 494)
#运行输出5
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 446)
解析:可以看出我们在python2.7上运行了多次500个线程,会发现,最后打印出来的结果不总是500,为什么每次打印出来的结果都不一样呢? 假设你有A,B两个线程,此时都要对num进行加1的操作,由于2个线程是并发同时运行的,所以2个线程很有可能同时拿走了num=0这个初始变量交给CPU进行运算,当A线程去处理完的结果是1,但同时B线程运算完的结果也是1,两个线程同时进行CPU运算的结果再赋值给num变量后,结果都是1,那怎么办呢?产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期。这种现象称为"线程不安全"
解决方案:为了避免自己在还没改完的时候别人也来修改此数据,可以给这个数据加一把锁,这样其他线程想修改此数据时就必须等待你修改完毕并把锁释放后才能再访问该数据。
注意:不要在3.x上运行,3.x上的结果总是正确的,可能是新版本自动加了锁
互斥锁(Mutex)
疑问?
可能有人会问,前面刚刚说过Python使用GIL全局解释器锁来保证在同一时间只能有一个线程执行,这里对共享数据的修改为什么还需要加锁?这里的锁是用户级的锁,具体我们看一下数据操作的流程图:
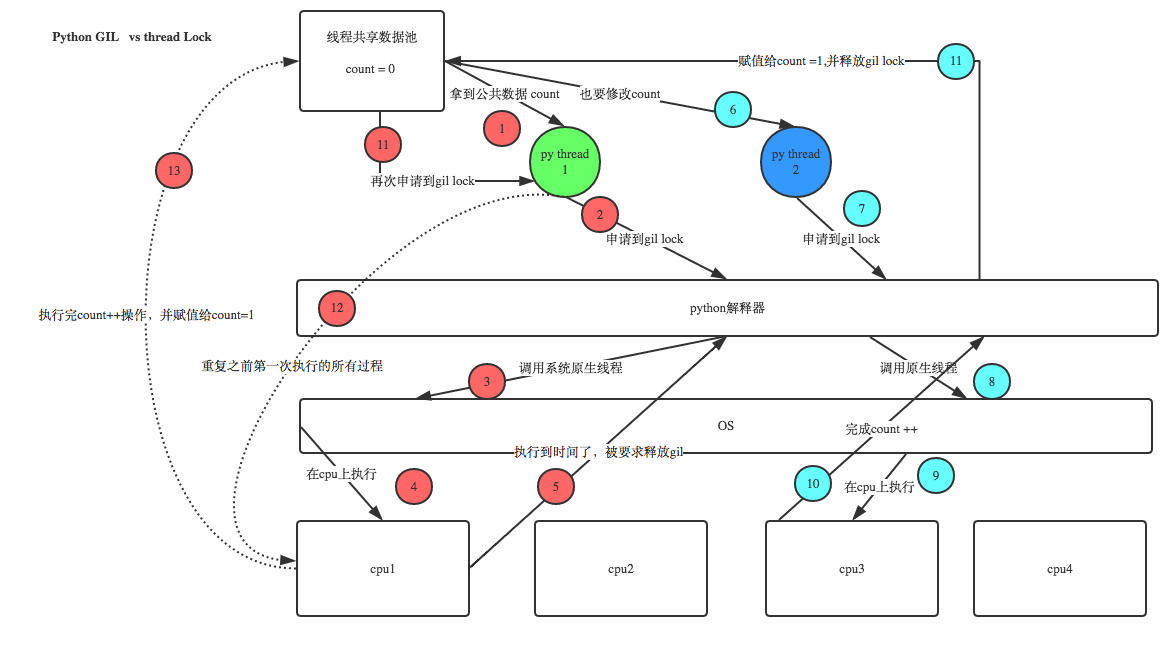
原理解析:
在启动了多个线程对公共变量进行加1操作
第一阶段:
[第1步]线程1拿到了count=0的公共变量=>>[第2步]申请GIL锁(确保同一时间只有一个线程)=>>[第3步]调用系统原生线程=>>[第4步]在CPU上执行运算=>>[第5步]加1的运算可能还没有完成,GIL就要求被释放(Python2.7上的解释器有规律的释放和回收锁——默认情况下,每100字节指令集循环一次),此时该线程被sleep,相当于挂起状态,并把上下文数据存在CPU的某个寄存器中。
第二阶段:
[第6步]线程2也拿到了count=0的公共变量(由于线程1没有执行完)=>>[第7步]申请GIL锁(确保同一时间只有一个线程)=>>[第8步]调用系统原生线程=>>[第9步]在CPU上执行运算=>>[第10步]运算由于执行速度的特别快,已经完成加1操作,GIL也还没有被释放=>>[第11步]将count=1返回赋给公共变量count并释放GIL锁
第三阶段:
[第11步]线程1此时又申请到了GIL锁=>>[第12步:重复3/4过程]完成加1操作(继续之前中断的操作从CPU中取出并执行之前的上下文的数据)=>>[第13步]将count=1返回赋给公共变量count并释放GIL锁。
所以问题就来了,因为第二阶段,线程2返回赋给公共变量的值count已经为1了,第三阶段执行完后,又把线程1的结果1赋给了公共变量count,把第二阶段的count值覆盖了,count=1。归根结底还是公共变量在多个线程对其进行操作时没有被保护起来,造成操作的不一致。所以我们有一开始有2种解决方案:
1、使用join()让程序实现串行,线程1没有执行完,线程2,。。。。不执行。这种方案显然能解决我们的问题,但是整个程序就变成串行的了。
2、我只想在修改数据这一小块串行,那么可以仅对数据的修改进行加锁操作(用户级别的锁:保证同一时间只有一个线程修改公共变量的数据)。
加锁步骤
生成锁的实例=>申请锁(数据只能被我修改)=>对数据进行修改=>释放锁(让别的线程也可以申请)
说明:在修改公共数据时,将程序变成串行实现需求
#-*- coding:utf-8 -*-
import threading, time
lock = threading.Lock() #生成锁的实例
num = 0
def run(n):
lock.acquire() #获取锁
global num
#time.sleep(1) #如果加上sleep,那么就要等500s程序才能执行完,因为锁没有释放,别的线程无法操作,只能等待。。。。
num +=1
lock.release() #释放锁
t_obj =[]
for i in range(100):
t = threading.Thread(target=run, args=("t-%s" % i,))
t.start()
t_obj.append(t) #为了不阻塞后面线程的启动,不在这里join(),先放在列表里
for t in t_obj: #循环线程实例列表,等待所有线程执行完毕
t.join()
print("--------all thread has been finished", threading.current_thread(), threading.active_count()) # 查看线程类型和当前活动的线程个数
print("num:",num)
#运行输出1
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 500)
#运行输出2
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 500)
#运行输出3
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 500)
#运行输出4
('--------all thread has been finished', <_MainThread(MainThread, started 140736094622528)>, 1)
('num:', 500)
解析:程序这里如果加join()是为了让500个线程都执行完并返回结果,如果不加join(),那么可能num的值为0,因为主线程运行的速度很快,它不管子线程的运行结束与否,这时候,500个线程就会还没有对其进行加1的操作就被迫中断了而退出程序。
注:以上所有程序运行环境为Python2.x,如果在Python3.x上,也得加上互斥锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号