
MySQL基础(四)
内容概要
- 查询关键字
- 多表查询思路
- 多表查询练习题
- 可视化软件navicat
查询关键字
查询关键字之having过滤
having与where的功能是一模一样的 都是对数据进行筛选
where用在分组之前的筛选
havng用在分组之后的筛选
为了更好的区分 所以将where说成筛选 havng说成过滤
# 统计每个部门年龄在30岁以上的员工的平均薪资并且保留平均薪资大于10000的部门
'''编写SQL语句 不要指望着一步到位 边写边看慢慢拼凑'''
# 1.先获取每个部门年龄在30岁以上的员工的平均薪资
先筛选出30岁以上的员工数据 然后再对数据进行分组
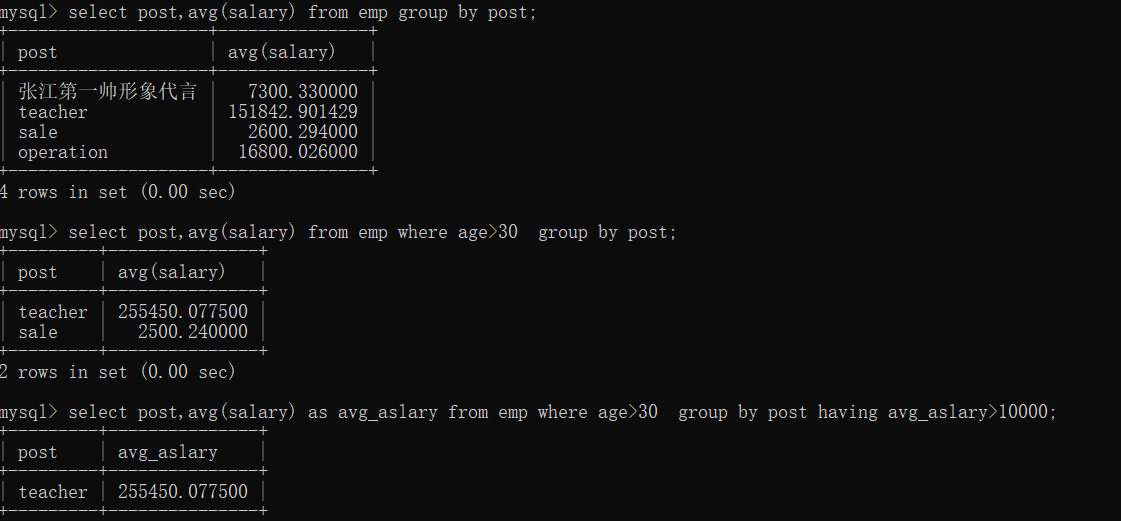
select post,avg(salary) from emp where age>30 group by post;
# 2.在过滤出平均薪资大于10000的数据
针对分组之后的数据再次筛选 需要使用having而不是where
select post,avg(salary) from emp
where age>30
group by post
having avg(salary) > 10000
;
'''针对聚合函数 如果还需要在其他地方作为条件使用 可以先起别名'''
select post,avg(salary) as avg_salary from emp
where age>30
group by post
having avg_salary > 10000
;
查询关键字之distinct去重
# 去重的前提 数据必须是一模一样的才可以(如果数据有主键肯定无法去重)
select distinct age from emp;
"""
在django orm之中 数据会被封装成对象
那个时候主键很容易被我们忽略 从而导致去重没有效果!!!
"""
查询关键字之order by排序
# 1.按照薪资高低排序
select * from emp order by salary; # 默认是升序(从小到大)
select * from emp order by salary asc; # 关键字asc 可以省略
select * from emp order by salary desc; # 降序(从大到小)
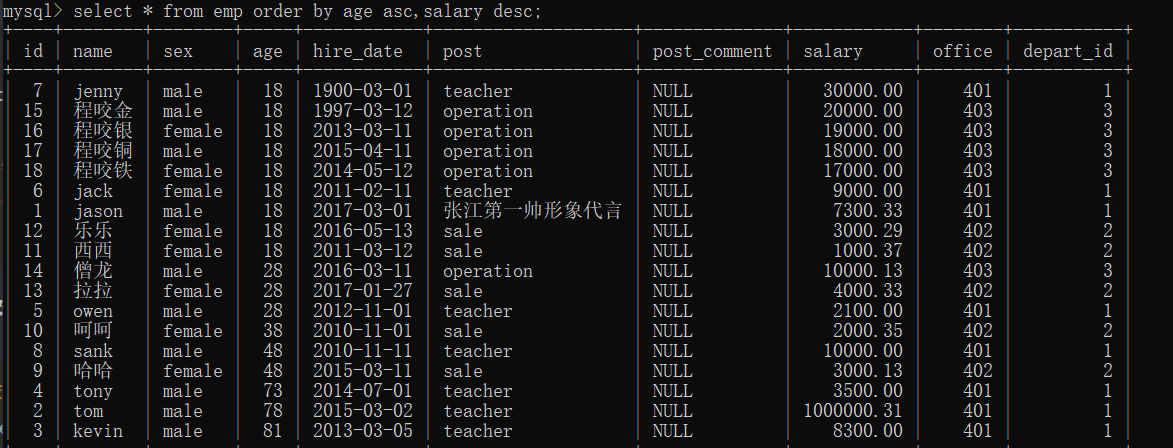
# 2.先按照年龄升序排序 如果年龄相同 则再按照薪资降序排序
select * from emp order by age asc,salary desc;
# 3.统计各部门年龄在10岁以上的员工平均工资 并且保留平均工资大于1000的部门并按照从大到小的顺序排序
select age,avg(salary) as avg_salary
from emp where age>10 group by post
having avg_salary>1000
order by salary desc;

查询关键字之limit分页
# 分页即限制展示条数
# 1.限制只展示五条数据
select * from emp limit 5; # 展示前五条
# 2.分页效果
select * from emp limit 5,5; # 从第五条往后展示五条
# 3.查询工资最高的人的详细信息
select * from emp order by salary desc limit 1;
"""
当数据特别多的时候 经常使用limit来限制展示条数 节省资源 防止系统崩溃
"""



查询关键字之regexp正则
select * from emp where name regexp '^t.*(m|y)$';
"""
补充说明:我们目前所讲的是MySQL查询关键字中使用频率较高的一些
其实还有一些关键字目前无需讲解 并且SQL语句里面同样还支持流程控制语法
如果感兴趣的话 课后可以自行百度查看 非常简单!!!
"""

多表查询思路
# 多表查询的思路总共就两种
1.子查询
就相当于是我们日常生活中解决问题的方式(一步步解决)
将一条SQL语句的查询结果加括号当做另外一条SQL语句的查询条件
eg:以昨天的员工表和部门表为例 查询jason所在的部门名称
子查询的步骤
1.先查jason所在的部门编号
2.根据部门编号去部门表中查找部门名称
2.连表操作
先将多张表拼接到一起 形成一张大表 然后基于单表查询获取数据
eg:以昨天的员工表和部门表为例 查询jason所在的部门名称
连表操作
1.先将员工表和部门表按照某个字段拼接到一起
2.基于单表查询
# 实际演练
create table dep(
id int primary key auto_increment,
name varchar(32)
);
create table emp(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female','others') default 'male',
age int,
dep_id int
);
insert into dep values
(200,'技术'),(201,'人力资源'),
(202,'销售'),(203,'运营'),(205,'安保');
insert into emp(name,age,dep_id) values
('jason',18,200),('tony',28,201),('oscar',38,201),
('jerry',29,202),('kevin',39,203),('jack',48,204);
# 使用子查询 获取jason所在的部门名称
1.先获取jason的部门编号
select dep_id from emp where name='jason'; # dep_id 200
2.根据编号查找部门名称 将第一步的结果放到括号里作为查询条件
select name from dep where id=(select dep_id from emp where name='jason');

多表查连表操作
# 使用连表操作 获取jason所在的部门名称
笛卡尔积(了解知识)
select * from emp,dep; # 会将所有的数据全部对应一遍
select * from emp,dep where emp.dep_id=dep.id; # 效率低下
"""
1.一条SQL语句的查询结果 我们也可以看成是一张虚拟表
2.如果一条SQL语句中设计到多张表的字段名称编写 建议使用表名前缀做区分
"""
连表操作有四个关键字
inner join 内连接
select * from emp inner join dep on emp.dep_id=dep.id;
'''只连接两张表中有对应关系的数据'''
left join 左连接
select * from emp left join dep on emp.dep_id=dep.id;
'''以左表为基准 展示所有的数据 没有对应项则用NULL填充'''
right join 右连接
select * from emp right join dep on emp.dep_id=dep.id;
'''以右表为基准 展示所有的数据 没有对应项则用NULL填充'''
union 全连接
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
'''左右两表数据全部展示 没有对应项则用NULL填充'''
# 使用连表操作 获取jason所在的部门名称
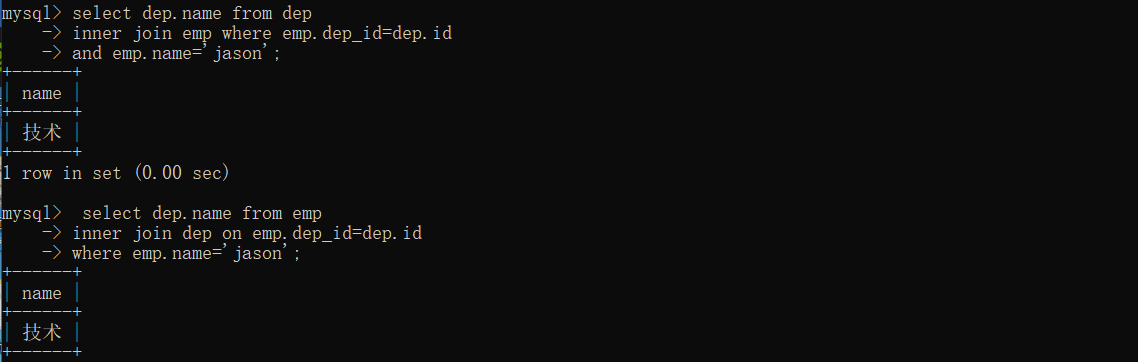
答案1:
select dep.name from dep
inner join emp where emp.dep_id=dep.id
and emp.name='jason';
答案2:
select dep.name from emp
inner join dep on emp.dep_id=dep.id
where emp.name='jason';
"""
了解
我们学会了连表操作之后 其实就可以将N多张表拼接到一起
思路:我们可以将两张表拼接之后的结果起别名当做一张表使用
然后再去跟另外一张表拼接
select * from emp inner join
(select emp.id as epd,emp.name,dep.id from emp inner join dep on emp.dep_id=dep.id) as t1
on emp.id=t1.epd;
"""
多表查询练习题
数据:
/*
数据导入:
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50624
Source Host : localhost
Source Database : sqlexam
Target Server Type : MySQL
Target Server Version : 50624
File Encoding : utf-8
Date: 10/21/2016 06:46:46 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `class`
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `class`
-- ----------------------------
BEGIN;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
COMMIT;
-- ----------------------------
-- Table structure for `course`
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `course`
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
COMMIT;
-- ----------------------------
-- Table structure for `score`
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `score`
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
COMMIT;
-- ----------------------------
-- Table structure for `student`
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `student`
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
COMMIT;
-- ----------------------------
-- Table structure for `teacher`
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `teacher`
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
表间结构图:
1、查询所有的课程的名称以及对应的任课老师姓名
2、查询平均成绩大于八十分的同学的姓名和平均成绩
3、查询没有报李平老师课的学生姓名
4、查询没有同时选修物理课程和体育课程的学生姓名
5、查询挂科超过两门(包括两门)的学生姓名和班级
1、查询所有的课程的名称以及对应的任课老师姓名
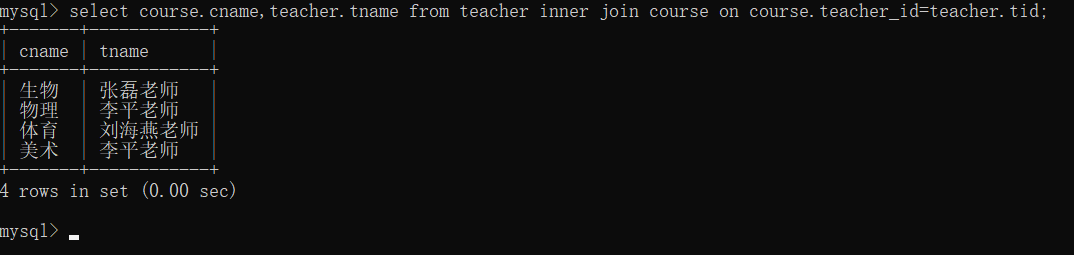
# 1、查询所有的课程的名称以及对应的任课老师姓名
1.先明确需要几张表 course表 teacher表
2.大致查找一些表中的数据情况
3.既然是多表查询 那么查询思路 子查询 连表操作(复杂的SQL需要两者配合使用)
4.编写完成后 如果是navercat 使用美化功能 将SQL语句规范化
select course.cname,teacher.tname
from teacher inner join course
on course.teacher_id=teacher.tid;
2、查询平均成绩大于八十分的同学的姓名和平均成绩
# 1.先明确需要用到几张表 student score
# 2.大致查看一下两张表里面的数据
# 3.先获取平均成绩大于80分的学生信息(按照student_id分组)
select score.student_id,avg(num) as avg_num
from score group by score.student_id
having avg_num>80;
# 4.结果需要从两个表里面的获取 student SQL语句执行之后的虚拟表
select student.sname,t1.avg_num
from student
inner join (select student_id,avg(num) as avg_num from score
group by score.student_id having avg_num > 80) as t1
on student.sid = t1.student_id;

3、查询没有报李平老师课的学生姓名
# 此题有两种思路 第一种是正向查询 第二种是反向查询(先查所有报了李平老师课程的学生id 之后取反即可)
# 1.先明确需要用到几张表 四张表
# 2.先查询李平老师的编号
select tid from teacher where tname='李平老师'
# 3.再查李平老师教授的课程编号
select cid from course where teacher_id=(select tid from teacher where tname='李平老师')
# 4.根据课程编号 去score表中筛选出所有选了课程的学生编号
select distinct student_id from score where course_id in (select cid from course where teacher_id=(select tid from teacher where tname='李平老师'));
# 5.根据学生编号去学生表中反向筛选出没有报李平老师课程的学生姓名
select sname
from student
where
sid not in (select distinct student_id from score where course_id in (select cid from course where teacher_id = (select tid from teacher where tname = '李平老师')));
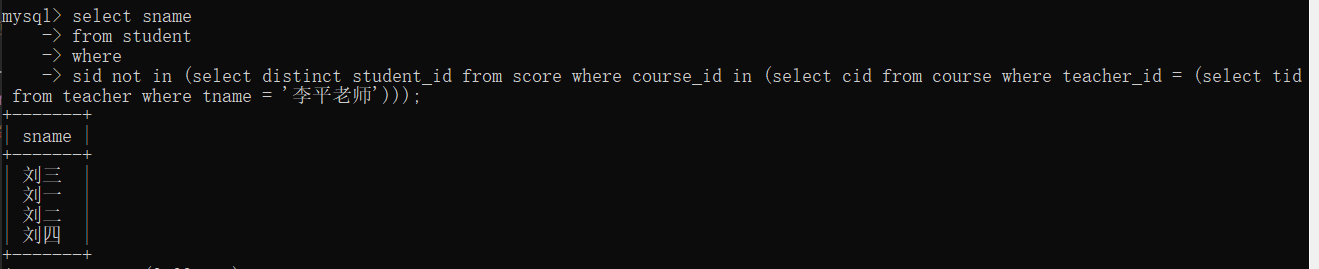
4、查询没有同时选修物理课程和体育课程的学生姓名
# 查询没有同时选修物理课程和体育课程的学生姓名(两门都选了和一门都没选的 都不要 只要选了一门)
# 1.先明确需要用到几张表 三张
# 2.先获取物理课程和体育课程的编号
select cid from course where cname in ('物理','体育');
# 3.再去分数表中筛选出选了物理和体育的数据(包含了选了一门和两门 没有选的就已经被排除了)
select * from score where course_id in (select cid from course where cname in ('物理','体育'))
# 4.如何剔除选了两门的数据(按照学生id分组 然后对课程计数即可)
select student_id from score where course_id in (select cid from course where cname in ('物理','体育'))
group by student_id HAVING count(course_id) = 1;
# 5.根据上述学生id号筛选出学生姓名
select sname from student where
sid in (select student_id from score where course_id in (select cid from course where cname in ('物理','体育'))
group by student_id
having count(course_id) = 1
);

5、查询挂科超过两门(包括两门)的学生姓名和班级
# 1.先明确需要几张表 三张表
# 2.先去score表中筛选出所有不及格的数据
select * from score where num < 60;
# 3.如何筛选每个学生挂科的门数(按照学生id分组 对学科计数即可)
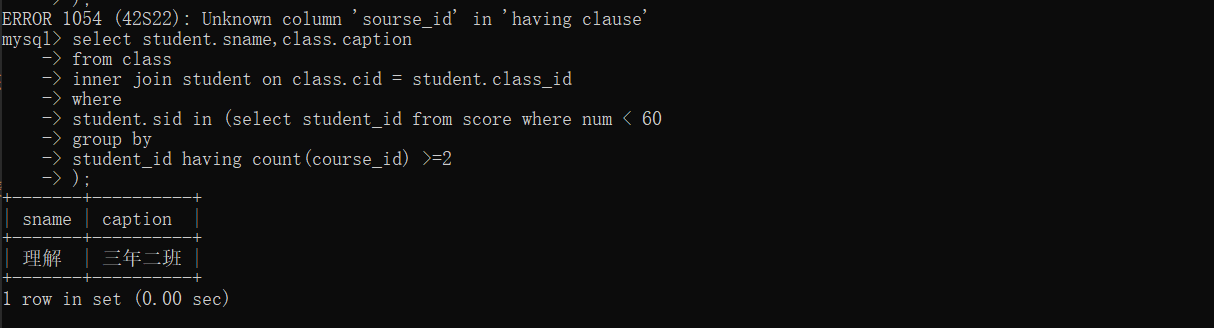
select student_id from score where num < 60 group by student_id
HAVING count(course_id) >= 2;
# 4.由于最终的结果需要取自两张表 所以应该拼接
select student.sname,class.caption from class inner join student on class.cid=student.class_id;
# 5.使用步骤3获取到的学生编号 对步骤4的表结果筛选数据
select student.sname,class.caption
from class
inner join student on class.cid = student.class_id
where
student.sid in (select student_id from score where num < 60
group by
student_id having count(course_id) >=2
);
补充:
"""
重点掌握上述五道题目即可 如果还想扩展 可以考虑下面的题目
https://www.cnblogs.com/Dominic-Ji/p/10875493.html
只需要完成三分之一及以上即可!!!
"""
可视化软件navicat
Navicat可以充当很多数据库软件的客户端 提供了图形化界面能够让我们更加快速的操作数据库
# 下载
navicat有很多版本 并且默认都是收费使用
正版可以免费体验14天
针对这种图形化软件 版本越新越好(不同版本图标颜色不一样 但是主题功能是一样的)
# 破解方式
https://www.cnblogs.com/article-record/articles/11327302.html
# 使用
内部封装了SQL语句 用户只需要鼠标点点点就可以快速操作
连接数据库 创建库和表 录入数据 操作数据
外键 SQL文件 逆向数据库到模型 查询(自己写SQL语句)
# 使用navicat编写SQL 如果自动补全语句 那么关键字都会变大写
SQL语句注释语法(快捷键与pycharm中的一致 ctrl+?)
#
--
# 运行SQL文件
本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/16242132.html

