
MySQL基础(二)
内容概要
- 字符编码与配置文件介绍
- 存储引擎
- MySQL字段类型
- MySQL字段的约束条件
字符编码与配置文件
# 查看MySQL默认的字符编码 \s """ 如果MySQL版本是5.x系列 显示的编码有多种 latin1 gbk 如果MySQL版本是8.x系列 显示的统一是utf8mb4 utf8mb4是utf8的优化版本 支持存储表情 """ # 统一字符编码 MySQL版本中5.x系列默认编码有多种 有可能会导致乱码的情况 所以要统一编码 找到>>>: my-default.ini配置文件 "步骤" 1.拷贝一份该配置文件并修改名称为my.ini 2.清空my.ini文件里边的内容 3.在里边添加固定的配置信息即可: [mysqld] character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8 [mysql] default-character-set=utf8 4.保存并重启服务端即可生效 关闭服务:net stop mysql 启动服务:net start mysql
存储引擎
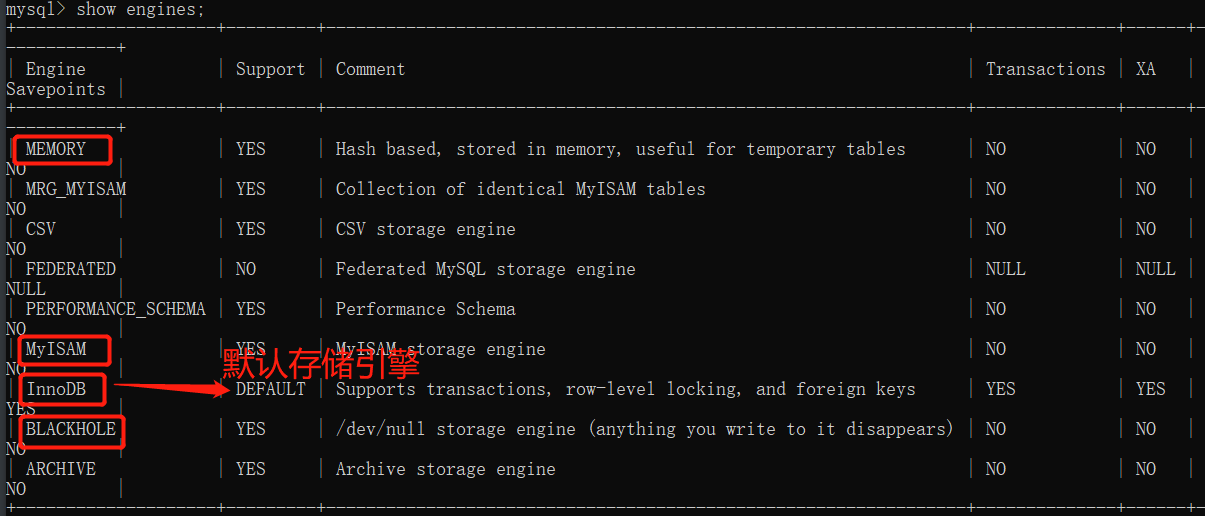
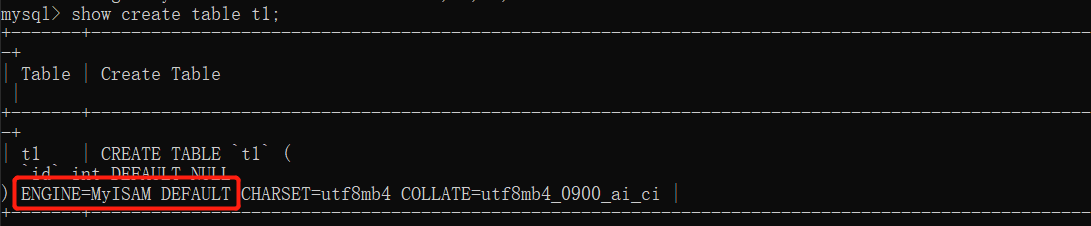
# 什么是存储引擎 存储引擎可以理解为处理数据的不同方式 eg: 有一个a.txt文件 不同的人会拿它干不同的事 路人甲A会将其放入密码箱中 路人甲B会将其转换成PDF格式存储 路人甲C会将其进行备份 ... # 查看存储引擎 只要在mysql命令行中输入: show engines; 看你的mysql当前默认的存储引擎: show variables like '%storage_engine%'; 你要看某个表用了什么引擎: show create table 表名; # 需要了解的引擎 MyISAM 5.1之前版本MySQL默认的存储引擎 特点:存储数据的速度快 但是功能很少 安全属性较低 InnoDB 5.1之后的版本MySQL默认的存储引擎 特点:有诸多功能 安全性较高 存取速度没有MyISAM快 BlackHole 特点:任何写入的数据都会立刻消失(类似于垃圾回收处理站) Memory 特点:以内存作为数据存储地 速度快但是断电数据立刻丢失 # 自定义选择存储引擎 create table t1(id int)engine=myisam; create table t2(id int)engine=innodb; create table t3(id int)engine=blackhole; create table t4(id int)engine=memory;

创建表的完整语法
create table 表名( 字段名1 字段类型(数字) 约束条件, 字段名2 字段类型(数字) 约束条件, 字段名3 字段类型(数字) 约束条件, ); 使用说明: 1.字段名和字段类型是必须要有的 2.数字和约束条件可以选择不写 3.约束条件可以写多个 用空格隔开即可 "字段名1 字段类型(数字) 约束条件1 约束条件2 约束条件3" 4.最后字段结尾不能有逗号
字段类型
字段类型:整型
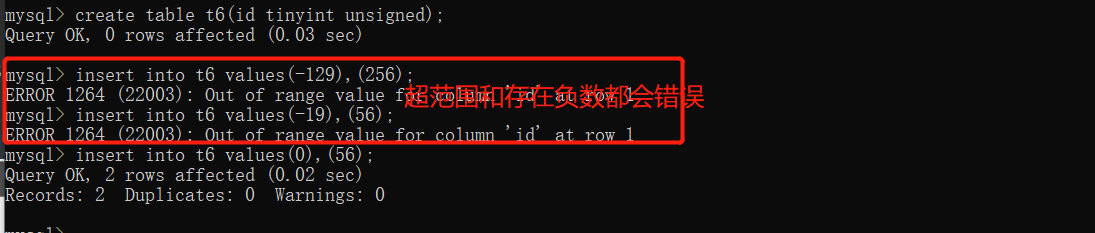
# 整型 tinyint 1bytes smallint 2bytes int 4bytes bigint 8bytes mediumint (不会用到) 上述整型的区别在于从上往下能够存储的数字范围越来越大 注意事项 1.需要考虑正负数的问题 如果需要存储负数 则需要占据一个比特位 2.注意手机号如果使用整型来存储 需要使用bigint才可以 """ 工作小技巧:有时候看似需要使用数字类型存储的数据其实可能使用的是字符串 因为字符串可以解决不同语言对数字不精确的缺陷!!! """ create table t5(id tinyint); insert into t5 values(-129),(256); # 超出数值范围 # 如果是在5.6版本不会报错 会自动处理成最大范围(没有意义) 步骤1:set global sql_mode = 'STRICT_TRANS_TABLES'; 步骤2:退出客户端 重新登录即可 # 如果是在5.7及以上版本 则会直接报错(更加合理) "unsigned" 验证(结论)发现所有的整型都默认带有正负号 如何修改不带正负号(约束条件) create table t6(id tinyint unsigned);
参考表: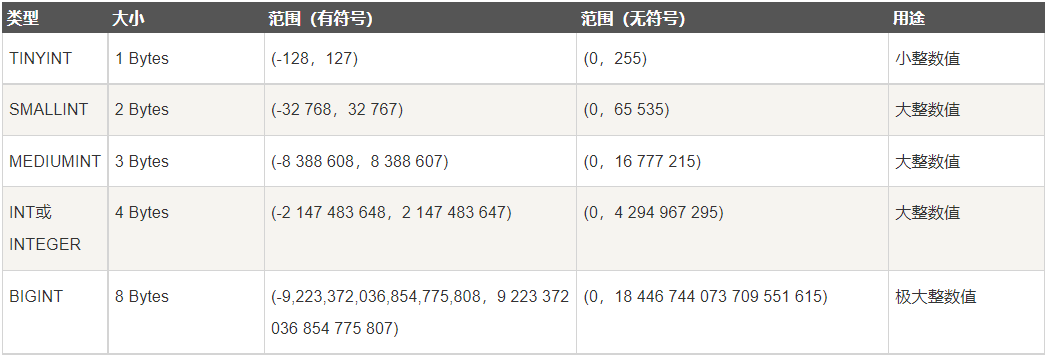
字段类型:浮点型
# 浮点型 float double decimal 上述浮点型从上往下精确度越来越高 float(255,30) 总共255位 小数位占30位 double(255,30) 总共255位 小数位占30位 decimal(65,30) 总共65位 小数位占30位 重点研究精确度问题 create table t7(id float(255,30)); create table t8(id double(255,30)); create table t9(id decimal(65,30)); insert into t7 values(1.11111111111111111); insert into t8 values(1.11111111111111111); insert into t9 values(1.11111111111111111); 精度: decimal>double>float """ 虽然三者精确度有差距 但是具体用哪个应该结合实际情况 比如正常业务 使用float足够 如果是高精尖 可以使用decimal """

参考表:
字段类型:字符类型
# 字符类型 char varchar 上述两个字符类型的区别在于char是定长 varchar是变长 eg: char(4) 定长 最大只能存储四个字符 超出则报错 不够则空格填充至四个 varchar(4) 变长 最大只能存储四个字符 超出则报错 不够则有几个存几个 # 验证定长与变长特性 create table t10(name char(4)); create table t11(name varchar(4)); insert into t10 values('jason'); insert into t11 values('jason'); # 如果是5.6版本并且没有修改严格模式 则会自动截取四个字符(不合理) # 临时修改 步骤1:set global sql_mode = 'STRICT_TRANS_TABLES'; 步骤2:退出客户端 重新登录即可 # 永久修改 修改my.ini配置文件 sql_mode = 'STRICT_TRANS_TABLES,ONLY_FULL_GROUP_BY' 重启服务端之后永久生效 """ 课外扩展研究 char_length() 获取字段数据的长度 该方法无法直接获取到定长的真实长度 因为MySQL在存数据的时候会自动填充空格在取数据的时候又会自动移除空格 能不能让MySQL在取数据的时候不自动移除空格 单次修改 set session sql_mode = 'pad_char_to_full_length' """ # 工作中使用char还是varchar char 整存整取 速度快 会造成一定的存储空间浪费 ''' jasonkevintony tom jerry ''' varchar 节省存储空间 存取数据的速度没有char快(取数据不知道数据的精确长度) ''' varchar在存数据的时候会生成一个1bytes的报头 记录数据长度 varchar在取数据的时候先会读取1bytes的报头 从中获取真实数据长度 1bytesjason1bytes+kevin1bytes+tony ''' # 以前几乎使用的都是char 现在varchar使用频率也越来越高 """ 两者都有使用场景 比如: 针对统一中国人的姓名 应该采取那个类型 >>> varchar 规模较小 数据量相对固定的字典 >>> char 很多时候字段类型的选取和命名都会在邮件中标明(组长、架构师、产品) """
参考表:
拓展:
""" sql_mode补充 1.如何查看 show variables like '%mode%' 2.单次修改(仅限于当前登录) set session sql_mode = '...' 3.临时修改(仅限于当前服务) set global sql_mode = '...' 4.永久修改 在配置文件中的[mysqld]下面添加 """
字段类型:枚举与集合
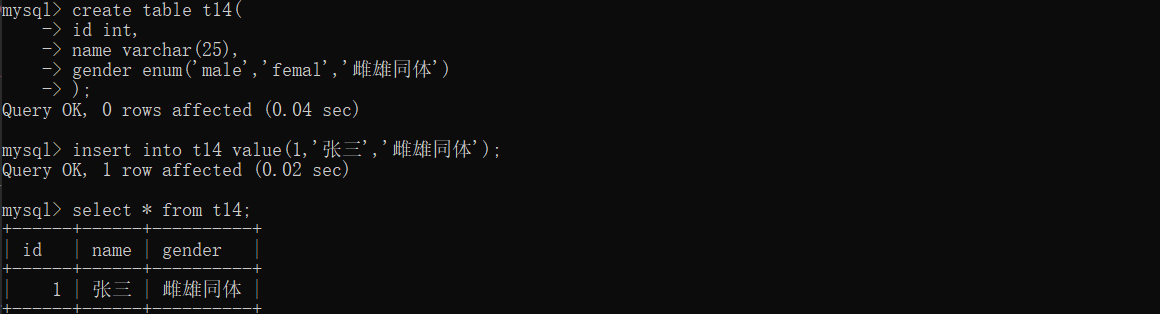
# 枚举 多选一 create table t14( id int, name varchar(32), gender enum('male','female','others') ); '''插入数据的时候 针对gender只能填写提前定义好的数值''' # 集合 多选多(也可以多选一) create table t15( id int, name varchar(32), hobby set('篮球','足球','双色球','排球','水球','肉球') );


字段类型:日期类型
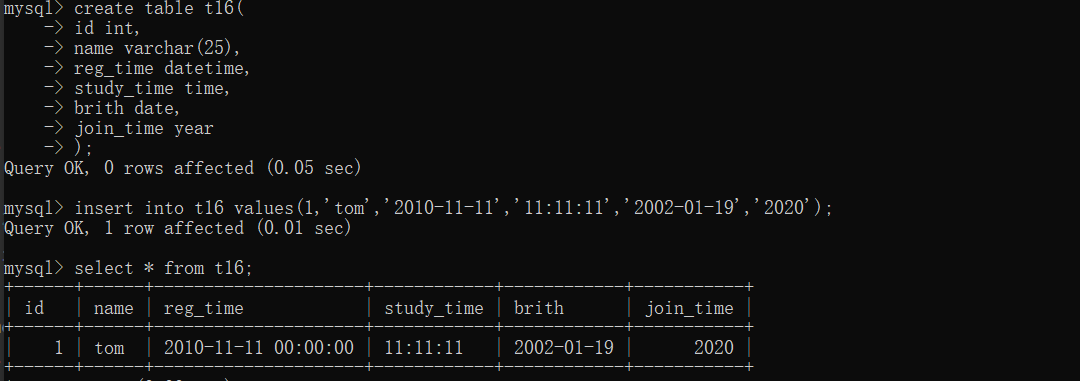
# 日期类型 date 年月日 datetime 年月日时分秒 time 时分秒 year 年 create table t16( -> id int, -> name varchar(25), -> reg_time datetime, -> study_time time, -> brith date, -> join_time year -> ); # 针对时间数据一般都是通过代码自动获取并添加 我们这里手动模拟 insert into t16 values(1,'tom','2010-11-11','11:11:11','2002-01-19','2020');
约束条件
# 字段类型与约束条件的关系 约束条件是基于字段类型之上的额外限制 eg: id int unsigned 字段类型int规定了id字段只能存整数 约束条件unsigned指的是整数基础之上还必须是正数 # 1.无需正负号 unsigned # 2.零填充 zerofill # 3.非空 not null create table t17(id int,name varchar(32)); '''插入数据的另外一种方式 打破字段顺序''' insert into t17(name,id) values('jason',1); insert into t17(id) values(2); create table t18(id int,name varchar(32) not null); insert into t18(id) values(2); # 报错 insert into t18(id,name) values(2,null); # 报错 insert into t18(id,name) values(2,''); # 不报错 # 4.默认值 default create table t19(id int,name varchar(32) default 'jason'); insert into t19(id) values(1); insert into t19(id,name) values(2,'kevin'); # 5.唯一值 unique '''单列唯一:某个字段下对应的数据不能重复 是唯一的''' create table t20( id int, name varchar(32) unique ); '''多列唯一:多个字段下对应的数据组合到一起的结果不能重复 是唯一的''' create table t21( id int, host varchar(32), port int, unique(host,port) ); # 6.主键 primary key """ 1.单从约束层面上而言 相当于not null + unique(非空且唯一) create table t22(id int primary key); 2.是InnoDB存储引擎规定的一张表有且必须要有一个主键 用于构建表 主键可以加快数据的查询速度(类似于书的目录) 如果创建表创建的时候没有设置主键也没有其他的键 那么InnoDB会采用一个隐藏的字段作为表的主键(隐藏就意味着而无法使用 即无法加快数据查询) 如果没有主键但是有非空且唯一的字段 那么会自动升级成主键(从上往下的第一个) create table t23( tid int, pid int not null unique, cid int not null unique ); """ 结论:创建表应该有一个序号字段(id\pid\cid)并且应该将该字段设置成主键 create table t24( id int primary key, name varchar(32) ); # 也可以有联合主键(多个字段组合 本质还是一个主键) 了解即可 create table t24( id int, name varchar(32), pwd int, primary key(id,pwd) ); # 7.自增 auto_increment 专门配合主键一起使用 用户以后在添加数据的时候就不需要自己记忆主键值 create table t25( id int primary key auto_increment, name varchar(32) ); """ 总结 以后在创建规范的表的时候 一般都会有一个主键字段的编写如下 id int primary key auto_increment """

本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/16222388.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~