
并发编程(end)
内容概要
- GIL与普通互斥锁的区别
- 验证多线程的作用
- 死锁现象(强调锁不能轻易使用)
- 信号量与event事件(了解)
- 进程池与线程池*
- 协程
GIL与普通互斥锁区别
GIL锁
# 1.先验证GIL的存在 from threading import Thread import time money = 100 def task(): global money money -= 1 for i in range(100): # 创建一百个线程 t = Thread(target=task) time.sleep(0.1) t.start() print(money) # 0
普通互斥锁
# 2.再验证不同数据加不同锁 from threading import Thread, Lock import time money = 100 mutex = Lock() def task(): global money mutex.acquire() # 抢锁 tmp = money time.sleep(0.1) money = tmp - 1 mutex.release() # 放锁 """ 抢锁放锁也有简便写法(with上下文管理) with mutex: pass """ t_list = [] for i in range(100): # 创建一百个线程 t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() # 为了确保结构正确 应该等待所有的线程运行完毕再打印money print(money) # 0
GIL总结
""" GIL是一个纯理论知识 在实际工作中根本无需考虑它的存在 GIL作用面很窄 仅限于解释器级别 后期我们要想保证数据的安全应该自定义互斥锁(使用别人封装好的工具) """
验证多线程的作用
""" 两大前提 CPU的个数: 单个、多个 任务的类型: IO密集型、计算密集型 """ # 单个CPU 多个IO密集型任务 多进程:浪费资源 无法利用多个CPU 多线程:节省资源 切换+保存状态 多个计算密集型任务 多进程:耗时更长 创建进程的消耗+切换消耗 多线程:耗时较短 切换消耗 # 多个CPU 多个IO密集型任务 多进程:浪费资源 多个CPU无用武之地 多线程:节省资源 切换+保存状态 多个计算密集型任务 多进程:可以利用多核 速度更快 多线程:速度更慢 结论:多进程和多线程都有具体的应用场景 尤其是多线程并不是没有用!!!
模拟IO密集型
from threading import Thread from multiprocessing import Process import time def work(): time.sleep(2) # 模拟纯IO操作 if __name__ == '__main__': start_time = time.time() # t_list = [] # for i in range(100): # 开100个线程 # t = Thread(target=work) # t.start() # for t in t_list: # t.join() p_list = [] for i in range(100): # 开100个进程 p = Process(target=work) p.start() for p in p_list: p.join() print('总耗时:%s' % (time.time() - start_time)) """ 多线程: 总耗时:0.031211376190185547 多进程: 总耗时:0.8269836902618408 两者差了两个数量级 结论: 多线程更好 """
模拟计算密集型
from threading import Thread from multiprocessing import Process import os import time def work(): res = 1 for i in range(1, 10000): res *= i if __name__ == '__main__': # print(os.cpu_count()) # 12 查看当前计算机CPU个数 start_time = time.time() # p_list = [] # for i in range(12): # p = Process(target=work) # p.start() # p_list.append(p) # for p in p_list: # p.join() t_list = [] for i in range(12): t = Thread(target=work) t.start() t_list.append(t) for t in t_list: t.join() print('总耗时:%s' % (time.time() - start_time)) """ 多进程: 总耗时:0.2017192840576172 多线程: 总耗时:0.7185993194580078 两者差了一个数量级(越多差距越大) 结论: 多进程更好 """
死锁现象
# 锁就算掌握了如何抢 如何放 也会产生死锁现象 from threading import Thread, Lock import time # 产生两把锁 mutexA = Lock() mutexB = Lock() class MyThread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print(f'{self.name}抢到了A锁') mutexB.acquire() print(f'{self.name}抢到了B锁') mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print(f'{self.name}抢到了B锁') time.sleep(2) mutexA.acquire() print(f'{self.name}抢到了A锁') mutexA.release() mutexB.release() for i in range(20): t = MyThread() t.start() """锁不能轻易使用并且以后我们也不会在自己去处理锁都是用别人封装的工具"""

信号量(了解)
信号量在不同的知识体系中 展示出来的功能是不一样的 eg: 在并发编程中信号量意思是多把互斥锁 在django框架中信号量意思是达到某个条件自动触发特定功能 """ 如果将自定义互斥锁比喻成是单个厕所(一个坑位) 那么信号量相当于是公共厕所(多个坑位) """ from threading import Thread, Semaphore import time import random sp = Semaphore(5) # 创建一个有五个坑位(带门的)的公共厕所 def task(name): sp.acquire() # 抢锁 print('%s正在蹲坑' % name) time.sleep(random.randint(1, 5)) sp.release() # 放锁 for i in range(1, 31): t = Thread(target=task, args=('伞兵%s号' % i, )) t.start() # 只要是跟锁相关的几乎都不会让我们自己去写 后期还是用模块

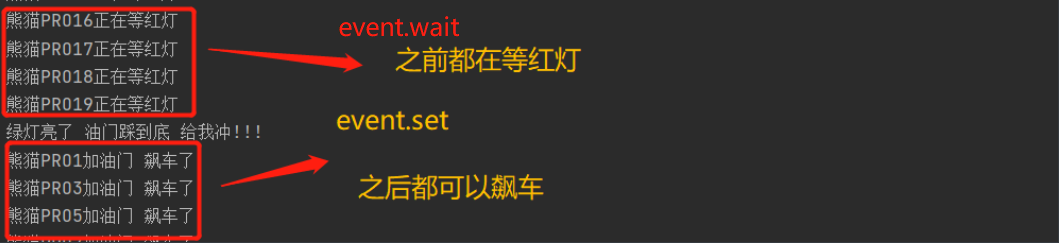
event事件(了解)
from threading import Thread, Event import time event = Event() # 类似于造了一个红绿灯 def light(): print('红灯亮着的 所有人都不能动') time.sleep(3) print('绿灯亮了 油门踩到底 给我冲!!!') event.set() def car(name): print('%s正在等红灯' % name) event.wait() print('%s加油门 飙车了' % name) t = Thread(target=light) t.start() for i in range(20): t = Thread(target=car, args=('熊猫PRO%s' % i,)) t.start()
进程池与线程池*
""" 补充: 服务端必备的三要素 1.24小时不间断提供服务 2.固定的ip和port 3.支持高并发 回顾: TCP服务端实现并发 多进程:来一个客户端就开一个进程(临时工) 多线程:来一个客户端就开一个线程(临时工) 问题: 计算机硬件是有物理极限的 我们不可能无限制的创建进程和线程 措施: 池: 保证计算机硬件安全的情况下提升程序的运行效率 进程池: 提前创建好固定数量的进程 后续反复使用这些进程(合同工) 线程池: 提前创建好固定数量的线程 后续反复使用这些线程(合同工) 如果任务超出了池子里面的最大进程或线程数 则原地等待 强调: 进程池和线程池其实降低了程序的运行效率 但是保证了硬件的安全!!! """
进程池
from concurrent.futures import ProcessPoolExecutor import os import time # 进程池 pool = ProcessPoolExecutor(5) # 进程池进程数默认是CPU个数 也可以自定义 '''上面的代码执行之后就会立刻创建五个等待工作的进程''' def task(n): time.sleep(2) print(n) # print(os.getpid()) return '任务的执行结果:%s'%n**2 def func(*args, **kwargs): # print(args, kwargs) print(args[0].result()) if __name__ == '__main__': # 在Windows中要写在双下mian子代码中 否则会报错 for i in range(20): # res = pool.submit(task, i) # 朝线程池中提交任务(异步) # print(res.result()) # 同步提交(获取任务的返回值) '''不应该自己主动等待结果 应该让异步提交自动提醒>>>:异步回调机制''' pool.submit(task, i).add_done_callback(func) """add_done_callback只要任务有结果了 就会自动调用括号内的函数处理"""

线程池
from concurrent.futures import ThreadPoolExecutor import time import os # 线程池 pool = ThreadPoolExecutor(5) # 线程池线程数默认是CPU个数的五倍 也可以自定义 '''上面的代码执行之后就会立刻创建五个等待工作的线程''' def task(n): time.sleep(2) print(n) # print(os.getpid()) return '任务的执行结果:%s'%n**2 def func(*args, **kwargs): # print(args, kwargs) print(args[0].result()) if __name__ == '__main__': for i in range(20): # res = pool.submit(task, i) # 朝线程池中提交任务(异步) # print(res.result()) # 同步提交(获取任务的返回值) '''不应该自己主动等待结果 应该让异步提交自动提醒>>>:异步回调机制''' pool.submit(task, i).add_done_callback(func) """add_done_callback只要任务有结果了 就会自动调用括号内的函数处理"""

协程
""" 进程:资源单位 线程:执行单位 协程:单线程下实现并发 并发的概念:切换+保存状态 首先需要强调的是协程完全是程序员自己意淫出来的名词!!! 对于操作系统而言之认识进程和线程 协程就是自己通过代码来检测程序的IO操作并自己处理 让CPU感觉不到IO的存在从而最大幅度的占用CPU 类似于一个人同时干接待和服务客人的活 在接待与服务之间来回切换!!! """ # 基本使用 "保存的功能 我们其实接触过 yield 但是无法做到检测IO切换" from gevent import monkey;monkey.patch_all() # 固定编写 用于检测所有的IO操作 from gevent import spawn import time def play(name): print('%s play 1' % name) time.sleep(5) print('%s play 2' % name) def eat(name): print('%s eat 1' % name) time.sleep(3) print('%s eat 2' % name) start_time = time.time() g1 = spawn(play, 'jason') g2 = spawn(eat, 'jason') g1.join() # 等待检测任务执行完毕 g2.join() # 等待检测任务执行完毕 print('总耗时:', time.time() - start_time) # 正常串行肯定是8s+ # 总耗时: 5.019700765609741 代码控制切换
基于协程实现TCP服务端并发
服务端
from gevent import monkey;monkey.patch_all() from gevent import spawn import socket def communication(sock): while True: data = sock.recv(1024) # IO操作 print(data.decode('utf8')) sock.send(data.upper()) def get_server(): server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen(5) while True: sock, addr = server.accept() # IO操作 spawn(communication, sock) g1 = spawn(get_server) g1.join()

客户端
from threading import Thread, current_thread import socket def get_client(): client = socket.socket() client.connect(('127.0.0.1', 8080)) count = 0 while True: msg = '%s say hello %s'%(current_thread().name, count) count += 1 client.send(msg.encode('utf8')) data = client.recv(1024) print(data.decode('utf8')) # 创建诸多线程 for i in range(200): t = Thread(target=get_client) t.start()

结论
""" python可以通过开设多进程 在多进程下开设多线程 在多线程使用协程 从而让程序执行的效率达到极致!!! 但是实际业务中很少需要如此之高的效率(一直占着CPU不放) 因为大部分程序都是IO密集型的 所以协程我们知道它的存在即可 几乎不会真正去自己编写 """
本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/16175917.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律