

函数(七)
内容概要
- 生成器对象(自定义迭代器)
- 自定义range方法
- yield关键字作用
- 生成器表达式
- 模块简介
- 模块的两种导入方式
- 导入补充
生成器对象(自定义迭代器)
# 生成器的本质其实就是一个自己编写的迭代器即自定义迭代器
同样的生成器也有 __iter__ 和 __next__方法
'''生成器对象也是节省存储空间的 特性与迭代器对象一致'''
def lunch():
print('1你吃饭了吗?')
yield 'yes' # yield关键字 每执行一次next就在yield停掉
print('2你吃饭了没?')
yield '我mmp'
print('3你吃了吗')
yield '大郎该吃药了'
print(lunch) # 普通函数<function lunch at 0x000002797CEB70D0>
# 加括号调用并接收结果:不执行代码 而是变成生成器对象(迭代器)
eat = lunch() # 只调用函数不执行
print(eat) # 变为生成器<generator object lunch at 0x000001DA62D23E08>
# print(next(eat)) # 执行next并打印返回值 1你吃饭了吗? yes
# print(next(eat)) # 2你吃饭了没? 我mmp
# print(next(eat)) # 3你吃了吗 大郎该吃药了
# print(next(eat)) # 报错
'''
当函数体代码中含有yield关键字时
调用函数并不会执行函数体代码,而是将其转变为生成器
eat = lunch()
print(eat) # <generator object lunch at 0x000001DA62D23E08>
generator 就是生成器的意思
如果函数体代码中含有多个yield关键字 执行一次__next__返回后面的值并且让代码停留在yield位置
再次执行__next__基于上次的位置继续往后执行到下一个yield关键字处
如果没有了 再执行也会报错 StopIteration
'''
自定义range方法
# range方法其实本身就是一个可迭代对象
"通过用生成器来模拟range方法"
# 先考虑两个参数时
def my_range(start, stop):
while start < stop:
yield start # 每次返回start值
start += 1
for i in my_range(2,10):
print(i) # 2~9
# 考虑到只有一个参数时
def my_range(start, stop=None): # 当只要一个参数时 第二个参数默认None
if not stop:
stop = start
start = 0
while start < stop:
yield start # 每次返回start值
start += 1
for i in my_range(10):
print(i) # 0~9
# 考虑到三个参数
def my_range(start, stop=None,long=1): # 当第三个参数没有 步长默认为一
if not stop:
stop =start
start = 0
while start < stop:
yield start
start += long # 步长 间隔
for i in my_range(1,10,2):
print(i) # 1 3 5 7 9
"这时候可以传一二三个参数都可以"
yield关键字作用
"yield关键字作用"
# 1.在函数体代码中出现 可以将函数变成生成器
# 2.在执行过程中 可以将后面的值返回出去 类似于return
# 3.还可以暂停住代码的运行
# 4.还可以接收外界的传值(了解)
'''作用2 与return的区别在于 return不会执行后边的代码
而yield关键字还会继续执行后边的代码
'''
def lunch(food):
print(f'1你吃{food}了吗?')
good = yield
print(f'2你吃{good}没?')
yield 233
# 想执行一次代码 如果想执行多次直至结束 可以直接用for循环
eat = lunch('shit')
next(eat) # 1你吃shit了吗?
# 可以给yield传值 并且自动调用一次__next__方法
eat.send('生日蛋糕') # 2你吃生日蛋糕没?
生成器表达式
# 也是为了节省存储空间 代码优化时使用
# res = (i for i in 'jason')
# print(res) # <generator object <genexpr> at 0x1130cf468>
# print(res.__next__())
"""生成器内部的代码只有在调用__next__迭代取值的时候才会执行"""
'''面试题'''
# 普通的求和函数
def add(n, i):
return n + i
# 生成器对象 返回 0 1 2 3
def test():
for i in range(4):
yield i
# 将test函数变成生成器对象
g = test()
# 简单的for循环
for n in [1, 10]:
g = (add(n, i) for i in g)
"""
第一次for循环
g = (add(n, i) for i in g)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g))
"""
res = list(g) # list底层就是for循环 相当于对g做了迭代取值操作
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23]
#D. res=[21,22,23,24]
"""正确答案是C 诀窍就是抓n是多少即可"""
模块简介
"""
python之所以很火并且适用于各行各业很大程度上的原因就是>>>:模块
很多大佬写了很多非常牛逼的模块 供python工程师直接使用(白嫖)
eg:
import time 导入模块
time.time() 调用方法
python刚开始出来的时候被很多其他语言的程序员看不起 嘲笑python是一个
调包侠
(只会调用别人写好的东西,拿来主义跟传统价值观不一致>>>:自己动手丰衣足食) 此时的调包侠是贬义词
但是当其他语言的程序员开始写python用到了模块之后发现'真香' 调包侠真好用 真牛逼 我好喜欢 此时的调包侠是褒义词
ps:作为一名python工程师CV大法都要比其他工程师练得更加炉火纯青!!!
温馨提示:作为一名python工程师 如果遇到一个非常复杂的功能需要实现 那么第一时间不是想着如何去写 而是去网上找有没有相应的python模块!!!
以后出去工作了之后才应该考虑的
eg:人脸识别 语言转换 自动感应 类似更本摸不着头脑的几乎都有模块
"""
# 1.什么是模块?
模块就是一系列功能的结合体 可以直接使用
# 2.为什么要用模块?
极大地提升开发效率(拿来主义>>>:站在巨人的肩膀上)
# 3.模块的三种来源
1.内置的模块
无需下载 解释器自带 直接导入使用即可
2.自定义模块
自己写的代码 封装成模块 自己用或者发布到网上供别人使用
3.第三方模块
别人写的发布到网上的 可以下载使用的模块(很多牛逼的模块都是第三方)
# 4.模块的四种表现形式(大白话:长啥样子)
1.使用python代码编写的py文件 # 掌握
2.多个py文件组成的文件夹(包) # 掌握
3.已被编译为共享库或DLL的c或C++扩展(了解)
4.使用C编写并链接到python解释器的内置模块(了解)
模块的两种导入方式
要想使用模块 必须先导入 而导入的方法有两种方式一:
# 方式1>>>:import...句式
import 模块名
print(模块名.变量名 函数名...)
"""
前提:在研究模块的时候 一定要分清楚谁是执行文件 谁是被导入文件(模块)
模块简介.py是执行文件 md.py是被导入文件(模块)
导入模块内部到底发送了什么事情
1.执行当前文件 产生一个当前文件的名称空间
2.执行import句式 导入模块文件(即执行模块文件代码产生模块文件的名称空间)
3.在当前文件的名称空间中产生一个模块的名字 指向模块的名称空间
4.通过该名字就可以使用到模块名称空间中的所有数据
ps:相同的模块反复被导入只会执行一次
import md 有效
import md 无效(写了跟没写一样)
import md 无效(写了跟没写一样)
"""
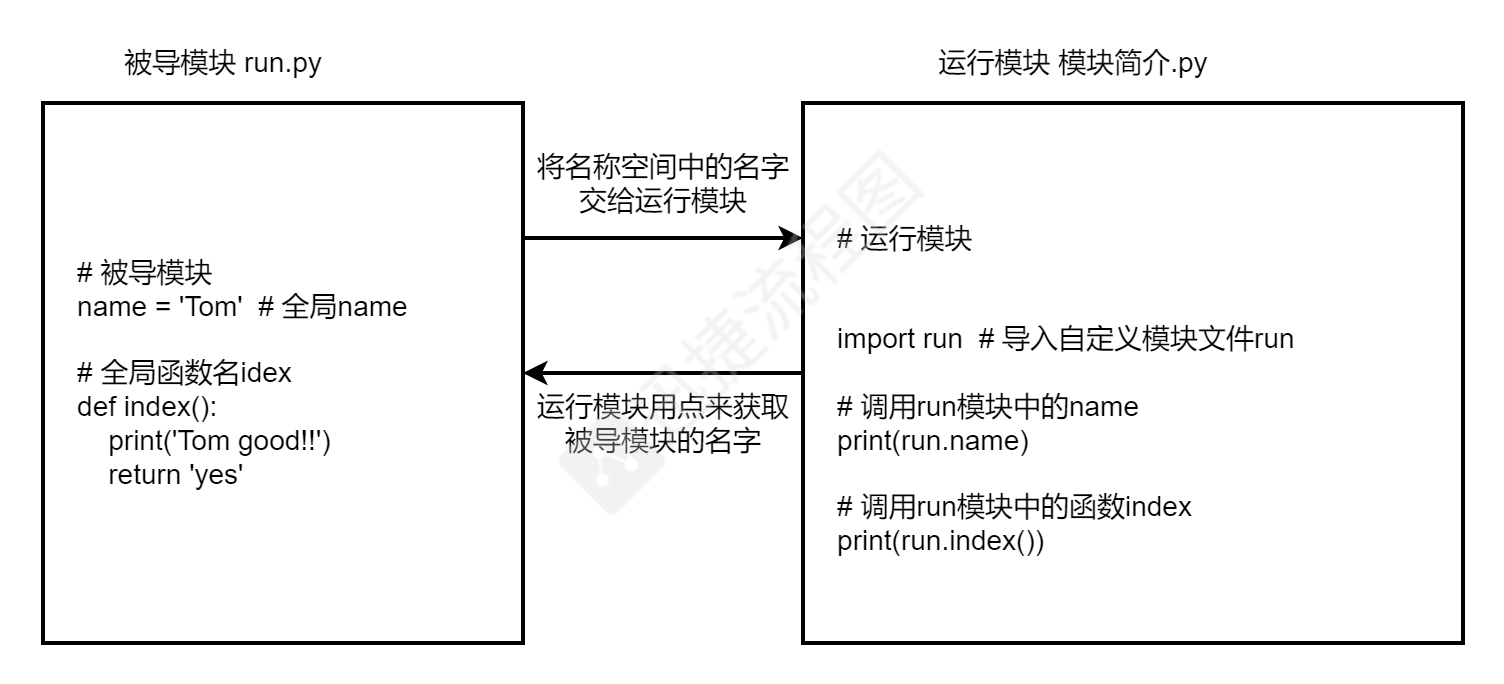
run.py
# 被导模块
name = 'Tom' # 全局name
# 全局函数名idex
def index():
print('Tom good!!')
return 'yes'
模块简介.py
import run # 导入自定义模块文件run
# 调用run模块中的name
print(run.name)
# 调用run模块中的函数index
print(run.index())
'''
执行模块简介文件后,运行结果
Tom
Tom good!!
yes
'''
"""
import句式的特点
可以通过import后面的模块名点的方式 使用模块中所有的名字
并且不会与当前名称空间中的名字冲突(指名道姓)
"""
方式二:
# 方式2>>>:from...import...句式
from 模块名 import 被导模块的变量名 函数名...
print('导模块的变量名,函数名')
"""
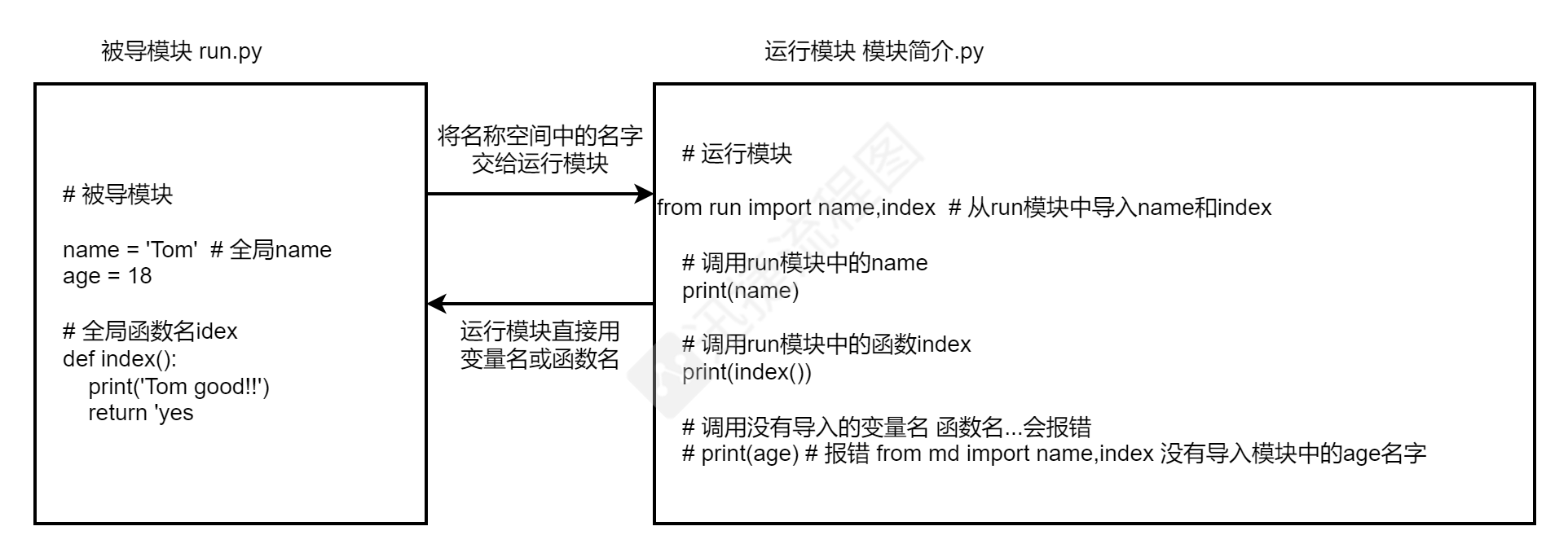
1.重复导入也只会导入一次
2.使用模块名称空间中的名字不需要加模块名前缀 直接使用即可
3.但是from...import的句式会产生名字冲突的问题
在使用的时候 一定要避免名字冲突
4.使用from...import的句式 只能使用import后面出现的名字
from...import...可以简单的翻译成中文
从...里面拿...来用 没有提到的都不能用 指名道姓
"""
run.py
# 被导模块
name = 'Tom' # 全局name
age = 18
# 全局函数名index
def index():
print('Tom good!!')
return 'yes'
模块简介.py
from run import name,index # 从run模块中导入name和index
# 调用run模块中的name
print(name)
# 调用run模块中的函数index
print(index())
# 调用没有导入的变量名 函数名...会报错
# print(age) # 报错 from md import name,index 没有导入模块中的age名字
"""
1.执行当前文件产生一个名称空间
2.执行导入语句 运行模块文件产生名称空间存放运行过程中的所有名字
3.将import后面的名字直接拿到当前执行文件中
"""
导入补充
# 1.可以给模块起别名(使用频率很高)
'''比如模块名或者变量名很复杂 可以起别名简写'''
# import run as m # 修改模块名
# print(m.name)
# from run import name as n # 修改模块中的变量名
# print(n)
# 2.连续导入多个模块或者变量名
# import time, sys, run
# from md import name, age, index
"""连续导入多个模块 这多个模块最好有相似的功能部分 如果没有建议分开导入
如果是同一个模块下的多个变量名无所谓!!!
"""
# 一个个导入
# import time
# import sys
# import run
# 3.通用导入
from md import *
'''*表示md里面所有的名字 from...import的句式也可以导入所有的名字
如果模块文件中使用了__all__限制可以使用的名字 那么*号就会失效 依据__all__后面列举的名字
'''
print(name)
print(age)

本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/16051543.html
