

Python基础 函数
文件操作之
文件内光标的移动
''' 在之前学习到的r模式下如果在文本内容被读完后还有print的话 后边读取到的文本会没有内容,这就与文本内光标的移动有关。''' 1. # read在文本模式下 括号内的数字表示的是读取指定的字符个数 eg: with open(r'a.txt','r',encoding='utf8') as f: print(f.read(3)) print(f.read(3)) # read在二进制模式下 括号内的数字表示的是读取指定的字节数 eg: with open(r'a.txt', 'rb') as f: print(f.read(9).decode('utf8')) print(f.read(1).decode('utf8')) ''' unicode所有的字符都是用2bytes来起步表示 utf8中文用3bytes来表示 英文用1bytes来表示 ''' # 2.控制光标的移动seek()函数 """ seek方法可以控制光标的移动 在文本模式下移动的单位也是字节数 seek(offset,whence) offset:控制移动的字节数 # 可以是负数 表示方向向左 whence:控制模式 0:相对于文件开头(让光标先移动到文件开头) 支持文本模式和二进制模式 1:相对于当前位置(让光标先停留在当前位置) 只支持二进制模式 2:相对于文件结尾(让光标先移动到文件末尾) 只支持二进制模式 """ # 0控制模式 # 只读模式 with open(r'a.txt', 'r', encoding='utf8') as f: print(f.read()) f.seek(3, 0) # 0光标先移到文件开头,再往后移3个字节 print(f.read(3)) # 在光标的位置往后读取3个字符 # 二进制(字节)模式 with open(r'a.txt', 'rb') as f: print(f.read(3).decode('utf8')) # 解码为utf8,在文件头开始读取3个字节 # 1控制模式 '''不读取文本前...个字节''' f.seek(6, 1) # 1为光标当前位置 再往后移6个字节 f.seek(3, 1) # 1为光标当前位置 再往后移3个字节 print(f.read().decode('utf8')) # 结果相当于文件头往后移9个字节在读取文本内容 也相当于前9个字节取不到 # 2控制模式 '''只读取文本后3个字节''' f.seek(-3, 2) # 2为将光标移到文本尾部 -3为在将光标向前移3个字节 print(f.read().decode('utf8')) print(f.tell()) # 可以知道文件头到光标的之间的字节数 print(f.read().decode('utf8'))
文件数据修改
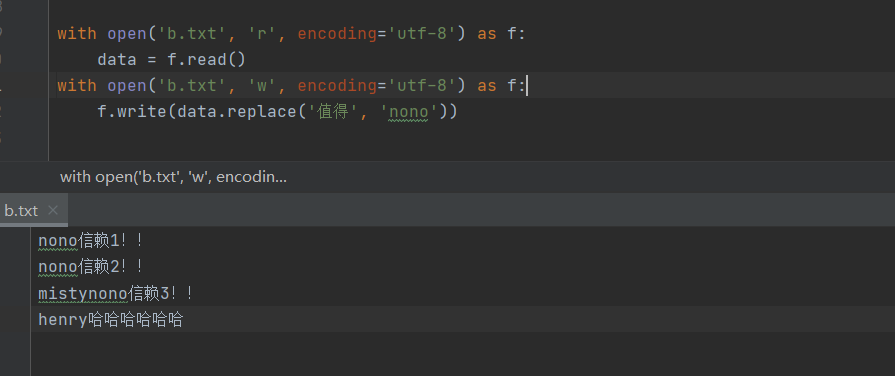
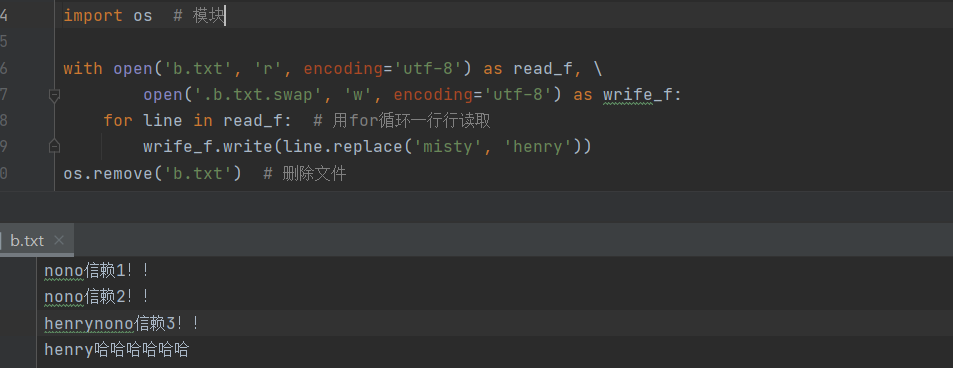
""" 文件数据在硬盘上其实是刻死 不可能从中间再添加新的内容 只能将老内容移除 刻新的 """ 1. 方式1 # 实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件 # 优点: 在文件修改过程中同一份数据只有一份 # 缺点: 会过多地占用内存 with open('b.txt', mode='r', encoding='utf-8') as f: data = f.read() with open('b.txt', mode='w', encoding='utf-8') as f: f.write(data.replace('值得', 'nono')) 2. 方式2 # 实现思路:以读的方式打开原文件,然后用写的方式打开一个临时文件,一行行读取原文 件内容,修改完后写入临时文件..., # 删掉原文件,将临时文件重命名原文件名 # 优点: 不会占用过多的内存 # 缺点: 在文件修改过程中同一份数据存了两份 import os # 模块 with open('b.txt', 'r', encoding='utf-8') as read_f, \ open('.b.txt.swap', 'w', encoding='utf-8') as wrife_f: for line in read_f: # 用for循环一行行读取 wrife_f.write(line.replace('misty', 'henry')) os.remove('b.txt') # 删除文件 os.rename('.b.txt.swap', 'b.txt') # 重命名文件
函数
函数简介
# python函数本质 python中的函数本质 就是将我们要实现的某些功能用代码写出来能实现了再进行一个打包封装, 之后方便使用。可以看为有某功能的工具。 """如何查看内部源码 ctrl+左键点击""" # 如len方法不能用了 我们想要统计个数只能自己写 s = '芭比Q了!' print(len(s)) # len方法 def my_len(): # def关键字 自己写 n = 0 for i in s: n += 1 print('字符串中字符的个数',n) """ 上述代码与真正的len差距 1.len可以统计指定数据的元素个数 而我们的len目前只能统计指定的数据 2.len执行完成后有结果 而我们的len执行完成后结果是None """ # 内置函数和自定义函数 '''python中的内置方法其实也是函数,python的内置函数 需要可直接拿来使用 而我们自己写的函数称之为自定义函数'''
函数的语法结构
# 语法结构 def 函数名(参数1,参数2): '''函数的注释''' 函数体代码 return 返回值 # 调用 函数名() 1.def 是定义函数的关键字 必不可少 2.函数名 函数名类似于是变量名 指代函数体代码 命名与变量名一致 3.括号 定义函数的时候 函数名后面肯定要先写括号 4.参数 类似于使用函数的时候 给函数内部传递的数据 可以不写 或者单个、多个 5.冒号 定义函数也需要有缩进的代码块 6.函数的注释 用于解释函数的主要功能、使用方法等说明性文字 7.函数体代码 函数的核心功能 也是我们将来编写的核心 8.return 后面跟什么 那么执行完函数之后就会返回什么 """ 定义函数需要使用def关键字 定义函数的过程不会执行函数体代码 只会检测语法 def index(): xsadasd 定义的时候不会报错 def index1(): if 语法错误定义的时候就会报错 调用函数需要使用函数名加括号 """

happy to you!!

本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/16008521.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)