
字符编码与文件操作
字符编码
编码发展史
# 一家独大
计算机是美国人发明的 所以一开始只考虑到了英文字符与数字的对应关系
其他国家要想使用电脑就必须会英语和ASCII码
ASCII码:记录了英文字符与数字的对应关系
1bytes(8bit)来表示英文
"""
A-Z:65-90
a-z:97-122
"""
# 群雄割据
其他国家也相继开始使用计算机 面临了相同问题
GBK:中国字符编码记录了英文、中文与数字的对应关系
1bytes(8bit)来表示英文
2bytes(16bit)来表示中文(很多时候都是3bytes)
Euc_kr:韩国字符编码记录了英文、韩文与数字的对应关系
shift_JIS:日本字符编码记录了英文、日文与数字的对应关系
"""
乱码
不同国家的字符编码存在差异当其他国家解码时会产生>>'乱码'
'编写'和'翻译'阶段使用的编码表不一致
"""
# 天下一统
unicode:万国码 # 记录了所有国家的文字语言和字符
所有的字符都是2bytes起步存储
会浪费空间和IO时间
utf8:万国码的转换版本
"""
内存使用的是unicode 硬盘使用的是utf8
"""
字符编码的实际使用
- 编码与解码
# 编码
将人能读懂的字符编写成计算机能够直接听懂的字符的过程
# 解码
将计算机能够听懂的字符解码成人能够读懂的字符
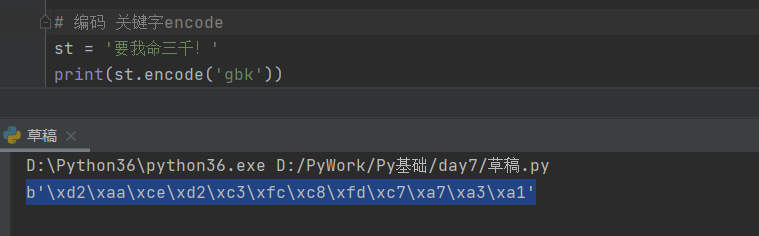
# 编码 encode
st = '要我命三千!'
print(st.encode('gbk'))
# 结果 b'\xd2\xaa\xce\xd2\xc3\xfc\xc8\xfd\xc7\xa7\xa3\xa1'
"""
字符串前面如果加了字母b 表示该数据类型为 bytes类型
bytes类型可以看成是二进制
"""
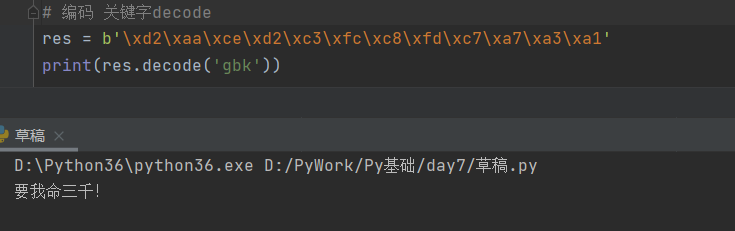
# 解码 decode
res = b'\xd2\xaa\xce\xd2\xc3\xfc\xc8\xfd\xc7\xa7\xa3\xa1'
print(res.decode('gbk'))
# 结果 要我命三千!
"""
基于网络传输数据 数据都必须是二进制格式
所以肯定涉及到编码与解码
"""
- 解决乱码问题
'''数据当初以什么编码编的就以什么编码解即可,
如果不知道的话只能一个个的试总有一个是对的'''
s1 = '要我命三千!'
res1 = s1.encode('gbk')
print(res1) # 编码 b'\xd2\xaa\xce\xd2\xc3\xfc\xc8\xfd\xc7\xa7\xa3\xa1'
res2 = res1.decode('euc_kr')
print(res2) # 乱码 狼乖츱힛푤!
res3 = res1.decode('gbk')
print(res3) # 正常显示 要我命三千!
- python解释器版本与编码
'''python2解释器默认的编码是ASCII码'''
1.文件头:必须写在文件的最上方 告诉解释器使用指定的编码
# coding:utf8
# -*- coding:utf8 -*- 美化写法
2.字符前缀:在使用python2解释器的环境下定义字符串习惯在前面加u
name = u'你好啊'
'''python3解释器默认的编码是utf8'''
文件操作
文件本质
- 操作系统暴露给用户可以直接操作硬盘的快捷方式
文件基本操作
# 1. 代码操作文件的过程
打开文件,创建文件 --> 编辑文件内容 --> 保存文件内容 --> 关闭文件
# 2. 基本语法结构
结构1(不常用):
f1 = open() # 打开文件
f1.close() #关闭文件
结构2(推荐使用):
with open() as f: # 当执行结束会自动关闭文本
pass
# 3. open关键字打开文件
'''以后写路径为了防止特殊符号 直接加r'''
open(r'a.txt') # 相对路径
open(r'D:\py1\day09\a.txt') # 绝对路径
res = open(r'a.txt', 'r', encoding='utf8')
# 第一个值文本路径 第二个值读(r)模式(mode) 第三个编码类型
"""
open(文件的路径,文件的操作模式,文件的编码)
1.文件的路径是必须要写的
2.文件的操作模式、文件的编码有时候不用写 b模式
"""
print(res.read()) # 读取文件内容
res.close() # 关闭文件 操作open完最后都需要执行close 而close这一行很任意被遗忘
# 4. with上下文管理 # 不需要close关闭文件 with执行完会自行关闭文件
with open(r'a.txt', 'r', encoding='utf8') as f: # 类似f = open()
data = f.read()
print(data)
文件读写模式
r read 只读模式:只能读不能写
w write 只写模式:只能写不能读
a append 只追加模式:在文件末尾添加内容
# r模式 # 只读模式:只能读不能写
# 路径不存在:直接报错
with open(r'b.txt', 'r', encoding='utf8') as f1:
# pass (推荐)补全语法结构 本身没有任何功能
# ... (不推荐)补全语法结构 本身没有任何功能
pass
路径存在:正常打开文件并等待内容读取
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.read()) # 一次性读取文件内所有的内容
f1.write('无地自容啊!!!') # 报错 只读模式不能写
"""
able在英语中大部分情况下表示的是 具备...的能力
readable 具备读的能力
writable 具备写的能力
...
"""
# w模式 # 只写模式:只能写不能读
# 路径不存在:自动创建文件
with open(r'b.txt', 'w', encoding='utf8') as f1:
pass (推荐)补全语法结构 本身没有任何功能
... (不推荐)补全语法结构 本身没有任何功能
pass
# 路径存在:先清空文件内容(不要写重要文件路径) 之后再写入数据
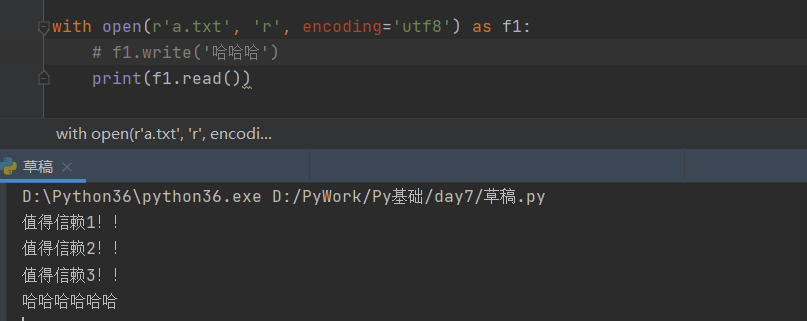
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write('值得信赖1!!\n') # 写入文件内容
f1.write('值得信赖2!!\n') # 写入文件内容
f1.write('值得信赖3!!\n') # 写入文件内容
#print(f1.read()) # 只写模式 不能读 写入后注释 改为r模式就可读取文本内容
'''\n换行要自己写电脑并不会自行换行只能按照人的指令执行命令'''
"""
换行 最早的时候:\r\n
为了节省空间支持一个字符 根据操作系统的不同可能有所区别 \n 、\r
"""
# a模式 只追加模式:在文件末尾添加内容
# 路径不存在:自动创建文件
with open(r'c.txt', 'a', encoding='utf8') as f1:
pass
# 路径存在:不会清空文件内容 而是在文件末尾等待新内容的添加
with open(r'a.txt', 'a', encoding='utf8') as f1:
f1.write('哈哈哈') # 直接从原文本末尾写入
#print(f1.read()) # 写入后注释 改为r模式就可读取文本内容
文件操作模式
# t模式 即text文本模式 默认的都是t模式
r # 即rt
w # 即wt
a # 即at
1.该模式只能操作文本文件 不能操作图片,视频等
2.该模式必须要指定encoding参数
3.该模式读写都是以字符串为最小单位
# b模式
二进制模式 可以操作任意类型的文件
rb 不能省略b
wb 不能省略b
ab 不能省略b
1.该模式可以操作任意类型的文件
2.该模式不需要指定encoding参数
3.该模式读写都是以bytes类型为最小单位
文件的内置方法
read() # 一次性读取文件内的全部内容
1.执行完之后光标在文件末尾 继续读取没有内容
2.当文件内容特别大的时候 容易造成内存内存不够用溢出
readline() # 只读取一行文本内容
readlines() # 一行一行的完全读取内容 结果是一个列表 元素是一行行的内容
readable() # 判断当前文件是否可读 结果为布尔值Ture 或 False
支持for循环 # 一行行读取文件内容(推荐使用) 内存中同一时刻只会有一行内容 节省内存
write() # 写入文件内容(字符串或者bytes类型)
writelines() # 可以将列表中多个元素写入文件
writable() # 判断文件是否可写 结果为布尔值Ture 或 False
flush() # 进行一个优先级保存 相当于主动按了ctrl+s

本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/16006484.html
