

数据类型的内置方法
字符串其他的内置方法
字符串的strip
strip方法可移除字符串的首尾指定的字符,但无法移除字符串中的
eg:
hai = '&&&&jiliji&&qide&&&&&'
print(hai.strip('&')) #1. 移除字符首尾的& 输出结果:jiliji&&qide
print(hai.lstrip('&')) #2. 移除字符左边的& 输出结果:jiliji&&qide&&&&&
print(hai.lstrip('&')) #2. 移除字符右边的& 输出结果:&&&&&jiliji&&qide
字母大小写
eg: hai = 'Hello World'
1.'lower'方法将所有的英文字母变为小写
print(hai.lower()) # 输出结果: hello world
2.'upper'方法将所有的英文字母变为大写
print(hai.upper()) # 输出结果: HELLO WORLD
3.'islower'判断字符串的英文字母是否都是小写 判断结果为布尔值
tlt = (hai.lower()) # 将'Hello World'变为小写然后赋值给变量名tlt
print(tlt.islower()) # 输出结果: True
4.'isupper'判断字符串的英文字母是否都是大写 判断结果为布尔值
print(hai.isupper()) # 'Hello World'不都是大写 输出结果: False
startswith和endswith方法
eg: nice = 'my girl you are a start!'
1.'startswith'用于判断字符串开头是否是指定的字符 结果为布尔值
print(nice.startswith('y')) # 不以y开头 结果为:False
print(nice.startswith('m')) # 以m开头 结果为:Ture
2.'endswith'用于判断字符串结尾是否是指定的字符 结果为布尔值
print(nice.startswith('t')) # 不以t结尾 结果为:False
print(nice.startswith('!')) # 以!结尾 结果为:Ture
format方法格式化输出
之前的格式化输出方式用的是占位符%s,%d,但缺点就是每个占位符都要写上对应的值这样会显得很繁琐,
而format方法的用法有很多种而且也更加简便
format用法:
用法1:跟占位符一样 使用的是{}来占位
eg:
print('my {} {} {}are a {}!'.format('teacher', 'and', 'jason', 'sao boy'))
# 结果为:my teacher and jasonare a sao boy!
用法2:根据索引取值 可以反复使用
eg:
print('你是{0},我是{1},你是{0}{0},我是{1}{1}'.format('风儿', '沙'))
# 结果为:你是风儿,我是沙,你是风儿风儿,我是沙沙
用法3:直接在字符串的{}内写入变量名
eg:
print('你是{name1},我是{name2}}'.format(name1='风儿', name2='沙'))
# 结果为:你是风儿,我是沙
用法4:直接使用已经出现过的变量名 # *注 要在字符串前面加字母'f'
eg:
name = '吴彦祖'
print(f'你是{name},你也是{name}') # 结果为:你是吴彦祖,你也是吴彦祖
列表的内置函数
'类型转换' list() # int float 数据类型不能转换成列表
字符串转列表 # 类似用for循环把字符串的字符一个个取出然后再放到列表里
print(list('jason')) # ['j', 'a', 's', 'o', 'n']
字典转列表 # 只能转换字典中的key 无法取到value
print(list({'name': 'jason', 'pwd': 123})) # ['name', 'pwd']
元组转换列表 # 类似用for循环把元组元素一个个取出并放到列表里
print(list((11,22,33,44,55))) # [11, 22, 33, 44, 55]
集合转换列表 # 类似用for循环把集合元素一个个取出并放到列表里
print(list({1, 2, 3, 4, 5})) # [1, 2, 3, 4, 5]
布尔转列表
print(list(True))
'常见的操作'
date_info = ['monday', 'friday', 'sunday', 'likeday', 'fatherday']
1.索引取值
列表是有序的 可索引取值
eg: print(date_info[2]) # 结果: sunday
2.切片操作
print(date_info[1:4]) # 结果:['friday', 'sunday', 'likeday']
3.间隔 (步长)
print(date_info[0:4:1]) # 结果:['monday', 'friday', 'sunday', 'likeday']
print(date_info[1:4:2]) # 结果: ['friday', 'likeday']
print(date_info[-1:-4:-1]) # 结果:['fatherday', 'likeday', 'sunday']
4.统计列表中元素的个数
print(leg(date_info[1:4:2])) # 结果:5
5.成员运算 最小判断单位是元素不是元素里面的单个字符
print('day' in date_info) # False
print('sunday' in date_info) # True
6.列表添加元素的方式
# 尾部追加'单个'元素
date_info.append('oneday')
print(date_info)
# 指定位置插入'单个'元素
date_info.insert(0, 'old')
# 合并列表
date_info.extend([1, 2, 3])
7.删除元素
# 通用的删除方式
del date_info[0]
# 就地删除 # 指名道姓的直接删除某个元素
print(date_info.remove('sunday'))
# 延迟删除
print(date_info.pop()) # 默认末尾弹出
print(date_info.pop(2)) # 指定弹出
8.修改列表元素
date_info[0] = 'SB'
9.排序
a = [1, 2, 3, 4]
a.sort() # 升序
a.sort(reverse=Ture)
10.翻转
a = [1, 2, 3, 4]
a.reverse() # 前后反转
11.比较运算
a = [1, 2, 3, 4]
b = [4,1,0,6]
print(b > a) # True
12.统计列表中某个元素出现的次数
num = [1, 1, 5,6,5, 6, 1]
print(num.count(1)) # 统计元素1出现的次数
13.清空列表
num = [1, 1, 5,6,5, 6, 1]
num.clear() # 清空列表
可变和不可变类型
**内存地址用id关键字查看
'''
可变类型 # list、 dict、 set
值发生改变 内存地址不会改变
'''
就比如列表,列表中修改元素并不会使列表的地址改变
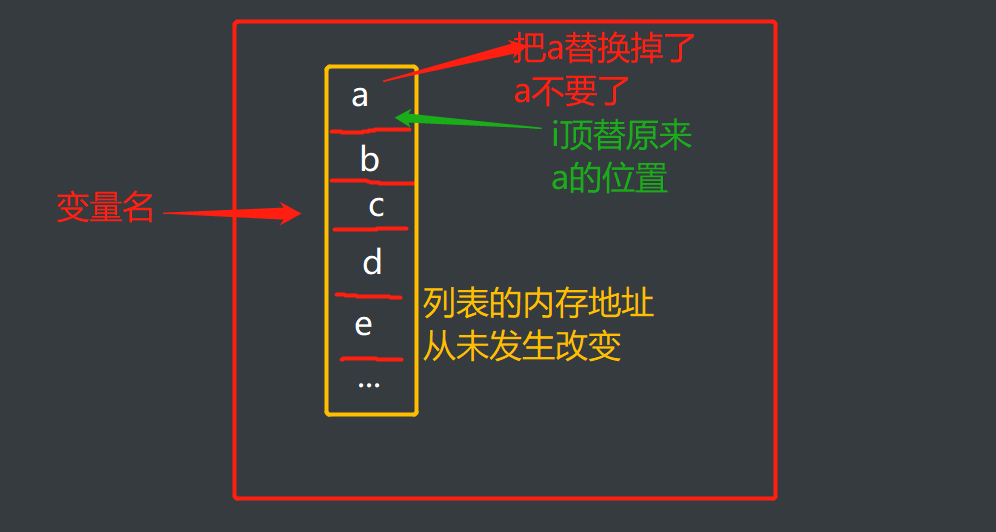
'''
不可变类型 # str、 int、 tuple、 float、 bool
值改变内存地址也一定会发生改变
'''
如字符串,字符串是一个整体不能修改其中的某个字符只能修改整个字符串
修改字符串之后它的值变了内存地址也发生了变化
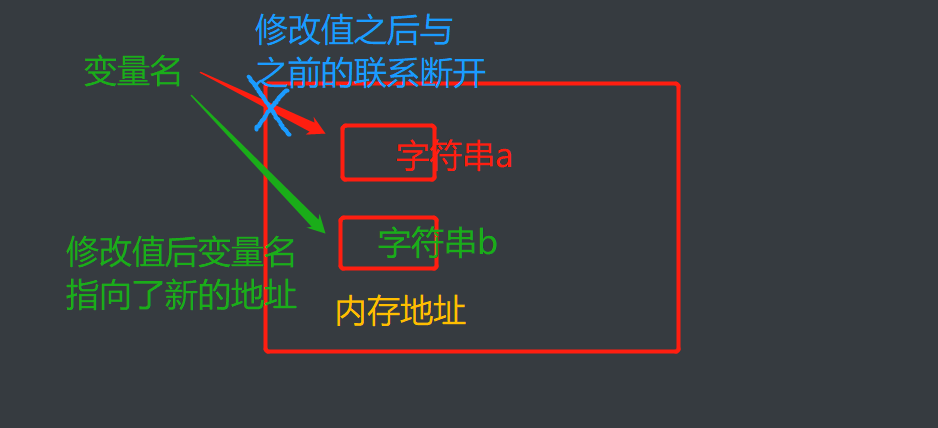
拓展
队列:
队列本质进是按照先来后到的顺序依次执行
就比如排队做核酸,只能按照先来后到的顺序一个个来
例图如下:

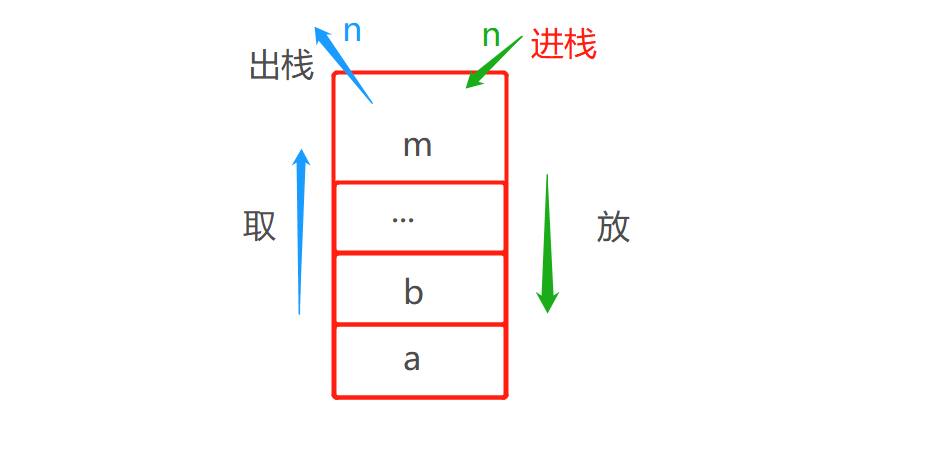
堆栈:
先进后出的原则
可以理解为一个堆满东西的仓库之前先放进去的东西无法直接取出来,
要先把后面放的东西一件一件的取出来才可以把最先放进去的东西取出
例图如下:
本文来自博客园,作者:{Mr_胡萝卜须},转载请注明原文链接:https://www.cnblogs.com/Mr-fang/p/15987178.html
