
Doris:概念与基础操作
Doris
一款现代化的MPP分析性数据库产品
支持亚秒级响应
支持10PB以上数据集
兼容MySQL协议
基础概念
doris有3种基础表:
- 明细表(Duplicate):一张普普通通的表,doris默认表模式,支持数据预排序
- 主键表(Unique):一种特殊的聚合表,如果主键重复,会自动更新其他值
- 聚合表(Aggregate):聚合模型的表只有key、value列,指定好key列后,后续的数据都会自动聚合求value
doris支持分区(Partition)分桶(Tablet),一个桶就是一个分片,也是数据划分的最小逻辑单元。
- Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作的最小物理存储单元。
- Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
Apache Doris 的使用场景
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到实时数据仓库 Apache Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。
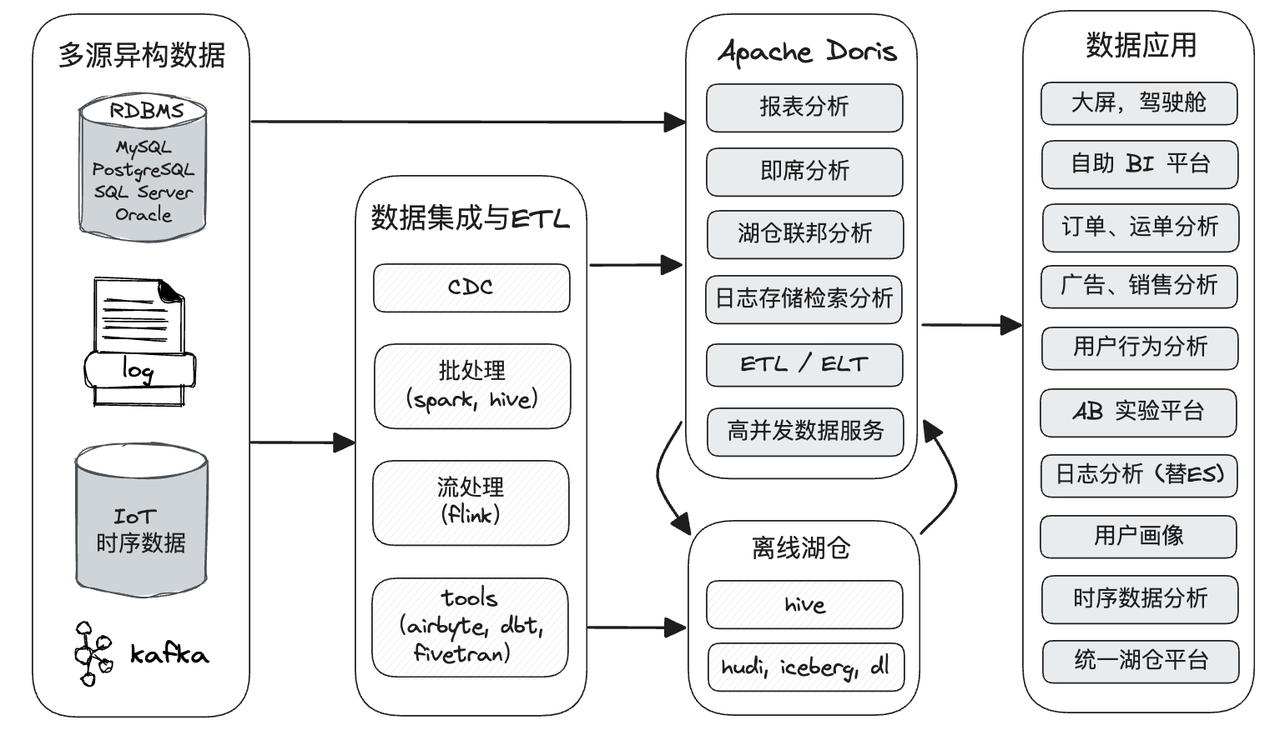
- 报表分析
- 实时看板(Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
- 即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
- 数据湖联邦分析(LakeHouse):通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 等离线湖仓中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
- 日志检索分析:在 Apache Doris 2.0 版本中,支持了倒排索引和全文检索,能够很好的满足日志检索分析的场景,并且依赖其高效的查询引擎和存储引擎,相比传统的日志检索分析的方案可以有 10 倍性价比的优势。
- 统一数仓构建:一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Apache Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
Doris主要用于实时数仓,或是数据湖。如今很火的StarRock可被用于湖仓一体项目,打破数据孤岛局面。
Doris架构
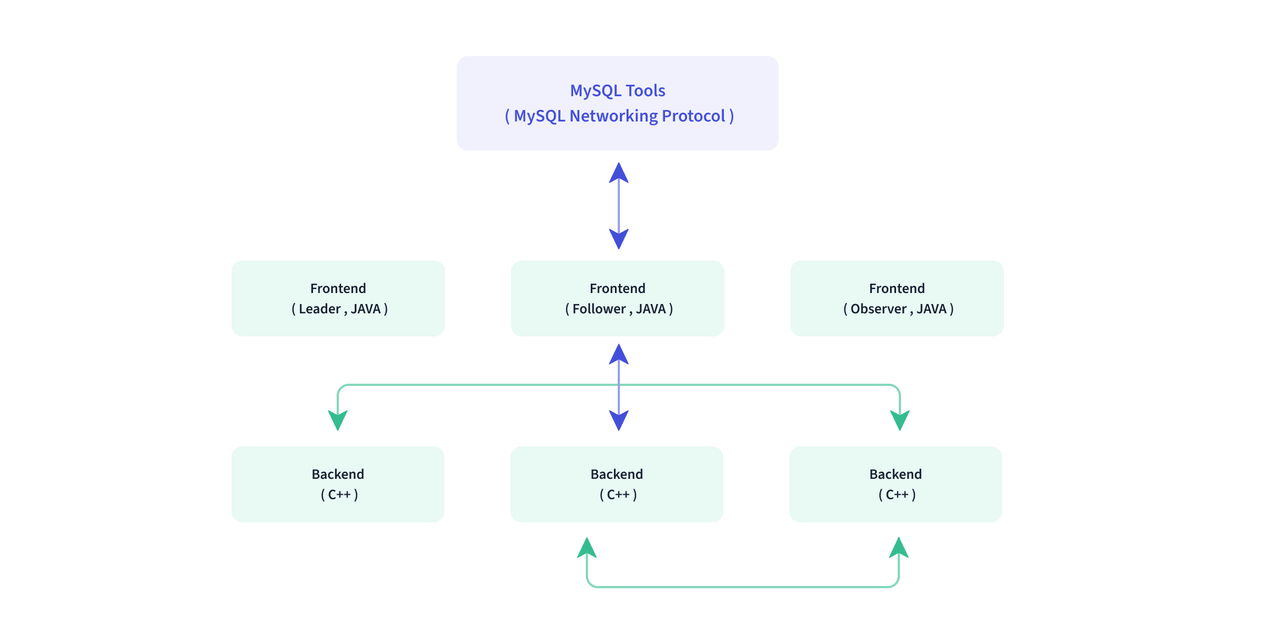
Doris 整体架构如下图所示,Doris 架构非常简单,只有两类进程
- Frontend(FE),主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
- Backend(BE),主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
数据类型
Apache Doris 支持标准 SQL 语法,采用 MySQL 网络连接协议,高度兼容 MySQL 相关生态。因此,在数据类型支持方面,尽可能对齐 MySQL 相关数据类型。
Doris 已支持的数据类型列表如下:
| 类型名 | 字节数 | 描述 |
|---|---|---|
| BOOLEAN | 1 | 布尔值,0 代表 false,1 代表 true。 |
| TINYINT | 1 | 有符号整数,范围 [-128, 127]。 |
| SMALLINT | 2 | 有符号整数,范围 [-32768, 32767]。 |
| INT | 4 | 有符号整数,范围 [-2147483648, 2147483647] |
| BIGINT | 8 | 有符号整数,范围 [-9223372036854775808, 9223372036854775807]。 |
| LARGEINT | 16 | 有符号整数,范围 [-2^127 + 1 ~ 2^127 - 1]。 |
| FLOAT | 4 | 浮点数,范围 [-3.410^38 ~ 3.410^38]。 |
| DOUBLE | 8 | 浮点数,范围 [-1.7910^308 ~ 1.7910^308]。 |
| DECIMAL | 2004/8/16 | 高精度定点数,格式:DECIMAL(M[,D])。其中,M 代表一共有多少个有效数字(precision),D 代表小数位有多少数字(scale)。有效数字 M 的范围是 [1, 38],小数位数字数量 D 的范围是 [0, precision]。0 < precision <= 9 的场合,占用 4 字节。9 < precision <= 18 的场合,占用 8 字节。16 < precision <= 38 的场合,占用 16 字节。 |
| DATE | 16 | 日期类型,目前的取值范围是 ['0000-01-01', '9999-12-31'],默认的打印形式是 'yyyy-MM-dd'。 |
| DATETIME | 16 | 日期时间类型,格式:DATETIME([P])。可选参数 P 表示时间精度,取值范围是 [0, 6],即最多支持 6 位小数(微秒)。不设置时为 0。取值范围是 ['0000-01-01 00:00:00[.000000]', '9999-12-31 23:59:59[.999999]']。打印的形式是 'yyyy-MM-dd HH:mm:ss.SSSSSS'。 |
| CHAR | M | 定长字符串,M 代表的是定长字符串的字节长度。M 的范围是 1-255。 |
| VARCHAR | M | 变长字符串,M 代表的是变长字符串的字节长度。M 的范围是 1-65533。变长字符串是以 UTF-8 编码存储的,因此通常英文字符占 1 个字节,中文字符占 3 个字节。 |
| STRING | / | 变长字符串,默认支持 1048576 字节(1MB),可调大到 2147483643 字节(2GB)。可通过 BE 配置 string_type_length_soft_limit_bytes 调整。String 类型只能用在 Value 列,不能用在 Key 列和分区分桶列。 |
| HLL | / | HLL 是模糊去重,在数据量大的情况性能优于 Count Distinct。HLL 的误差通常在 1% 左右,有时会达到 2%。HLL 不能作为 Key 列使用,建表时配合聚合类型为 HLL_UNION。用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。HLL 列只能通过配套的 hll_union_agg、hll_raw_agg、hll_cardinality、hll_hash 进行查询或使用。 |
| BITMAP | / | BITMAP 类型的列可以在 Aggregate 表或 Unique 表中使用。在 Unique 表中使用时,其必须作为非 Key 列使用。在 Aggregate 表中使用时,其必须作为非 Key 列使用,且建表时配合的聚合类型为 BITMAP_UNION。用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。BITMAP 列只能通过配套的 bitmap_union_count、bitmap_union、bitmap_hash、bitmap_hash64 等函数进行查询或使用。 |
| QUANTILE_STATE | / | QUANTILE_STATE 是一种计算分位数近似值的类型,在导入时会对相同的 Key,不同 Value 进行预聚合,当 value 数量不超过 2048 时采用明细记录所有数据,当 Value 数量大于 2048 时采用 TDigest 算法,对数据进行聚合(聚类)保存聚类后的质心点。QUANTILE_STATE 不能作为 Key 列使用,建表时配合聚合类型为 QUANTILE_UNION。用户不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。QUANTILE_STATE 列只能通过配套的 QUANTILE_PERCENT、QUANTILE_UNION、TO_QUANTILE_STATE 等函数进行查询或使用。 |
| ARRAY | / | 由 T 类型元素组成的数组,不能作为 Key 列使用。目前支持在 Duplicate 和 Unique 模型的表中使用。 |
| MAP | / | 由 K, V 类型元素组成的 map,不能作为 Key 列使用。目前支持在 Duplicate 和 Unique 模型的表中使用。 |
| STRUCT | / | 由多个 Field 组成的结构体,也可被理解为多个列的集合。不能作为 Key 使用,目前 STRUCT 仅支持在 Duplicate 模型的表中使用。一个 Struct 中的 Field 的名字和数量固定,总是为 Nullable。 |
| JSON | / | 二进制 JSON 类型,采用二进制 JSON 格式存储,通过 JSON 函数访问 JSON 内部字段。默认支持 1048576 字节(1MB),可调大到 2147483643 字节(2GB)。可通过 BE 配置 jsonb_type_length_soft_limit_bytes 调整。 |
| AGG_STATE | / | 聚合函数,只能配合 state/merge/union 函数组合器使用。AGG_STATE 不能作为 key 列使用,建表时需要同时声明聚合函数的签名。用户不需要指定长度和默认值。实际存储的数据大小与函数实现有关。 |
你也可通过SHOW DATA TYPES;语句查看 Doris 支持的所有数据类型。
建表模板
doirs可以通过HELP CREATE TABLE;语句来提示建表操作。
建表语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name(
column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition12,]]
)
[ENGINE = [olap|mysql|broker|hive]] -- 用来指定数据源,默认是olap自己内部引擎。broker是一个文件接口,可用来指定外部文件,如hdfs 、S3
[key_desc] -- 选择key描述,分别有明细模型、主键模型、聚合模型
[COMMENT "table comment"] -- 表的注释
[partition_desc] -- 表的分区配置
[distribution_desc] -- 表的分桶配置
[rollup_index]
[PROPERTIES ("key"="value", ...)] -- 表的参数配置
[BROKER PROPERTIES ("key"="value", ...)]; -- 配置的broker engine后补充的特殊配置
数据模型
所有模型在建表时,key列都应该在value列前
明细模型
明细模型,也成为 Duplicate 数据模型。在doris种,如果不指定key_desc,默认就是明细模型,并且系统默认选定前3列数据进行排序,即排序列
无排序列的默认明细模型
当用户并没有排序需求的时候,可以通过在表属性中增加如下配置。这样在创建默认明细模型时,系统就不会自动选择任何排序列。
"enable_duplicate_without_keys_by_default" = "true"
建表举例如下:
CREATE TABLE IF NOT EXISTS example_tbl_duplicate_without_keys_by_default
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_duplicate_without_keys_by_default" = "true"
);
MySQL > desc example_tbl_duplicate_without_keys_by_default;
+------------+---------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-------+---------+-------+
| timestamp | DATETIME | No | false | NULL | NONE |
| type | INT | No | false | NULL | NONE |
| error_code | INT | Yes | false | NULL | NONE |
| error_msg | VARCHAR(1024) | Yes | false | NULL | NONE |
| op_id | BIGINT | Yes | false | NULL | NONE |
| op_time | DATETIME | Yes | false | NULL | NONE |
+------------+---------------+------+-------+---------+-------+
6 rows in set (0.01 sec)
指定排序列的明细模型
在建表语句中指定 DUPLICATE KEY,用来指明数据存储按照这些 Key 列进行排序。在 DUPLICATE KEY 的选择上,建议选择前 2-4 列即可。
建表语句举例如下,指定了按照 timestamp、type 和 error_code 三列进行排序。
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
MySQL > desc example_tbl_duplicate;
+------------+---------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-------+---------+-------+
| timestamp | DATETIME | No | true | NULL | NONE |
| type | INT | No | true | NULL | NONE |
| error_code | INT | Yes | true | NULL | NONE |
| error_msg | VARCHAR(1024) | Yes | false | NULL | NONE |
| op_id | BIGINT | Yes | false | NULL | NONE |
| op_time | DATETIME | Yes | false | NULL | NONE |
+------------+---------------+------+-------+---------+-------+
6 rows in set (0.01 sec)
数据按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。而在建表语句中指定的 DUPLICATE KEY,只是用来指明数据存储按照哪些列进行排序。在 DUPLICATE KEY 的选择上,建议选择前 2-4 列即可。
主键模型
主键模型能够保证 Key(主键)的唯一性,当用户更新一条数据时,新写入的数据会覆盖具有相同 key(主键)的旧数据。
主键模型提供了两种实现方式:
- 读时合并 (merge-on-read)。在读时合并实现中,用户在进行数据写入时不会触发任何数据去重相关的操作,所有数据去重的操作都在查询或者 compaction 时进行。因此,读时合并的写入性能较好,查询性能较差,同时内存消耗也较高。
- 写时合并 (merge-on-write)。在 1.2 版本中,我们引入了写时合并实现,该实现会在数据写入阶段完成所有数据去重的工作,因此能够提供非常好的查询性能。自 2.0 版本起,写时合并已经非常成熟稳定,由于其优秀的查询性能,我们推荐大部分用户选择该实现。自 2.1 版本,写时合并成为 Unique 模型的默认实现。
数据更新的语意
- Unique 模型默认的更新语意为整行
UPSERT,即 UPDATE OR INSERT,该行数据的 key 如果存在,则进行更新,如果不存在,则进行新数据插入。在整行UPSERT语意下,即使用户使用 insert into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充。 - 部分列更新。如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。
Doris建表默认为读时合并,开启写时合并,则需要在建表时指定如下参数
"enable_unique_key_merge_on_write" = "true"
聚合模型
聚合模型通过AGGREGATE KEY 来指定key值,聚合模型只有key、value两列,建表时,key列必须在value列前面,多个key值重复时,聚合模型会自动按指定的key列进行value的AggregationType类型聚合。主键模型是一种特殊的聚合模型。
AggregationType 目前有以下几种聚合方式和 agg_state:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
- REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于 null 值,不做替换。
- HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。
- BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。
建表语句:
CREATE TABLE IF NOT EXISTS example_tbl_agg1
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
分区
分区指定的列默认必须为NOT NULL列。对于 RANGE PARTITION,NULL 值会被划归最小的 LESS THAN 分区
无论分区是什么类型,在写分区值时,都需要加双引号
分区列可以指定一列或多列,对于聚合模型,分区列不能为value
创建分区时不可添加范围重叠的分区。
在分区外的数据,会入不了库
从 2.1.3 版本开始,Doris 支持以下的 NULL 值分区用法。应设置 session variable
allow_partition_column_nullable = true。
手动分区
分区:分区有Range分区、List分区
动态分区
开启动态分区的表,将会按照设定的规则添加、删除分区,从而对表的分区实现生命周期管理(TTL),减少用户的使用负担。
动态分区只支持在 DATE/DATETIME 列上进行 Range 类型的分区。(已可以满足绝大多数业务需求)
动态分区适用于分区列的时间数据随现实世界同步增长的情况。此时可以灵活的按照与现实世界同步的时间维度对数据进行分区,自动地根据设置对数据进行冷热分层或者回收。
使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则。
-
建表时指定
CREATE TABLE tbl1 (...) PROPERTIES ( "dynamic_partition.prop1" = "value1", "dynamic_partition.prop2" = "value2", ... ) -
运行时修改
ALTER TABLE tbl1 SET ( "dynamic_partition.prop1" = "value1", "dynamic_partition.prop2" = "value2", ... )
规则参数
动态分区的规则参数都以 dynamic_partition. 为前缀:
-
dynamic_partition.enable是否开启动态分区特性。可指定为
TRUE或FALSE。如果不填写,默认为TRUE。如果为FALSE,则 Doris 会忽略该表的动态分区规则。 -
dynamic_partition.time_unit(必选参数)动态分区调度的单位。可指定为
HOUR、DAY、WEEK、MONTH、YEAR。分别表示按小时、按天、按星期、按月、按年进行分区创建或删除。当指定为
HOUR时,动态创建的分区名后缀格式为yyyyMMddHH,例如2020032501。小时为单位的分区列数据类型不能为 DATE。当指定为
DAY时,动态创建的分区名后缀格式为yyyyMMdd,例如20200325。当指定为
WEEK时,动态创建的分区名后缀格式为yyyy_ww。即当前日期属于这一年的第几周,例如2020-03-25创建的分区名后缀为2020_13, 表明目前为 2020 年第 13 周。当指定为
MONTH时,动态创建的分区名后缀格式为yyyyMM,例如202003。当指定为
YEAR时,动态创建的分区名后缀格式为yyyy,例如2020。 -
dynamic_partition.time_zone动态分区的时区,如果不填写,则默认为当前机器的系统的时区,例如
Asia/Shanghai,如果想获取当前支持的时区设置,可以参考https://en.wikipedia.org/wiki/List_of_tz_database_time_zones。 -
dynamic_partition.start动态分区的起始偏移,为负数。根据
time_unit属性的不同,以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。如果不填写,则默认为-2147483648,即不删除历史分区。此偏移之后至当前时间的历史分区如不存在,是否创建取决于dynamic_partition.create_history_partition。 -
dynamic_partition.end(必选参数)动态分区的结束偏移,为正数。根据
time_unit属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。 -
dynamic_partition.prefix(必选参数)动态创建的分区名前缀。
-
dynamic_partition.buckets动态创建的分区所对应的分桶数量。
-
dynamic_partition.replication_num动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量。
-
dynamic_partition.start_day_of_week当
time_unit为WEEK时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点。 -
dynamic_partition.start_day_of_month当
time_unit为MONTH时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月 1 号,28 表示每月 28 号。默认为 1,即表示每月以 1 号为起始点。暂不支持以 29、30、31 号为起始日,以避免因闰年或闰月带来的歧义。 -
dynamic_partition.create_history_partition默认为 false。当置为 true 时,Doris 会自动创建所有分区,具体创建规则见下文。同时,FE 的参数
max_dynamic_partition_num会限制总分区数量,以避免一次性创建过多分区。当期望创建的分区个数大于max_dynamic_partition_num值时,操作将被禁止。当不指定
start属性时,该参数不生效。 -
dynamic_partition.history_partition_num当
create_history_partition为true时,该参数用于指定创建历史分区数量。默认值为 -1,即未设置。 -
dynamic_partition.hot_partition_num指定最新的多少个分区为热分区。对于热分区,系统会自动设置其
storage_medium参数为 SSD,并且设置storage_cooldown_time。注意:若存储路径下没有 SSD 磁盘路径,配置该参数会导致动态分区创建失败。
hot_partition_num是往前 n 天和未来所有分区我们举例说明。假设今天是 2021-05-20,按天分区,动态分区的属性设置为:hot_partition_num=2, end=3, start=-3。则系统会自动创建以下分区,并且设置
storage_medium和storage_cooldown_time参数:p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59 p20210518:["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59 p20210519:["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00 p20210520:["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00 p20210521:["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00 p20210522:["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00 p20210523:["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00 -
dynamic_partition.reserved_history_periods需要保留的历史分区的时间范围。当
dynamic_partition.time_unit设置为 "DAY/WEEK/MONTH/YEAR" 时,需要以[yyyy-MM-dd,yyyy-MM-dd],[...,...]格式进行设置。当dynamic_partition.time_unit设置为 "HOUR" 时,需要以[yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...]的格式来进行设置。如果不设置,默认为"NULL"。举例说明。假设今天是 2021-09-06,按天分类,动态分区的属性设置为:
time_unit="DAY/WEEK/MONTH/YEAR", end=3, start=-3, reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"。则系统会自动保留:
["2020-06-01","2020-06-20"], ["2020-10-31","2020-11-15"]或者
time_unit="HOUR", end=3, start=-3, reserved_history_periods="[2020-06-01 00:00:00,2020-06-01 03:00:00]".则系统会自动保留:
["2020-06-01 00:00:00","2020-06-01 03:00:00"]这两个时间段的分区。其中,
reserved_history_periods的每一个[...,...]是一对设置项,两者需要同时被设置,且第一个时间不能大于第二个时间。 -
dynamic_partition.storage_medium指定创建的动态分区的默认存储介质。默认是 HDD,可选择 SSD。
注意,当设置为 SSD 时,
hot_partition_num属性将不再生效,所有分区将默认为 SSD 存储介质并且冷却时间为 9999-12-31 23:59:59。
创建历史分区规则
当 create_history_partition 为 true,即开启创建历史分区功能时,Doris 会根据 dynamic_partition.start 和 dynamic_partition.history_partition_num 来决定创建历史分区的个数。
假设需要创建的历史分区数量为 expect_create_partition_num,根据不同的设置具体数量如下:
-
create_history_partition = true
dynamic_partition.history_partition_num 未设置,即 -1. expect_create_partition_num = end - start;
dynamic_partition.history_partition_num 已设置 expect_create_partition_num = end - max(start, -histoty_partition_num);
-
create_history_partition = false 不会创建历史分区,expect_create_partition_num = end - 0;
当 expect_create_partition_num 大于 max_dynamic_partition_num(默认 500)时,禁止创建过多分区。
举例说明:
假设今天是 2021-05-20,按天分区,动态分区的属性设置为,create_history_partition=true, end=3, start=-3,则会根据history_partition_num的设置,举例如下。
-
history_partition_num=1,则系统会自动创建以下分区:p20210519 p20210520 p20210521 p20210522 p20210523 -
history_partition_num=5,则系统会自动创建以下分区:p20210517 p20210518 p20210519 p20210520 p20210521 p20210522 p20210523 -
history_partition_num=-1即不设置历史分区数量,则系统会自动创建以下分区:p20210517 p20210518 p20210519 p20210520 p20210521 p20210522 p20210523
示例
- 表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近 7 天的分区,并且预先创建未来 3 天的分区。
CREATE TABLE tbl1
(
k1 DATE,
...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
假设当前日期为 2020-05-29。则根据以上规则,tbl1 会产生以下分区:
p20200529: ["2020-05-29", "2020-05-30")
p20200530: ["2020-05-30", "2020-05-31")
p20200531: ["2020-05-31", "2020-06-01")
p20200601: ["2020-06-01", "2020-06-02")
在第二天,即 2020-05-30,会创建新的分区 p20200602: ["2020-06-02", "2020-06-03")
在 2020-06-06 时,因为 dynamic_partition.start 设置为 7,则将删除 7 天前的分区,即删除分区 p20200529。
修改分区后可能遇到的冲突问题
通过如下命令可以修改动态分区的属性:
ALTER TABLE tbl1 SET
(
"dynamic_partition.prop1" = "value1",
...
);
某些属性的修改可能会产生冲突。假设之前分区粒度为 DAY,并且已经创建了如下分区:
p20200519: ["2020-05-19", "2020-05-20")
p20200520: ["2020-05-20", "2020-05-21")
p20200521: ["2020-05-21", "2020-05-22")
如果此时将分区粒度改为 MONTH,则系统会尝试创建范围为 ["2020-05-01", "2020-06-01") 的分区,而该分区的分区范围和已有分区冲突,所以无法创建。而范围为 ["2020-06-01", "2020-07-01") 的分区可以正常创建。因此,2020-05-22 到 2020-05-30 时间段的分区,需要自行填补。
此时这中间缺失的分区如果不创建,那么原本属于这部分分区的数据将会缺失、或是入不到表中。
分桶
如果使用了分区,则 DISTRIBUTED ... 语句描述的是数据在各个分区内的划分规则。
如果不使用分区,则描述的是对整个表的数据的划分规则。
分桶列可以是多列,Aggregate 和 Unique 模型必须为 Key 列,Duplicate 模型可以是 key 列和 value 列。分桶列可以和 Partition 列相同或不同。
分桶在物理层面即数据分片(Tablet)。在数据表完成分区后,指定部分列作为分桶列,将这些列数据中相同哈希值的数据合到一起,形成了 Tablet。一个表中 Tablet 总数量 = 分区数(Partition num)x 分桶数(Bucket num)x 数据副本数(Replication_num) 。
- 单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
- 当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
- 在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(
ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。 - 一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
- 举一些例子:假设在有 10 台 BE,每台 BE 一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑 4-8 个分片。5GB:8-16 个分片。50GB:32 个分片。500GB:建议分区,每个分区大小在 50GB 左右,每个分区 16-32 个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区 16-32 个分片。
提示
表的数据量可以通过
SHOW DATA命令查看,结果除以副本数,即表的数据量。
自动分桶
用户经常设置不合适的 bucket,导致各种问题,这里提供一种方式,来自动设置分桶数。当前只对 OLAP 表生效。
警告
注意:这个功能在被 CCR 同步时将会失效。如果这个表是被 CCR 复制而来的,即 PROPERTIES 中包含is_being_synced = true时,在show create table中会显示开启状态,但不会实际生效。当is_being_synced被设置为 false 时,这些功能将会恢复生效,但is_being_synced属性仅供 CCR 外围模块使用,在 CCR 同步的过程中不要手动设置。
以往创建分桶时需要手动设定分桶数,而自动分桶推算功能是 Apache Doris 可以动态地推算分桶个数,使得分桶数始终保持在一个合适范围内,让用户不再操心桶数的细枝末节。首先说明一点,为了方便阐述该功能,该部分会将桶拆分为两个时期的桶,即初始分桶以及后续分桶;这里的初始和后续只是本文为了描述清楚该功能而采用的术语,Apache Doris 分桶本身没有初始和后续之分。从上文中创建分桶一节我们知道,BUCKET_DESC 非常简单,但是需要指定分桶个数;而在自动分桶推算功能上,BUCKET_DESC 的语法直接将分桶数改成"Auto",并新增一个 Properties 配置即可:
-- 旧版本指定分桶个数的创建语法
DISTRIBUTED BY HASH(site) BUCKETS 20
-- 新版本使用自动分桶推算的创建语法
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "2G")
新增的配置参数 estimate_partition_size 表示一个单分区的数据量。该参数是可选的,如果没有给出则 Doris 会将 estimate_partition_size 的默认值取为 10GB。从上文中已经得知,一个分桶在物理层面就是一个 Tablet,为了获得最好的性能,建议 Tablet 的大小在 1GB - 10GB 的范围内。
那么自动分桶推算是如何保证 Tablet 大小处于这个范围内的呢?
- 若是整体数据量较小,则分桶数不要设置过多
- 若是整体数据量较大,则应使桶数跟总的磁盘块数相关,充分利用每台 BE 机器和每块磁盘的能力
提示
estimate_partition_size 属性不支持 alter 操作
物化视图
在2.1版本的doris中,已经支持了多表join的物化视图,官方命名为异步物化视图,与之相反的为同步物化视图。
物化视图与视图的差异就是是否数据落地磁盘,物化视图是以空间换时间的思路,将物化视图的数据自动更新写道磁盘中,避免了查询的时候计算。
关于物化视图官网
注意事项
- 如果删除语句的条件列,在物化视图中不存在,则不能进行删除操作。如果一定要删除数据,则需要先将物化视图删除,然后方可删除数据。
- 单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 Base 表数据是同步更新的,如果一张表的物化视图表超过 10 张,则有可能导致导入速度很慢。这就像单次导入需要同时导入 10 张表数据是一样的。
- 物化视图针对 Unique Key 数据模型,只能改变列顺序,不能起到聚合的作用,所以在 Unique Key 模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作
- 目前一些优化器对 sql 的改写行为可能会导致物化视图无法被命中,例如 k1+1-1 被改写成 k1,between 被改写成<=和>=,day 被改写成dayofmonth,遇到这种情况需要手动调整下查询和物化视图的语句。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号