
ES索引数据迁移、分片数优化(reindex)
ES索引数据迁移、分片数优化(reindex)
Elasticsearch是⼀个实时的分布式搜索引擎,为⽤户提供搜索服务。当我们创建好一个索引时,内部的mapping是无法更改的,当业务发生变化,或是当初规划错误导致每个分片数据量过大(网上建议单个分片最大50G)就会影响数据的查询效率,这时候就要重新创建索引,进行数据的迁移了。
业务背景
当初公司人员对ES还不太了解,创建索引时随意设置,导致有些索引分片设置的极其不合理,旱的旱死,涝的涝死,如下两图:
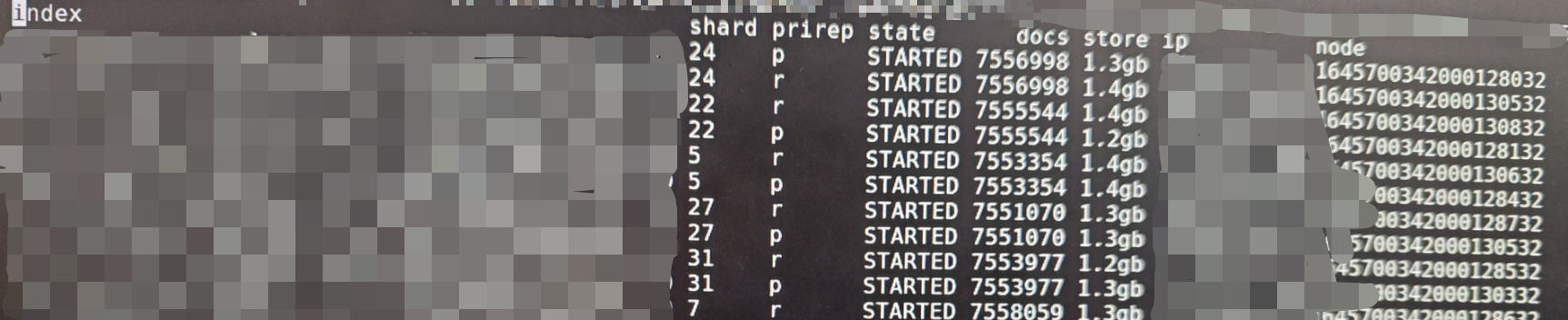
总共35个分片,平均一个分片存储1.3gb大小数据
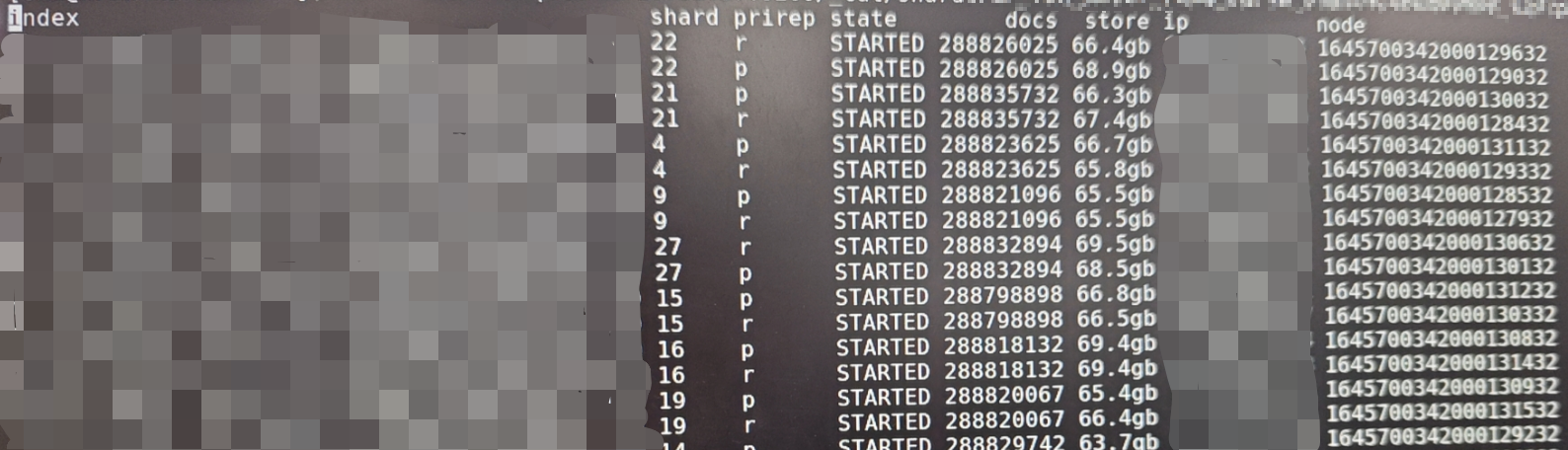
总共30个分片,平均一个分片存储66gb大小数据
ES的分片数量可以理解为与HDFS的小文件数,如果ES分片数过多会增大整个ES集群的压力,如果单个分片存储的数据过大,又会影响查询效率
步骤
假设原索引名为my_index,更新为reindex_my_index新索引
- 新增一个索引
redinex_my_index,Mapping看需求选择是否更原来my_index一样(这里一样) - 通过官方
_reindex方法将my_index同步至redinex_my_index里 - 校验同步结果,确保两个索引的分片数一致
- 删除
my_index索引 - 给
redinex_my_index索引起一个别名,就叫my_index - 为
redinex_my_index索引创建对应my_index索引的metric
新建索引
这边只是想缓解一下集群的压力,进行分片数合并,因此Mapping将保持原来的一样。
- 获取原索引的body
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/$index | jq '."'$index'"' | jq 'del(.settings.index.creation_date,.settings.index.uuid,.settings.index.version,.settings.index.provided_name,.aliases)' | jq '.settings.index.number_of_shards='$shardNum''
通过
GET请求获取原索引的结构,再通过jq(一种json数据处理工具,可以查一下具体的语法)筛选出对应索引名'."'$index'"'下的json数据,由于后面要创建相同的索引,有些结构数据用不到,索引后面通过jq的del()删除了一些索引结构数据,最后通过jq对里面的分片数进行更改,进而创建出了新的索引
- 创建索引
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT "$ES_URL/$newIndexName -d '$newIndexBody'"
将原索引数据复制到新索引中
在同步时,先开启索引只读权限,防止数据在同步的过程中,原索引进行写入、删除操作,导致同步异常的事情发生
- 原索引开启只读
curl -u $USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT $ES_URL/$index/_setting -d'{"index.blocks.read_only_allow_delete":true}'
关于ES内的数据同步,官方是给出了_reindex方法的。
参数:
source:原信息,index为原索引名
dest:目标信息,index为新索引名
- 同步等待
curl -u $USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_reindex -d'{"source": {"size": '$SIZE', "index": "'$index'"}, "dest": {"index": "'$newIndexName'"} }'
size参数是每秒批处理多少条数据,官方默认是1000条。上面的是同步等待,意思是只能等待上面的执行完,才能继续同步其他的索引,如果想实现异步同步,需关闭
wait_for_completion参数。
- 异步同步
curl -u $USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_reindex?wait_for_completion=false -d'{"source": {"size": '$SIZE', "index": "'$index'"}, "dest": {"index": "'$newIndexName'"} }'
请求成功后,会返回相应的TaskID,通过这个ID就可以随时查看运行进度
{"task":"AzDO4-XThyZ_fe8VdpAgw:364135143"}
- 查看异步同步结果
curl -u $USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_tasks/$TaskID
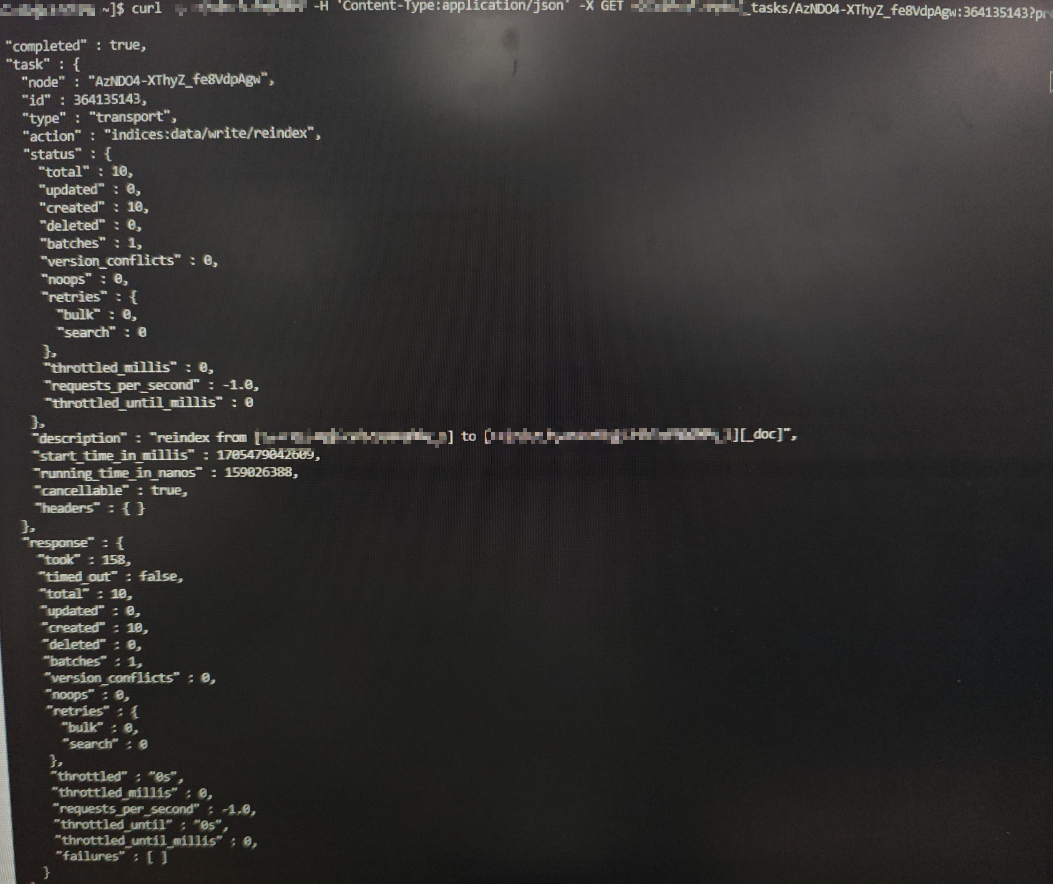
通过completed为true判断reindex任务已结束
通过response.time.out为false判断reindex任务已完成
通过对比response.total和response.created判断数据是否全部复制到新索引中
校验结果
查看原索引数量:
curl -u $USER_NAME:$PASSWORD -X GET $ES_URL/_cat/count/$index?v
查看新索引数量:
curl -u $USER_NAME:$PASSWORD -X GET $ES_URL/_cat/count/$newIndexName?v
对比两个量级是否一致
删除原索引
当文档数量一致后,就可以删除原索引了
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X DELETE $ES_URL/$index
给新索引起别名
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_aliases -d'{"actions" : [{ "add" : { "index" : "'$newIndexName'", "alias" : "'$index'" } } ] }'
创建新索引的metric
该步骤用于触发新索引的数据清理功能,同名的Metric无需重复创建
先获取原索引的metric
oldMetricName=$(echo $index | cut -d "@" -f 1)
newMetricBody=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_metric/$oldMetricName |jq '.result' | jq '."'$oldMetricName'"')
创建新的meteric
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT $ES_URL/_metric/$newMetricName -d "'$newMetricBody'"
至此,整个ES索引数据迁移、分片优化(reindex)完成了
脚本整合
#!/bin/bash
#新index的名称前缀
REINDEX_PREFIX='reindex_'
#实例ip和端口
ES_URL='your_ip:your_post'
#实例用户名称
USER_NAME='your_username'
#实例用户名称对应的密码
PASSWORD='your_password'
#批处理大小,reindex较慢时可适当调大
SIZE=5000
INDEX_1=$1
# 如果输入的索引名的长度为0
if [ -z "$INDEX_1" ]; then
##查询出分片数大于指定值的索引-------------------------------------------------------------------获取分片数大于30的索引名----
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_cat/indices | awk '$5 > 30 {print $3}' | awk '!seen[$1]++' | cut -d ' ' -f 1 >./waitForMergeIndex.txt
echo "***********Start to Execute Reindex Task...************"
while IFS= read -r index; do
## 使用 </dev/tty 对read的输入源进行重定向,限定只能通过当前的终端输入,其下面还有tty0、tty1...tty...,代表着第一个终端虚拟机、第二个终端虚拟机、...、第n个终端虚拟机
read -p "请确认是否要修改索引:$index 的分片数?请输入y或n:" -r confirmReindex </dev/tty
if [ "$confirmReindex" = "n" ]; then
continue
fi
echo "开始更新索引分片等配置信息,当前索引名称:$index"
read -p "请输入新分片数:" -r shardNum </dev/tty
#read -p "请输入新refresh_interval:" -r refreshInterval < /dev/tty
#read -p "请输入新副本数:" -r replicas < /dev/tty
##查询表结构
##newIndexBody=`curl -H 'Content-Type:application/json' -X GET $ES_URL/$index | jq '."'$index'"' |jq 'del(.settings.index.creation_date,.settings.index.uuid,.settings.index.version,.settings.index.provided_name,.aliases)' |jq '.settings.index.number_of_shards='$shardNum'' |jq '.settings.index.number_of_replicas='$replicas'' |jq '.settings.index.refresh_interval='"$refreshInterval"''`
## 通过get索引获取原索引的结构,再通过jq(一种json数据处理工具,可以查一下具体的语法)筛选出对应索引名 `'."'$index'"'` 下的json数据,由于后面要创建相同的索引,有些结构数据用不到,索引后面通过jq del()删除了一些索引结构数据,最后通过jq对里面的分片数进行更改,进而创建出了新的索引
newIndexBody=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/$index | jq '."'$index'"' | jq 'del(.settings.index.creation_date,.settings.index.uuid,.settings.index.version,.settings.index.provided_name,.aliases)' | jq '.settings.index.number_of_shards='$shardNum'')
#echo $newIndexBody
echo "开始执行reindex..."
##创建新表 -- 表名
newIndexName+=$REINDEX_PREFIX$index
echo "创建新表:$newIndexName"
## 建表语句,将建表语句赋值给req变量
req+="curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT $ES_URL/$newIndexName -d '$newIndexBody'"
#echo $req
## 将字符串转换成可执行的语句
reqEval=$(echo -e $req)
#echo $reqEval
## eval动态执行,有点像scala、python中的惰性函数
eval $reqEval
echo -e "\n"
##执行reindex迁移
echo "开始执行reindex,对于较大的索引耗时可能较长,可通过命令监控或者取消reindex任务,监控reindex:curl -u root:le201909 -H 'Content-Type:application/json' -X GET 172.xx.xx.4:9201/_tasks/AnNKL9xwR_iXHvGViMwELw:9476639 取消reindex:curl -u root:le201909 -H 'Content-Type:application/json' -X POST 172.xx.xx.4:9201/_tasks/AnNKL9xwR_iXHvGViMwELw:9476639/_cancel"
reindexBody+='{"source": {"size": '$SIZE', "index": "'$index'"}, "dest": {"index": "'$newIndexName'"} }'
# 如果 reindex 时间过长,建议加上 wait_for_completion=false 的参数条件,这样 reindex 将直接返回 taskId,任务在后台运行。
reindexReq="curl -u $USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_reindex?wait_for_completion=false -d'$reindexBody' | jq '.task' | tr -d '\"'"
#echo -e "\nreindex命令执行返回为:"
#echo $reindexReq
reindexReqEval=$(echo -e $reindexReq)
#echo $reindexReqEval
echo -e "\nreindex命令执行返回为:"
taskId=$(eval $reindexReqEval)
echo "reindex任务ID:$taskId"
echo -e "\n"
##循环查询任务执行结果,执行结束后继续其他流程
taskComplete=0
while [ $taskComplete -eq 0 ]; do
taskResult=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_tasks/$taskId | jq '.completed')
echo "任务是否已完成:$taskResult"
if [ "$taskResult" == "true" ]; then
taskComplete=1
fi
sleep 1s
done
echo "Reindex任务已执行完毕,请继续确认以下步骤。"
##删除旧索引
read -p "请再次确认是否要删除该索引:$index ,输入y确认删除,n为不删除,若不执行删除,需要手动创建别名和删除索引才能完成分片调整流程: " -r confirmDel </dev/tty
if [ "$confirmDel" = "y" ]; then
echo "正在删除旧索引:$index"
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X DELETE $ES_URL/$index
echo -e "\n"
fi
##创建别名
echo "为新表创建别名..."
aliases+='{"actions" : [{ "add" : { "index" : "'$newIndexName'", "alias" : "'$index'" } } ] }'
aliasesReq+="curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_aliases -d'$aliases'"
aliasesReqEval=$(echo -e $aliasesReq)
echo $aliasesReqEval
eval $aliasesReqEval
echo -e "\n"
##创建reindex后的metric
echo "为reindex生成的子表创建对应的metric..."
oldMetricName=$(echo $index | cut -d "@" -f 1)
newMetricName=$REINDEX_PREFIX$oldMetricName
newMetricBody=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_metric/$oldMetricName |jq '.result' | jq '."'$oldMetricName'"')
metricReq+="curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT $ES_URL/_metric/$newMetricName -d '$newMetricBody'"
metricReqEval=$(echo -e $metricReq)
eval $metricReqEval
echo -e "\n"
echo "索引:$index 分片调整结束。"
req=''
reindexBody=''
reindexReq=''
newIndexName=''
aliases=''
aliasesReq=''
newMetricName=''
newMetricBody=''
metricReq=''
metricReqEval=''
oldMetricName=''
echo -e "\n"
echo -e "\n"
done <"./waitForMergeIndex.txt"
else
read -p "请确认是否要修改索引:$INDEX_1 的分片数?请输入y或n:" -r confirmReindex </dev/tty
if [ "$confirmReindex" = "n" ]; then
exit 0
fi
echo "开始更新索引分片等配置信息,当前索引名称:$INDEX_1"
read -p "请输入新分片数:" -r shardNum </dev/tty
#read -p "请输入新refresh_interval:" -r refreshInterval < /dev/tty
#read -p "请输入新副本数:" -r replicas < /dev/tty
##查询表结构
##newIndexBody=`curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/$INDEX_1 | jq '."'$INDEX_1'"' |jq 'del(.settings.index.creation_date,.settings.index.uuid,.settings.index.version,.settings.index.provided_name,.aliases)' |jq '.settings.index.number_of_shards='$shardNum'' |jq '.settings.index.number_of_replicas='$replicas'' |jq '.settings.index.refresh_interval='"$refreshInterval"''`
newIndexBody=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/$INDEX_1 | jq '."'$INDEX_1'"' | jq 'del(.settings.index.creation_date,.settings.index.uuid,.settings.index.version,.settings.index.provided_name,.aliases)' | jq '.settings.index.number_of_shards='$shardNum'')
#echo $newIndexBody
echo "开始执行reindex..."
##创建新表-即新的索引名,$REINDEX_PREFIX为事先设置好的索引前缀名
newIndexName+=$REINDEX_PREFIX$INDEX_1
echo "创建新表:$newIndexName"
# 该语句类似:create table newIndexName as select * from newIndexBody
req+="curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT $ES_URL/$newIndexName -d '$newIndexBody'"
reqEval=$(echo -e $req)
#echo $reqEval
# 执行语句
eval $reqEval
echo -e "\n"
##执行reindex迁移
echo "开始执行reindex,对于较大的索引耗时可能较长,可通过命令监控或者取消reindex任务,监控reindex:curl -u root:le201909 -H 'Content-Type:application/json' -X GET 172.xx.xx.4:9201/_tasks/AnNKL9xwR_iXHvGViMwELw:9476639 取消reindex:curl -u root:le201909 -H 'Content-Type:application/json' -X POST 172.xx.xx.4:9201/_tasks/AnNKL9xwR_iXHvGViMwELw:9476639/_cancel"
reindexBody+='{"source": {"size": '$SIZE', "index": "'$INDEX_1'"}, "dest": {"index": "'$newIndexName'"} }'
reindexReq="curl -u $USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_reindex?wait_for_completion=false -d'$reindexBody' | jq '.task' | tr -d '\"'"
#echo -e "\nreindex命令执行返回为:"
echo $reindexReq
reindexReqEval=$(echo -e $reindexReq)
echo $reindexReqEval
echo -e "\nreindex命令执行返回为:"
taskId=$(eval $reindexReqEval)
echo "reindex任务ID:$taskId"
echo -e "\n"
##循环查询任务执行结果,执行结束后继续其他流程
taskComplete=0
while [ $taskComplete -eq 0 ]; do
taskResult=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_tasks/$taskId | jq '.completed')
echo "任务是否已完成:$taskResult"
if [ "$taskResult" == "true" ]; then
taskComplete=1
fi
sleep 1s
done
echo "Reindex任务已执行完毕,请继续确认以下步骤。"
##删除旧索引
read -p "请再次确认是否要删除该索引:$INDEX_1 ,输入y确认删除,n为不删除,若不执行删除,需要手动创建别名和删除索引才能完成分片调整流程: " -r confirmDel </dev/tty
if [ "$confirmDel" = "y" ]; then
echo "正在删除旧索引:$INDEX_1"
curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X DELETE $ES_URL/$INDEX_1
echo -e "\n"
fi
##创建别名
echo "为新表创建别名..."
aliases+='{"actions" : [{ "add" : { "index" : "'$newIndexName'", "alias" : "'$INDEX_1'" } } ] }'
aliasesReq+="curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X POST $ES_URL/_aliases -d'$aliases'"
aliasesReqEval=$(echo -e $aliasesReq)
echo $aliasesReqEval
eval $aliasesReqEval
echo -e "\n"
##创建reindex后的metric
echo "为reindex生成的子表创建对应的metric..."
oldMetricName=$(echo $INDEX_1 | cut -d "@" -f 1)
newMetricName=$REINDEX_PREFIX$oldMetricName
newMetricBody=$(curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X GET $ES_URL/_metric/$oldMetricName |jq '.result' | jq '."'$oldMetricName'"')
metricReq+="curl -u$USER_NAME:$PASSWORD -H 'Content-Type:application/json' -X PUT $ES_URL/_metric/$newMetricName -d '$newMetricBody'"
metricReqEval=$(echo -e $metricReq)
eval $metricReqEval
echo -e "\n"
echo "索引:$INDEX_1 分片调整结束。"
req=''
reindexBody=''
reindexReq=''
newIndexName=''
aliases=''
aliasesReq=''
echo -e "\n"
echo -e "\n"
fi
echo "***********Reindex Task End...************"
使用感受
这种方法效率极其低下,当数据量大于40g时(大概4亿多条数据),要等上1天的时间,期间如果遇上网络波动、集群压力过大都会造成同步的失败。单批次数据量过大的时,还会增大集群的压力。
求大神推荐新方法!!!(由于效率极其地下,这边对一些数据不常用,随时间变化影响大的数据设置了TTL,缩减了数据过期时间以及增大了滚动周期,以此来缓解分片数的增长)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号